提纲挈领
https://blog.csdn.net/linolzhang/article/details/54344350
SPP
https://www.cnblogs.com/gongxijun/p/7172134.html
我们使用三层的金字塔池化层pooling,分别设置图片切分成多少块,论文中设置的分别是(1,4,16),然后按照层次对这个特征图feature A进行分别处理(用代码实现就是for(1,2,3层)):
第一层对这个特征图feature A整个特征图进行池化(池化又分为:最大池化,平均池化,随机池化),论文中使用的是最大池化,得到1个特征。
第二层先将这个特征图feature A切分为4个(20,30)的小的特征图,然后使用对应的大小的池化核对其进行池化得到4个特征,
第三层先将这个特征图feature A切分为16个(10,15)的小的特征图,然后使用对应大小的池化核对其进行池化得到16个特征.
然后将这1+4+16=21个特征输入到全连接层,进行权重计算. 当然了,这个层数是可以随意设定的,以及这个图片划分也是可以随意的,只要效果好同时最后能组合成我们需要的特征个数即可
http://makaidong.com/u011974639/1/938094_10121062_2.htm 映射
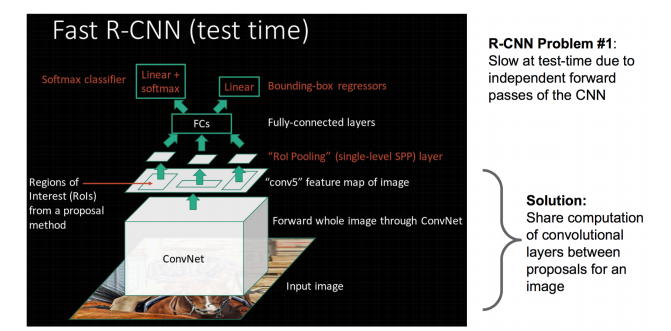
fast rcnn
https://blog.csdn.net/shenxiaolu1984/article/details/51036677
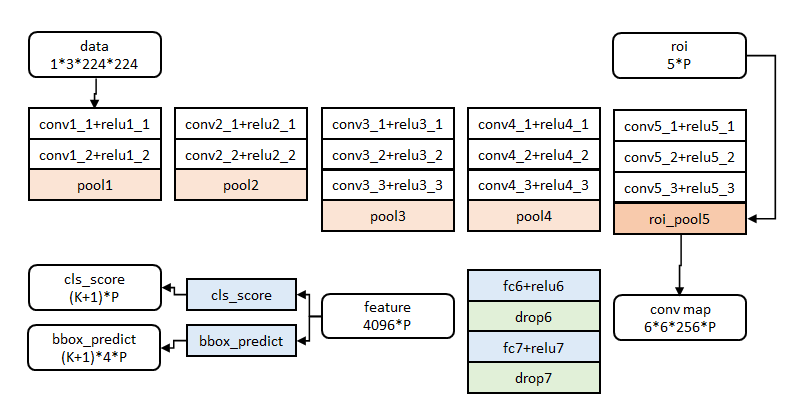
前五阶段是基础的conv+relu+pooling形式,在第五阶段结尾,输入P个候选区域(图像序号×1+几何位置×4,序号用于训练)
roi_pool层将每个候选区域均匀分成M×N块,对每块进行max pooling。
全连接层提速:在实现时,相当于把一个全连接层拆分成两个,中间以一个低维数据相连。
cls_score层用于分类,输出K+1维数组p,表示属于K类和背景的概率。
bbox_predict层用于调整候选区域位置,输出4*K维数组t,表示分别属于K类时,应该平移缩放的参数。
roi pooling:
https://blog.deepsense.ai/region-of-interest-pooling-explained/
RPN
https://blog.csdn.net/u013010889/article/details/78574879
--->
proposal对RPNchase的anchor进行处理,用到nms
上一步得到了很多大小不一的roi,对应到feature map上也是大小不一的,但是fc是需要fixed size的,于是需要使用roi pooling
数据层
- 主要利用工厂模式适配各种数据集 factory.py中利用lambda表达式(泛函)
- 自定义适配自己数据集的类,继承于imdb
- 主要针对数据集中生成roidb,对于每个图片保持其中含有的所有的box坐标(0-index)及其类别,然后顺便保存它的面积等参数,最后记录所有图片的index及其根据index获取绝对地址的方法
https://blog.csdn.net/sloanqin/article/details/51545125
---》
这个1*1*256*18的卷积核就是大家平常理解的全连接;所以全连接只是卷积操作的一种特殊情况(当卷积核的大小与图片大小相同的时候,其实所谓的卷积就是全连接了)
https://blog.csdn.net/mllearnertj/article/details/53709766
---》
一个分支进行针对feature map(上图conv-5-3共有512个feature-map)的每一个位置预测共(9*4=36)个参数,其中9代表的是每一个位置预设的9种形状的anchor-box,4对应的是每一个anchor-box的预测值(该预测值表示的是预设anchor-box到ground-truth-box之间的变换参数),上图中指向rpn-bbox-pred层的箭头上面的数字36即是代表了上述的36个参数,所以rpn-bbox-pred层的feature-map数量是36。
另一分支预测该anchor-box所框定的区域属于前景和背景的概率(网上很对博客说的是,指代该点属于前景背景的概率,那样是不对的,不然怎么会有18个feature-map输出呢?否则2个就足够了),前景背景的真值给定是根据当前像素(anchor-box中心)是否在ground-truth-box内。
要注意的是RPN内部有两个loss层,一个是BBox的loss,该loss通过减小ground-truth-box与预测的anchor-box之间的差异来进行参数学习,从而使RPN网络中的权重能够学习到预测box的能力。实现细节是每一个位置的anchor-box与ground-truth里面的box进行比较,选择IOU最大的一个作为该anchor-box的真值,若没有,则将之class设为背景(概率值0,否则1),这样背景的anchor-box的损失函数中每个box乘以其class的概率后就不会对bbox的损失函数造成影响。另一个loss是class-loss,该处的loss是指代的前景背景并不是实际的框中物体类别,它的存在可以使得在最后生成roi时能快速过滤掉预测值是背景的box。也可实现bbox的预测函数不受影响,使得anchor-box能(专注于)正确的学习前景框的预测,正如前所述。所以,综合来讲,整个RPN的作用就是替代了以前的selective-search方法,因为网络内的运算都是可GPU加速的,所以一下子提升了ROI生成的速度。可以将RPN理解为一个预测前景背景,并将前景框定的一个网络,并进行单独的训练。
