数据规范化处理是数据挖掘的一项基本操作。现实中,数据中不同特征的量纲可能不一致,数值间的差别可能很大,不进行处理可能会影响到数据分析的结果,因此,需要对数据按照一定比例进行缩放,使之落在一个特定的区域,便于进行综合分析。特别是基于距离的挖掘方法,在建模前一定要对数据进行规范化处理,如SVM,KNN,K-means,聚类等方法
数据规范化处理处理主要有以下三种
1,最小-最大规范化
最小-最大规范化是对原始数据的线性变换,将数值值映射到[0,1]之间。
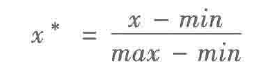
2,z-score
z-score规范化也成标准差规范化,经过处理的数据均值为0,方差为1。是目前最为常用的规范化方法。
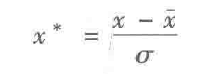
式中`x为对应特征均值 ,σ为标准差
3,小数定标规范化
通过移动属性值的小数点,将属性值映射到[-1,1]之间,移动的小数点位数取决于属性值绝对值的最大值。

python实现:
import pandas as pd
import numpy as np
# load raw_data
feture_matrix= ....
#max-min normalization
X=(feture_matrix - feture_matrix.min())/(feture_matrix.max()-feture_matrix.min())
# z-score
X= (feture_matrix - feture_matrix.mean()) / feture_matrix.std()
# normalization by decimal scaling
ferture_matrix/10**np.ceil(np.log10(data.abs().max()))