1、 重写父类
1) 子类定义父类同名函数后,父类函数被覆盖;
2) 如果需要,可以在子类中调用父类方法:”父类名.方法(self)”、”父类名().方法()”、”super(子类名,self).方法()”
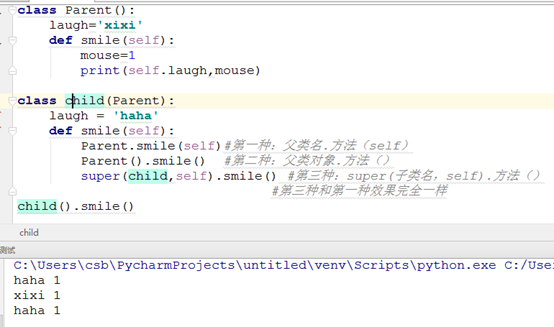
使用”super(classname,self).方法()”的重点是不需要提供父类,这意味着如果改变了类继承关系,只需要修改类定义的那行中的父类名称即可。此时寻找父类的工作由super函数完成。
2、 多重继承
一个类可以继承自多个类
如果继承的多个父类中包含相同函数,python3广度优先。
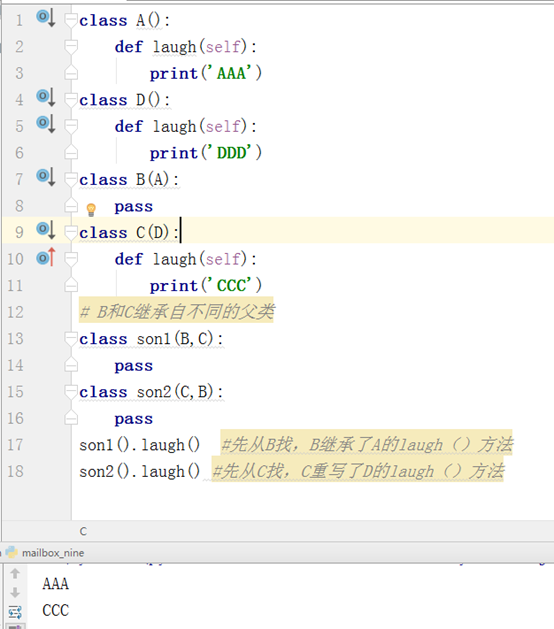
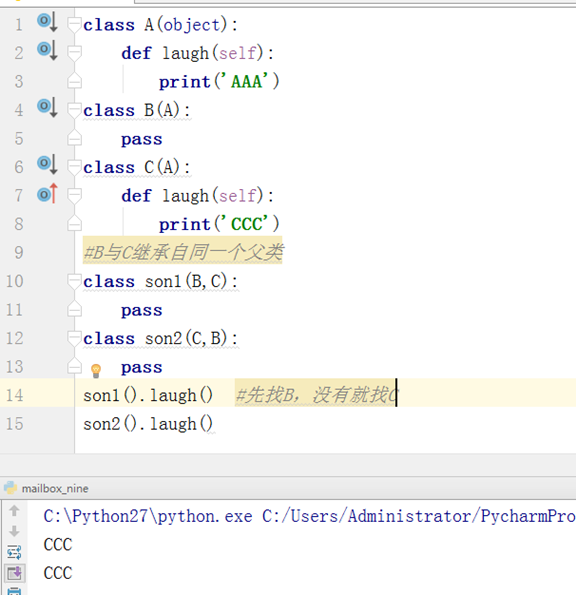
3、 检查类之间的父子关系
Issubclass(sub,sup):判断一个类是否是另一个类的子类或者子孙类。
Isinstance(obj,class):布尔函数,判断一个对象是否是一个类的实例,或者是否是这个类的子类的实例。
4、 多线程和多进程
进程是一个“执行中的程序”。进程是资源分配的基本单位。在单一程序中,同时运行多个线程完成不同的工作,称为多线程。
线程是操作系统能够进行运行调度的最小单位,它被包含在进程之中,是进程的实际运作的单元。一条线程指的是进程中一个单一顺序的控制流;一个进程中可以并发多个线程,每条线程并行执行不同的任务。
一个标准的线程有线程ID、当前指令指针、寄存器集合和堆栈组成。线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但她可与同属一个进程的其他线程共享进程所拥有的全部资源。
线程也有就绪、运行、阻塞三种基本状态,就绪状态是指线程具备运行的所有条件,在等待分配处理机;阻塞状态是指线程在等待一个事件,逻辑上不可执行;运行状态指线程占有处理机正在运行。
每个程序都至少有一个线程,若程序只有一个线程,那就是程序本身。
4.1 threading模块
