github-> https://github.com/foolishkylin/WordCount
WordCount
项目需求
WordCount是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。WordCount须有清晰直观的GUI界面。
规则是:
空行:本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
代码行:本行包括多于一个字符的代码。
注释行:本行不是代码行,并且本行包括注释。一个有趣的例子是有些程序员会在单字符后面加注释:} //注释
在这种情况下,这一行属于注释行。
对于一个或多个文件,须统计*.c 文件的代码行数、空行数、注释行数。
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 4 |
| · Estimate | · 估计这个任务需要多少 | 5 | 4 |
| Development | 开发 | 465 | 432 |
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 16 |
| · Design Spec | · 生成设计文档 | 20 | 12 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 2 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 2 |
| · Design | · 具体设计 | 20 | 30 |
| · Coding | · 具体编码 | 300 | 330 |
| · Code Review | · 代码复审 | 30 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 30 |
| Reporting | 报告 | 100 | 56 |
| · Test Report | · 测试报告 | 20 | 16 |
| · Size Measurement | · 计算工作量 | 20 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 570 | 492 |
需求分析
-
开发技术需求:
名称 描述 python 基础开发 完成软件的逻辑部分 python GUI开发 完成软件的图形化部分 python 打安装包 将软件打包成安装包 单元测试 进行软件的单元测试 -
项目功能需求:
| 名称 | 描述 | 备注 |
|---|---|---|
| 统计单文件特征 | 统计单个文件的字符数、单词数、行数(代码行、空行、注释行) | 应包含统计用时 |
| 统计多个文件 | 统计统一目录下的所有文件特征 | 文件格式应有要求 |
解题思路
拿到项目要求后,首先分析需求。WC的核心逻辑需求是统计文件的各项特征,统计特征不难,可能难的是文件io,需求里以.c文件为例,但后续可以拓展到其他源文件。其次的前端需求是做控制台传参或者GUI操作,笔者选择了后者。
对于逻辑需求,需要去学习文件的io操作、统计特征。
对于前端需求,需要学习python的GUI开发
但完成前两部分还不够,我们需要对项目进行回归测试,笔者预备在项目在初步开发后进行。
设计思路
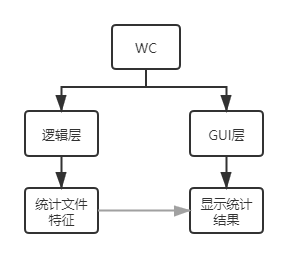
具体首先将分成两层,逻辑层和GUI层。逻辑层负责实现项目的核心逻辑,GUI层负责实现项目的GUI界面。
大致实现思路是先完成逻辑层,再实现GUI层。
先按照功能实现逻辑层的两个函数:单文件统计和多文件统计,其中多文件统计类同于单文件统计循环调用。
再实现GUI层的基本ui,然后在此基础上通过信号槽来与逻辑层相连。
代码说明
下面给出单c/c++源文件的统计函数
