原文地址: https://terrifyzhao.github.io/2019/02/18/BERT原理.html
Bert其实并没有过多的结构方面的创新点,其和GPT一样均是采用的transformer的结构,相对于GPT来说,其是双向结构的,而GPT是单向的,如下图所示
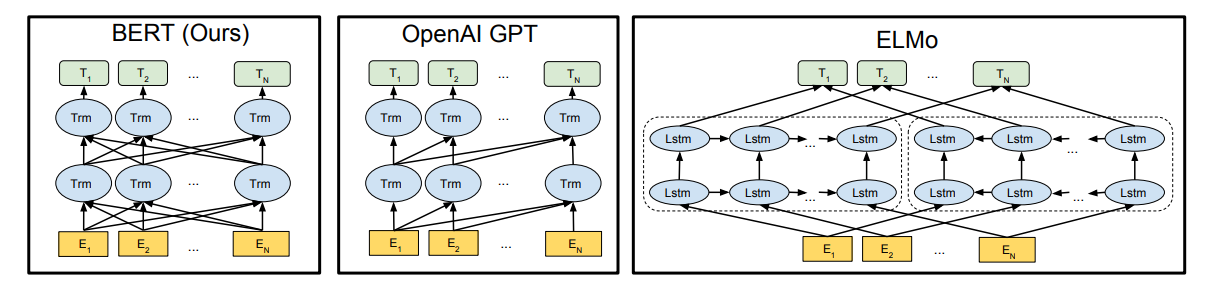
结构
先看下bert的内部结构,官网提供了两个版本,L表示的是transformer的层数,H表示输出的维度,A表示mutil-head attention的个数:
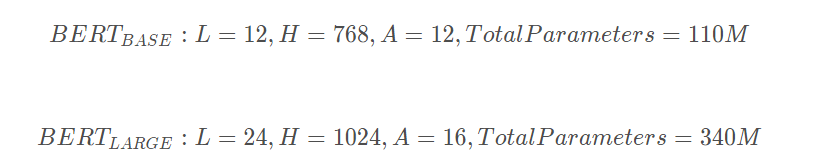
从模型的层数来说其实已经很大了,但是由于transformer的residual模块,层数并不会引起梯度消失等问题,但是并不代表层数越多效果越好,有论点认为低层偏向于语法特征学习,高层偏向于语义特征学习。
BERT的预训练过程
接下来我们看看BERT的预训练过程,BERT的预训练阶段采用了两个独有的非监督任务,一个是Masked Language Model,还有一个是Next Sentence Prediction。
Masked Language Model
mlm可以理解为完形填空,作者会随机mask每一个句子中15%的词,用其上下文来做预测,例如:my dog is hairy → my dog is [MASK]
此处将hairy进行了mask处理,然后采用非监督学习的方法预测mask位置的词是什么,但是该方法有一个问题,因为是mask15%的词,其数量已经很高了,这样就会导致某些词在fine-tuning阶段从未见过,为了解决这个问题,作者做了如下的处理:
-> 80%的时间是采用[mask],my dog is hairy → my dog is [MASK]
-> 10%的时间是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
-> 10%的时间保持不变,my dog is hairy -> my dog is hairy
那么为啥要以一定的概率使用随机词呢?这是因为transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"。至于使用随机词带来的负面影响,文章中说了,所有其他的token(即非"hairy"的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的。
Next Sentence Prediction
选择一些句子对A与B,其中50%的数据B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,学习其中的相关性,添加这样的预训练的目的是目前很多NLP的任务比如QA和NLI都需要理解两个句子之间的关系,从而能让预训练的模型更好的适应这样的任务。
输入
bert的输入可以是单一的一个句子或者是句子对,实际的输入值包括了三个部分,分别是token embedding词向量,segment embedding句向量,每个句子有个句子整体的embedding项对应给每个单词,还有position embedding位置向量,这三个部分相加形成了最终的bert输入向量。
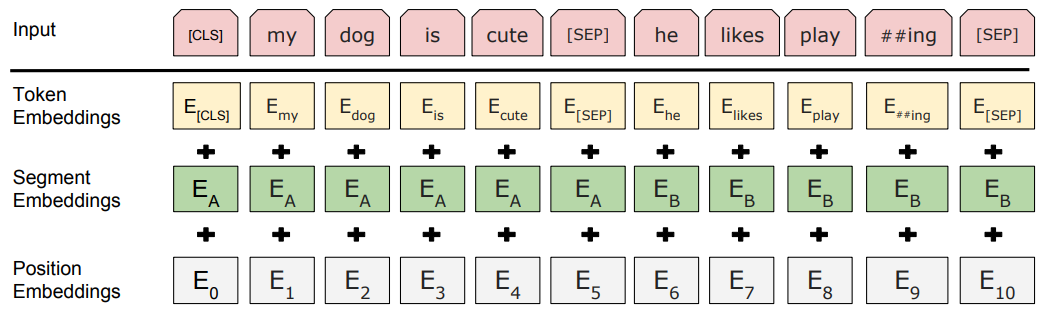
传统的句向量
对于传统的句向量生成方式,更多的是采用word embedding的方式取加权平均,该方法有一个最大的弊端,那就是无法理解上下文的语义,同一个词在不同的语境意思可能不一样,但是却会被表示成同样的word embedding,BERT生成句向量的优点在于可理解句意,并且排除了词向量加权引起的误差。
BERT句向量
BERT的包括两个版本,12层的transformer与24层的transformer,官方提供了12层的中文模型,下文也将会基于12层的模型来讲解。
每一层transformer的输出值,理论上来说都可以作为句向量,但是到底应该取哪一层呢,根据hanxiao大神的实验数据,最佳结果是取倒数第二层,最后一层的值太接近于目标,前面几层的值可能语义还未充分的学习到。