对于最小二乘法,维基百科给出的定义是:“最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。” 下面换一种容易理解的表述——已知什么、求什么。
经常碰到的这样一种场景:如图,假设你有一组观测数据{(x1,y1),(x2,y2)……(xn,yn)},需要找一个函数y=w1x+w2来拟合这些点,这个过程叫线性拟合。

为什么要找这个函数呢?为了预测,也就是说当我们用一组观测数据总结出一条规律(即目标函数)之后,就可以用这个规律预测没有观测过的点xn+1的观测值yn+1。可以看出,我们的最终目的是利用这组观测数据学得w1、w2两个参数。这个函数显然不能乱找,肯定要找最优的,也就是拟合效果最好的。怎么才算最优?最小二乘说了,只要使算出的函数曲线与观测值之差的平方和最小就是最优的。用函数表示为:
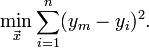
用欧几里得度量表达为:

第一个式子中ym是所求曲线的值,这个值是用所学得的函数y=w1x+w2估计的,yi实际观测值。意思是说,对于输入xi,如果用待求函数猜它的观测值则应该为ymi=w1xi+w2,但查询观测数据后发现实际观测值为yi。这两个值有误差,总之要让所求函数最优,就需要在已知数据的范围内使二者之差的平方之和最小。当然,如果你又有了一批新的观测值,可以利用两组观测值的并集重新算得一个预测性能更好的函数。
第二个式子是公式控比较欣赏的表达方式,即用向量的2范式表达,这就相当于求解以下问题:
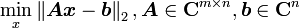
其特解为A的广义逆矩阵与b的乘积,这同时也是二范数极小的解,其通解为特解加上A的零空间(过程比较恶心,不详述,总之只要知道能解就行了)。
举个实际应用的例子,在文本分类中,每篇文档都会被表示成一个n维特征向量x和该文档的分类标签y,这里的x相当于输入,y相当于观测值。m篇文档的特征向量会形成一个m*n的特征矩阵X,对应m个观测值形成m维向量y,而我们要从中学得n维参数向量w,即求解问题min||Xw-y||2。最终求得一个可以预测文档分类的函数。
补充:细心的人会发现最小二乘对最优的定义是方差最小,有问题吗?有!虽然最小二乘估计量在所有线性无偏估计量中是方差最小的,但是这个方差却不一定小。实际上可以找一个有偏估计量,这个估计量虽然有微小的偏差,但它的精度却能够大大高于无偏的估计量,比如利用岭回归分析在正规方程中引入有偏常数而求得的回归估计量。