def count_single_file(file_path):
"""
:param file_path:
:return:
"""
text = '文件: ' + file_path + '
'
start = time.perf_counter() # 开始计时
fr = open(file_path)
ltext = fr.readlines() # 读文件
dcount = {
'cchar': 0,
'cword': 0,
'cline': len(ltext),
'cempty_line': 0,
'ccode_line': 0,
'ccomment_line': 0,
'cost_time':0.0
} # 初始化统计字典
comment_block = False # 设置验证/**/的布尔值
for line in ltext:
# 开始统计
dcount['cchar'] += len(line) # 统计字符数
dcount['cword'] += len(line.split(' ')) # 统计单词数
if len(line.strip('
')) <= 1:
# check empty line
dcount['cempty_line'] += 1 # 是否为空行
continue
code_check1 = line.split('//')[0]
code_check2 = line.split('/*')[0]
if len(code_check1.strip('
')) > 1 or len(code_check2.strip('
')) > 1:
# check code line
dcount['ccode_line'] += 1 # 是否为代码行
continue
# check comment line
if line.find('//') != -1:
dcount['ccomment_line'] += 1 # 是否为//类注释
continue
if line.find('/*') != -1:
comment_block = True # 是否为/**/类注释
if comment_block:
# check "**"
dcount['ccomment_line'] += 1
if line.find('*/') != -1:
comment_block = False # 是否/**/注释结束
dcount['cost_time'] = time.perf_counter() - start # 计时结束
zh_names = ['字符数', '单词数', '总行数', '空行数', '代码行数', '注释行数', '耗时']
en_names = ['cchar', 'cword', 'cline', 'cempty_line', 'ccode_line', 'ccomment_line', 'cost_time']
for it in range(len(zh_names)):
# 生成结果文本
text += (zh_names[it] + ': ' + str(dcount[en_names[it]]))
if it != len(zh_names) - 1:
text += '
'
else:
text += 's
'
return text, dcount['cost_time']
以上代码在GUI中的输出如下:
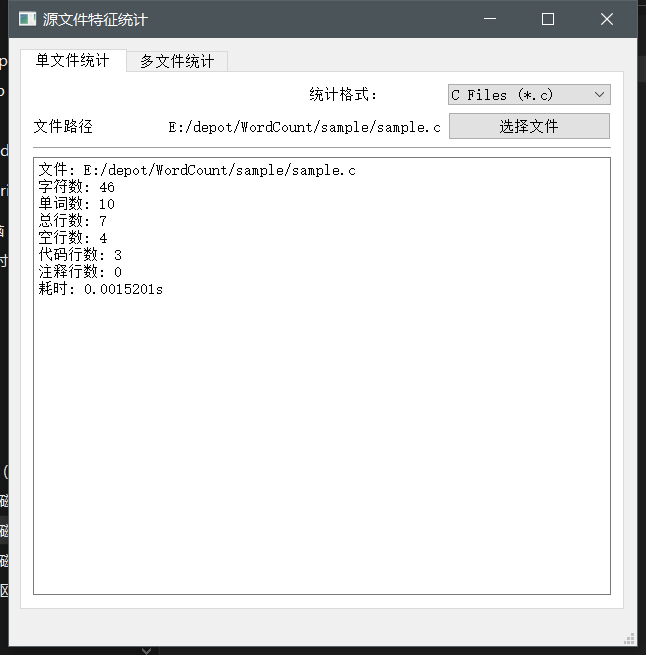
测试运行
-
回归测试
在本项目中,笔者构建了对同一目录下的同类文件进行统计的功能,以此我们可以进行批量的回归测试。测试结果如下:
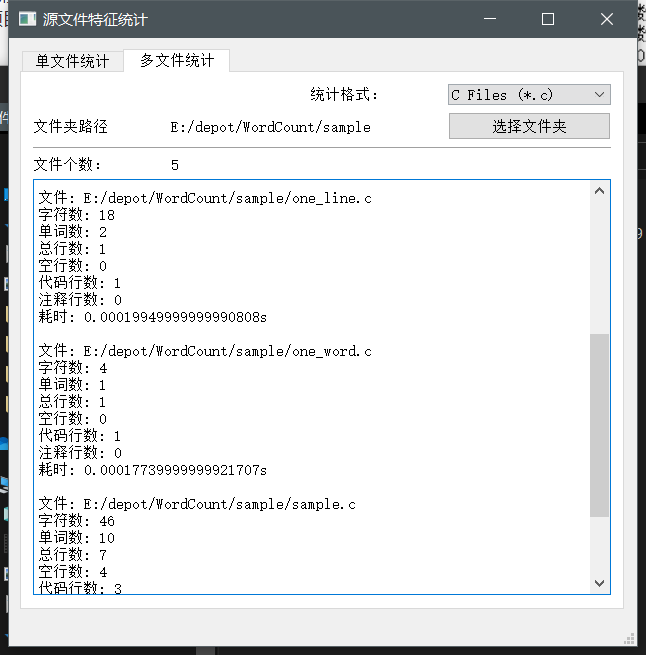
统计结果:
文件: E:/depot/WordCount/sample/one_line.c
字符数: 18
单词数: 2
总行数: 1
空行数: 0
代码行数: 1
注释行数: 0