https://www.cnblogs.com/573177885qq/p/6068854.html
RPN网络(Region Proposal Network)与目标检测网络共享卷积层,大大减少了计算proposals的时间。
RPN可以看作是fully-convolutional network (FCN),对于生成detecting proposals这种任务,是end-to-end的。为了使RPN和fast r-cnn相统一,我们提出了一个简单的训练框架,在region proposal task和object detection的微调中依次交替(保持proposals固定)。设计RPN,利用卷积特征图生成region proposals(而不是selective search等),提升了速度;训练RPN和fast r-cnn(检测网络)共享卷积层,提高检测速度。
第2步得到的高维特征图和第3步得到的region proposals同时输入RoI池化层,提取对应region proposals的特征。
RPN的输入为一张图像,输出为一系列的矩形框(proposals),每一个会带有objectness score。本文使用fcn模型来处理这个过程。因为我们的目标是与fast r-cnn的检测网络共享计算,因此我们假设这些网络共享卷积层。
RPN在CNN输入特征图后,增加滑动窗口操作以及两个卷积层完成region proposals。其中第一个卷积层将特征图的每个滑窗位置编码成一个特征向量~3*3的window,使用3*3*256*256的四维卷积核--》256维的向量,即这里的特征向量;第二个卷积层对应每个滑窗位置输出k个objectness scores和k个回归后region proposals,同时使用非极大值抑制。
在每个滑窗位置上,同时预测k个proposals(即一个像素对应原图的k=9个proposal)和4k个reg相应的输出,以及2k个cls scores(每个proposal为目标/非目标的概率),这k个proposals相对k个reference boxes,称为anchors。在每个滑动位置上,使用3个scales和3个aspect ratios,共生成9个anchors。对于一个W*H的特征图,共有W*H*k个anchors,这种方法的好处就是translation invariant。
Anchors表示RPN网络中对特征图滑窗时每个滑窗位置所对应的原图区域中9种可能的大小。根据图像大小计算滑窗中心点对应原图区域的中心点,通过中心点和size就可以得到滑窗位置和原图位置的映射关系,由此原图位置并根据与Ground Truth重复率贴上正负标签,让RPN学习该Anchors是否有物体即可。
为了训练RPN,为每个anchor赋一个类别标签(是否是object)。我们为两类anchors赋于正值:(1)anchor与ground_truth box有最大的
IoU重叠;(2)IoU重叠超过0.7。
FPN
https://blog.csdn.net/u013010889/article/details/78658135
----》
利用conv net本身的这种已经计算过的不同scale的feature,又想让low-level的高分辩的feature具有很强的语义,所以自然的想法就是把high-level的低分辨的feature map融合过来。
roi
https://blog.csdn.net/wfei101/article/details/79618567
---》
如 果roi大小为(7,6),而roipooling是分成了(6,6)的部分,(7,6)到(6,6)的转换必然带来了边缘某像素的损失。而 roialign利用双线性插值,将roi(7,6)插值扩充到(12,12),此时再做(6,6)的roipooling,会提高精度,充分利用了 roi的像素。
https://blog.csdn.net/zziahgf/article/details/78730859
--->
原始图像的每一个像素与特征图上的 25/128 个像素对应. 为了在原始图像选取 15 个像素,在特征图上我们需要选择 15 * 25/128 ~= 2.93 个像素.
Batch normalization has a negative effect on training if batches are small
so we disable it here.
那BN到底是什么原理呢?说到底还是为了防止“梯度弥散”。关于梯度弥散,大家都知道一个简单的栗子:。在BN中,是通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。可以说是一种更有效的local response normalization方法(见4.2.1节)。例如,在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
faster rcnn
候选框提取不一定要在原图上做,特征图上同样可以,低分辨率特征图意味着更少的计算量,基于这个假设,MSRA的任少卿等人提出RPN(RegionProposal Network)
RPN网络的特点在于通过滑动窗口的方式实现候选框的提取,每个滑动窗口位置生成9个候选窗口(不同尺度、不同宽高),提取对应9个候选窗口(anchor)的特征,用于目标分类和边框回归,与FastRCNN类似。
训练过程中,涉及到的候选框选取,选取依据:
1)丢弃跨越边界的anchor;
2)与样本重叠区域大于0.7的anchor标记为前景,重叠区域小于0.3的标定为背景;
从模型训练的角度来看,通过使用共享特征交替训练的方式,达到接近实时的性能,交替训练方式描述为:
1)根据现有网络初始化权值w,训练RPN;
2)用RPN提取训练集上的候选区域,用候选区域训练FastRCNN,更新权值w;
3)重复1、2,直到收敛