一、验证码破解
1.(上承连载15)极验
(1)官网:http://www.geetest.com
破解比较麻烦、可以模拟鼠标移动、一直在进化
二、Tesseract
1.机器视觉领域的基础软件
2.OCR:OpticalCharacterRecognition
3.Tesseract:一个OCR库,有谷歌资助
安装:https://blog.csdn.net/showgea/article/details/82656515
import pytesseract as pt import os # os.path() from PIL import Image #生成图片实例 image = Image.open(r"C:Userslenovo1untitledimage estOCR.jpg") #调用pytesseract,把图片转换为文字 text = pt.image_to_string(image) print(text)
三、爬虫框架Scrapy
1.常见的爬虫框架scrapypyspidercrawley,基本都是开源的
2.官方文档:https://docs.scrapy.org/en/latest/
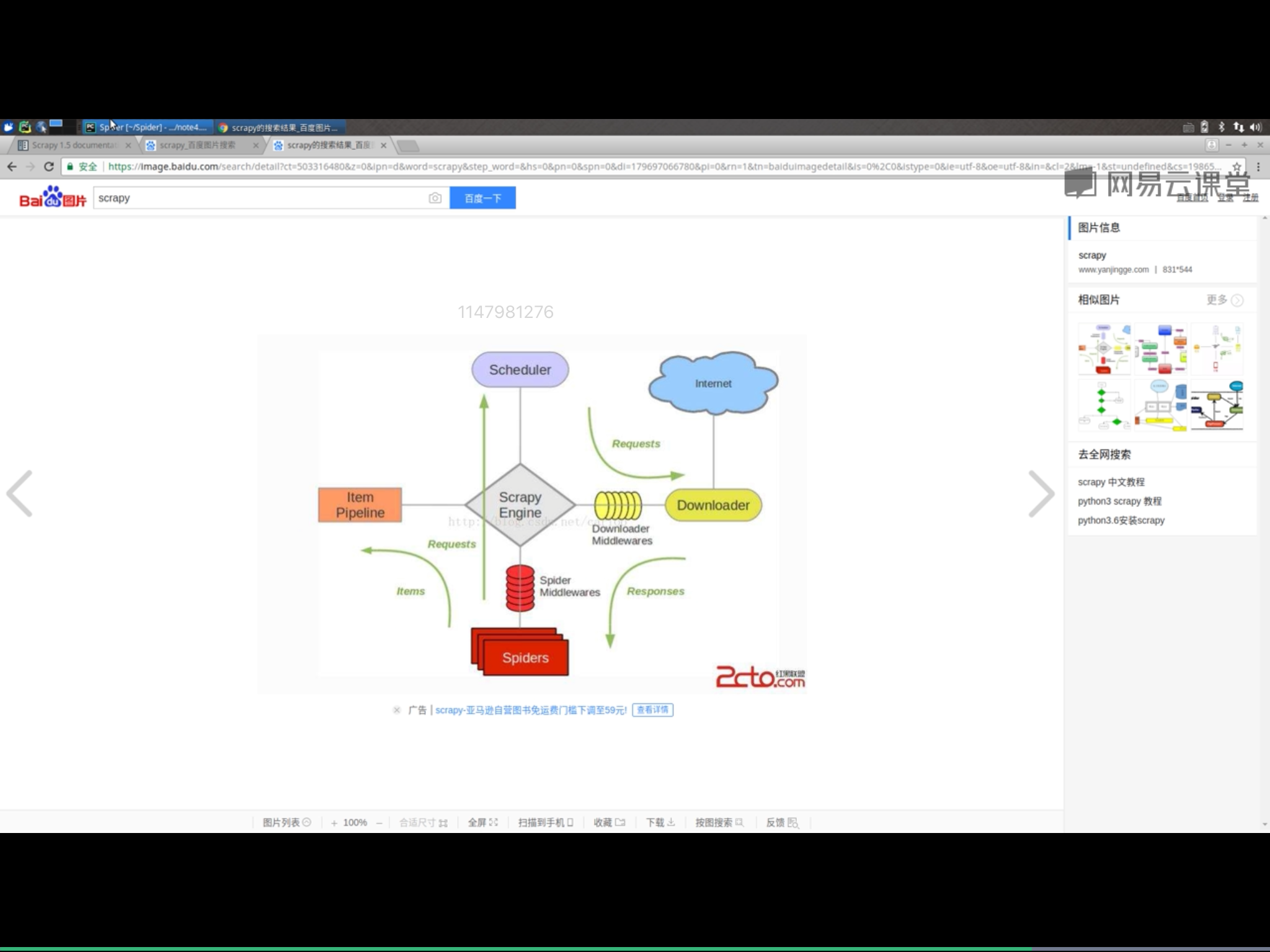
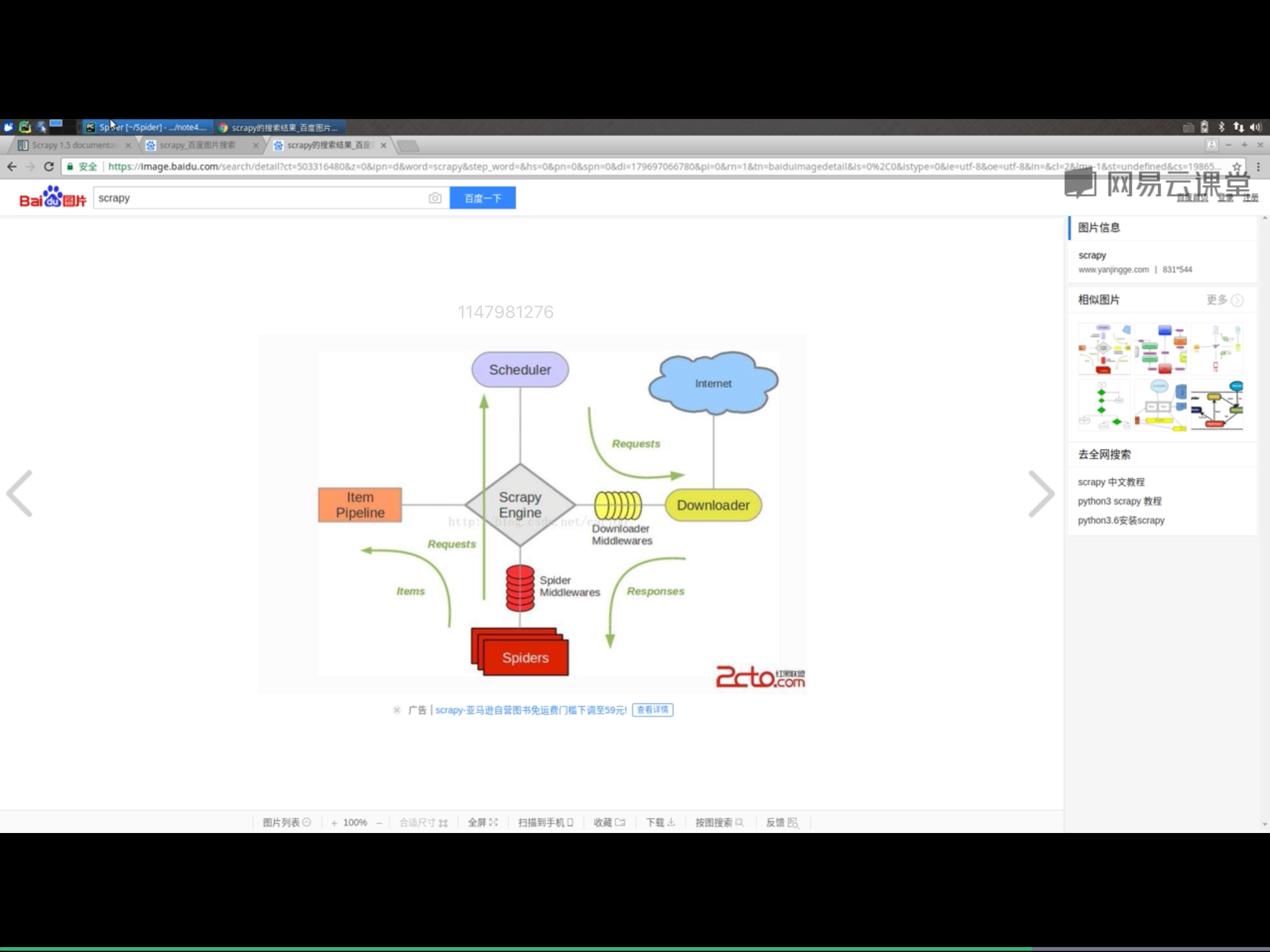
3.该框架包含如下各个部件
(1)ScrapyEngine:神经中枢、大脑、核心
(2)Scheduler调度器:引擎发来的request请求,调度器需要处理,然后交换引擎。
(3)Downloader下载器:把引擎发来的requests发出请求,得到response
(4)Spider爬虫:负责把下载器得到的网页/结果进行分解,分解成数据+链接。
(5)ItemPipeline管道:详细处理Item
(6)DownloaderMiddleware下载中间件:自定义下载的功能扩展组件
(7)Spidermiddleware爬虫中间件:
4.爬虫项目大概流程
(1)新建项目:scrapy startproject xxx
(2)明确需要的目标/产出:编写item.py
(3)制作爬虫:地址:spider/xxspider.py
(4)存储内容:pipelines.py
四、源码
Reptile16_1_VertificationCodeRecognition.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile16_1_VertificationCodeRecognition.py
2.CSDN:https://blog.csdn.net/weixin_44630050
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料
