1.跳表是一种动态的数据结构(往跳表中插入数据时,我们需要不断的更新索引),它可以支持快速的插入、删除、查找功能,甚至可以替换红黑树,但实际使用不多,主要是红黑树出来的比较早,很多系统级别类库已经内置。
2. 一个链表,查找效率是O(n),如果给它建立索引,二级(多级)索引,先在索引里查找,然后在逐层下降到原始链表继续遍历,减少了遍历的节点数,这样就提高了(查找、插入和删除)效率。
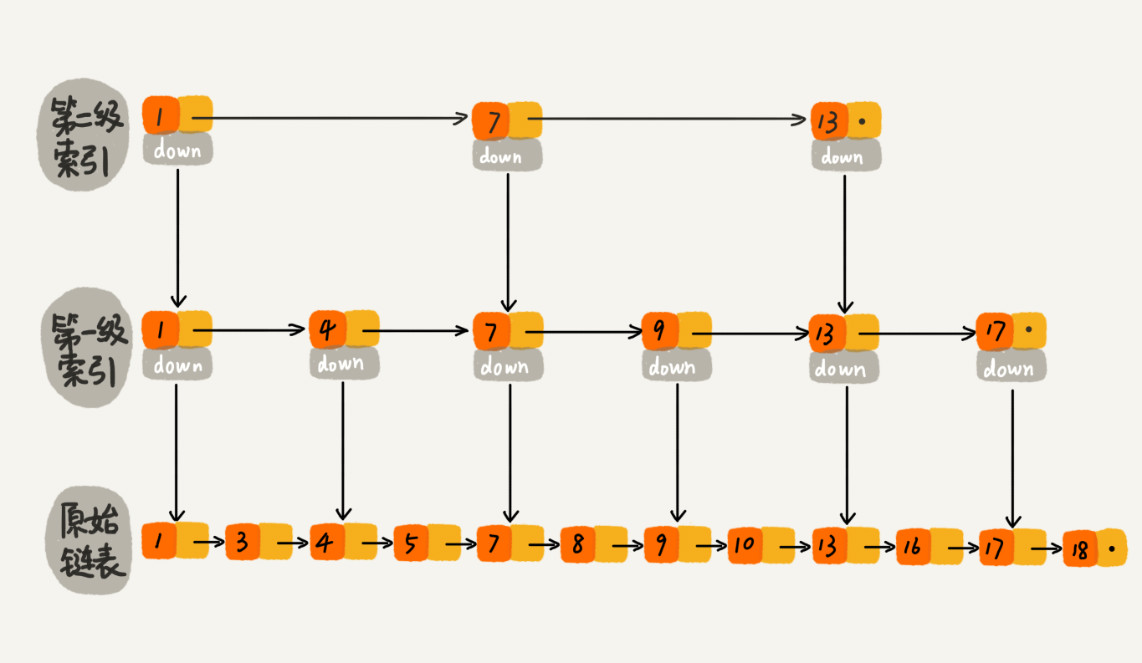
3. 跳表的查询时间复杂度是O(Logn),平时我们直接拿使用语言(java, c#)内置的来使用即可,它相对于红黑树更简单,实现也更容易,是一种空间换时间的做法,Redis使用跳表来实现有序集合。Redis的对象系统中的每种对象实际上都是基于使用场景选择多种底层数据结构实现的,比如ZSET就是基于【压缩列表】或者【跳跃表+字典】(这也跟之前排序中提到的Sort排序实现的思想一样,基于数据规模选择合适的排序算法),这也体现了Redis对于性能极致的追求。