python通过标准库threading提供对线程的支持。
4.1.1 Thread类
Thread类是线程类,有两种使用方式:1)直接传入要运行的方法 2)继承Thread类并重写run()方法
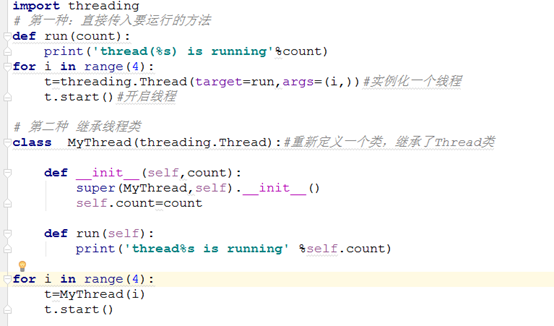
4.1.2常用方法:
1)threading.Thread():创建一个线程对象,并初始化
target:子线程要运行的方法名
args:要传入方法的参数,如果只传入一个参数l,要写成了”args=(l,)”
name:线程名,不设置的话,主线程默认为MainThread、子线程默认为Thread-1、Thread-2……
2)threading.current_thread():返回当前的线程变量
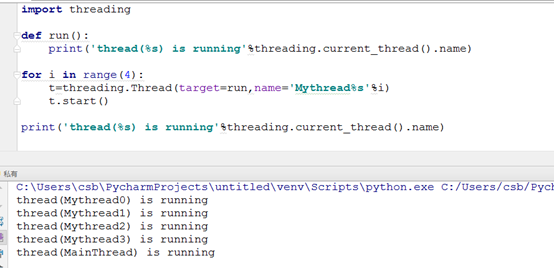
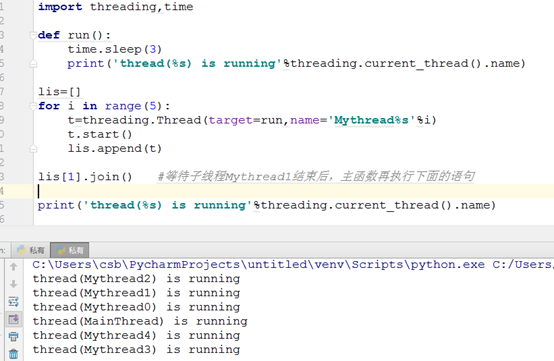
3) join([timeout]):阻塞当前上下文环境,主线程等待调用此方法的子线程执行完毕或者到达指定的timeout(可选参数)再继续执行。
多线程执行时,线程之间是相互独立的,不受其他线程的干扰,例如主线程在循环创建并启动完子线程后,就继续执行下面的指令,与此同时,各个子线程也都在执行自己的指令;如果想要等待某个子线程执行完毕后,主线程再继续往下执行的话,可以使用join函数。
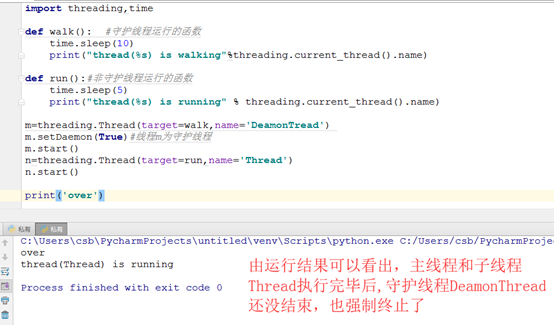
4) setDeamon(True):设置守护线程,在start()之前设置;主程序执行完毕后,无论守护线程是否运行完毕,都要停止。
需要强调的是,这里的主线程执行完毕是指主线程所在进程内的所有非守护线程统统运行完毕,主线程才算运行完毕;
4.2 GIL(GLOBAL INTERPRETER LOCK):全局解释器锁
GIL并不是python的特性,它是在实现python解析器(CPython)时所引入的概念;就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL.