耗时: 0.00019949999999990808s
文件: E:/depot/WordCount/sample/one_word.c
字符数: 4
单词数: 1
总行数: 1
空行数: 0
代码行数: 1
注释行数: 0
耗时: 0.00017739999999921707s
文件: E:/depot/WordCount/sample/sample.c
字符数: 46
单词数: 10
总行数: 7
空行数: 4
代码行数: 3
注释行数: 0
耗时: 0.00016929999999959477s
-----------------------------------------
总耗时: 0.0009594999999995579s
由上述可知,初步的回归测试是成功的。
-
标准测试集测试
类似地,笔者使用了多文件统计的功能,对一系列c++文件(来源于笔者之前写过的代码)进行统计。结果如下
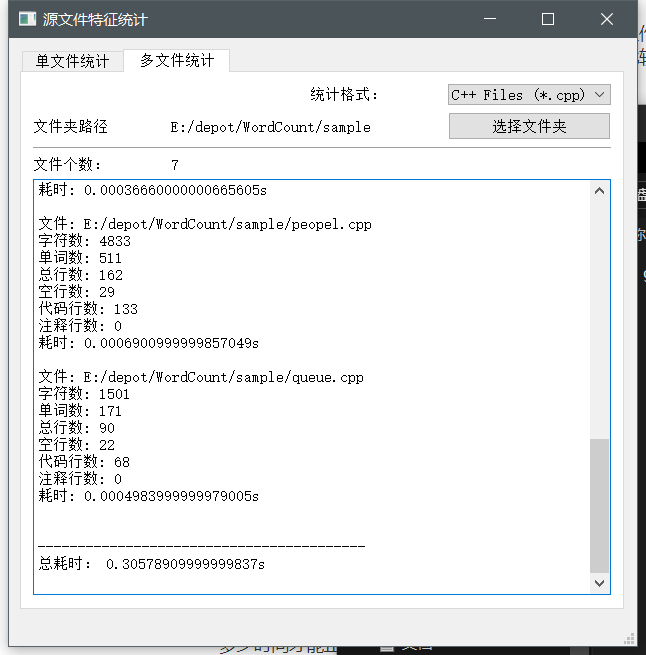
统计结果:
文件: E:/depot/WordCount/sample/basis.cpp
字符数: 4212
单词数: 489
总行数: 237
空行数: 64
代码行数: 173
注释行数: 0
耗时: 0.3017877999999996s
文件: E:/depot/WordCount/sample/clock.cpp
字符数: 262
单词数: 26
总行数: 14
空行数: 4
代码行数: 10
注释行数: 0
耗时: 0.00027199999999538704s
文件: E:/depot/WordCount/sample/elevator.cpp
字符数: 19430
单词数: 2019
总行数: 668
空行数: 62
代码行数: 606
注释行数: 0
耗时: 0.0016401000000030308s
文件: E:/depot/WordCount/sample/list.cpp
字符数: 2083
单词数: 247
总行数: 110
空行数: 21
代码行数: 89
注释行数: 0
耗时: 0.0005341000000100848s
文件: E:/depot/WordCount/sample/main.cpp
字符数: 56
单词数: 10
总行数: 7
空行数: 3
代码行数: 4
注释行数: 0
耗时: 0.00036660000000665605s
文件: E:/depot/WordCount/sample/peopel.cpp
字符数: 4833
单词数: 511
总行数: 162
空行数: 29
代码行数: 133
注释行数: 0
耗时: 0.0006900999999857049s
文件: E:/depot/WordCount/sample/queue.cpp
字符数: 1501
单词数: 171
总行数: 90
空行数: 22
代码行数: 68
注释行数: 0
耗时: 0.0004983999999979005s
-----------------------------------------
总耗时: 0.30578909999999837s
拓展需求
在本项目中,笔者设计了多种源代码统计格式(目前有c和c++,后续可以拓展),以此来对不同文件的注释进行统计。
项目小结
综合PSP表来看,大体上都在预期时间内完成,但是仍有一些意外。在实现好各项功能后,笔者在打包程序这里遇到了一些难题,通过github的pr找到了可能的原因:打包环境内部的版本可能不兼容。后来通过新建一个虚拟环境解决。
这也给了我一个教训,在实现前,要确认好环境的配置问题,确保不会卡在这里。
另:笔者在github项目的dist下上传了可执行文件,有兴趣的读者可以去下载试试。
程序使用说明
对于单文件统计,先选择统计格式,在选择文件。选择好后即进行统计。
对于多文件统计,同样选择统计格式。然后选择文件夹路径,选择好后即开始统计文件。