GIL:在Python语言的主流实现CPython中,GIL是一个货真价实的全局线程锁,在解释器解释执行任何 Python 代码时,都需要先获得这把锁才行,在遇到 I/O 操作时会释放这把锁。如果是纯计算的程序,没有 I/O 操作,解释器会每隔 100 次操作就释放这把锁,让别的线程有机会执行(这个次数可以通过sys.setcheckinterval来调整)。所以在同一时间只会有一个获得了GIL的线程在跑,其它线程都处在等待GIL释放的状态。所以即使是在多核CPU中,因为GIL的限制,两个线程只能做分时切换,也只是使用的单核CPU. GIL本质是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
全局解释器的优点:1、避免了大量加锁解锁的好处 2、使数据更加安全,解决多线程间的数据完整性和状态同步
全局解释器的缺点:多核处理器退化成单核处理器,只能并发不能并行
Python的多线程在多核CPU上,只对于IO密集型计算产生正面效果;而当有至少有一个CPU密集型线程存在,那么多线程效率会由于GIL而大幅下降。
如果是CPU密集型代码(循环、计算等),由于计算工作量多和大,然后触发GIL的释放与再竞争,多个线程来回切换损耗资源,所以多线程在遇到CPU密集型代码时,效率反而没有单线程高;如果是I/O密集型代码(文件处理、网络爬虫),开启多线程实际上是并发(非并行),IO操作会进行IO等待,CPU自动切换线程,这样就提高了效率。
4.3 multiprocessing模块
与threading.Thread类似,它可以利用multiprocessing.Process对象来创建一个进程,该Process对象与Thread对象的用法相同,也有start(), run(), join()的方法。
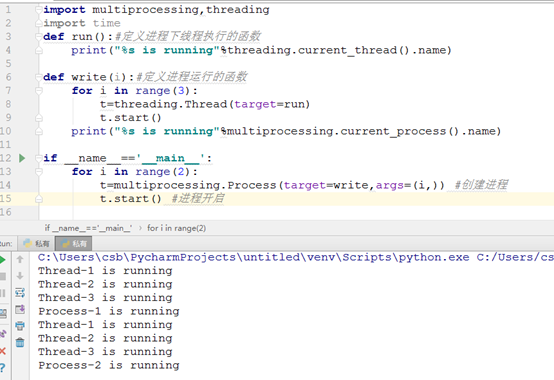
对于多进程来说,守护进程会在主进程运行完毕后被销毁;主进程在其代码执行完毕后就已经算运行完毕了(守护进程就在此时被回收)。然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束。
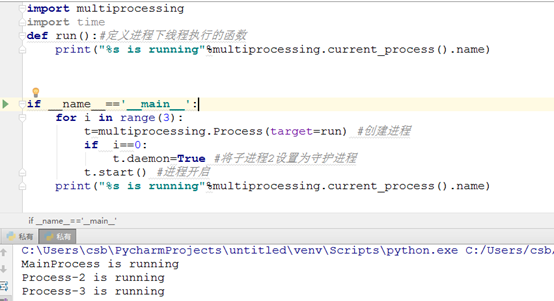
5、 logging模块
5.1 主要的类
logging模块中主要有4个类,分别负责不同的工作:
1、 Logger记录器,进行下面三项工作:
1) 为程序提供记录日志的接口
2) 判断日志所处的级别,并判断是否要过滤
3) 根据其日志级别将该条日志分发给不同的handler
常见的函数有:
1) Logger.setLevel():设置日志级别
2) Logger.addHandler()和Logger.removeHandler()添加或者删除一个Handler
3) Logger.addFilter():添加一个Filter,过滤作用
4) Logger.Handler():Handler基于日志级别对日志进行分发,
2、Handler处理器:将记录器产生的日志记录发送至合适的目的地,常用的有:
1) StreamHandler:控制台输出
2) FileHandler:文件输出
3) TimedRotatingFileHandlers:按照时间自动分割日志文件
4) RotatingFileHandler:按照大小自动分割日志文件,一旦达到指定大小重新生成文件
3、Filter过滤器:决定输出那些日志记录
4、Formatter 格式化器:指明最终输出中日志记录的格式
%(levelno)s: 打印日志级别的数值
%(levelname)s: 打印日志级别名称
%(pathname)s: 打印当前执行程序的路径,其实就是sys.argv[0]
%(filename)s: 打印当前执行程序名
%(funcName)s: 打印日志的当前函数
%(lineno)d: 打印日志的当前行号
%(asctime)s: 打印日志的时间
%(thread)d: 打印线程ID
%(threadName)s: 打印线程名称
%(process)d: 打印进程ID
%(message)s: 打印日志信息
5.2日志级别
日志级别:debug < info < warning < error < critical
1)debug级别,最低级别,一般开发人员用来打印一些调试信息
2)info级别,正常输出信息,一般用来打印一些正常的操作
3)waring级别,一般用来打印警告信息
4)error级别,一般用来打印一些错误信息
5)critical级别,一般用来打印一些致命的错误信息
设置了日志级别后,会打印该级别及高于该级别的所有日志信息。
不设置日志级别的话,默认为warning
5.3 输出日志
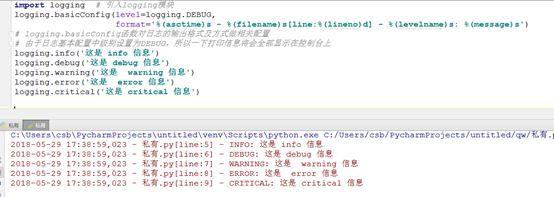
上面是将日志输出到控制台,我们也可以输出到文件中(如下),但是使用下面的格式,就只能讲日志输出到文件中,无法输出到控制台。
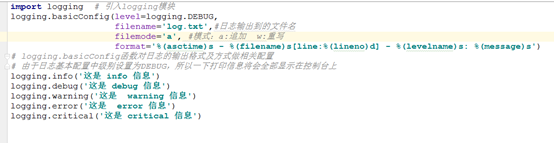
我们可以使用如下方法,既将日志输出到控制台,也将日志输出到指定的文件



参考网站