其实记录的基本是深度学习内容。
1. 梯度移动:
Y = 4 + 3wX +b
损失函数意义: 输入的x, 产出的预期y, 应接近真实Y。
Z = sqrt(y2 - Y2)
w = w - ∂Z/∂x 更新权值:

Y = 4 + 3wX +b
更新w 是更新该函数的斜率, 应用梯度, 使该斜率向着极小值点移动。
2. Tensorflow工作原理:
f(x,y) = x2y + y + 2
GPU1计算: x2y
GPU2计算: y + 2
深层网络, 比如10层, 每层百个神经元, 就有可能遇到两个问题:
1. 梯度消失: 斜率变化越来越小, 无法到达极值点。
2. 梯度爆炸: 斜率变化在一些层变化非常大, 跨越极值点。
梯度消失解决办法:
1. sigmod + 随机初始化: 使每层的输出方差 远大于输入方差。

随机初始化连接权重必须如下图所描述的那样。其中n_inputs和n_outputs是权重正在被初始化的层(也称为扇入和扇出)的输入和输出连接的数量。

2. 批量标准化:
该技术包括在每层的激活函数之前在模型中添加操作,简单地对输入进行zero-centering和规范化,然后每层使用两个新参数(一个用于尺度变换,另一个用于偏移)对结果进行尺度变换和偏移。
换句话说,这个操作可以让模型学习到每层输入值的最佳尺度,均值。为了对输入进行归零和归一化,算法需要估计输入的均值和标准差。 它通过评估当前小批量输入的均值和标准差(因此命名为“批量标准化”)来实现。

在测试时,没有小批量计算经验均值和标准差,所以您只需使用整个训练集的均值和标准差。 这些通常在训练期间使用移动平均值进行有效计算。 因此,总的来说,每个批次标准化的层次都学习了四个参数:γ(标度),β(偏移),μ(平均值)和σ(标准差)。
作者证明,这项技术大大改善了他们试验的所有深度神经网络。梯度消失问题大大减少了,他们可以使用饱和激活函数,如 tanh 甚至 sigmoid 激活函数。网络对权重初始化也不那么敏感。他们能够使用更大的学习率,显著加快了学习过程。
3. 迁移学习:
规范输入图像,与原始图像保持一致, 删除输出层。
冻结所有层, 替换掉softmax层, 较低层会对图像特征有效理解, 较高层已经是抽象后的, 因此较高层应逐层删除。
如果自己的数据集非常小, 冻结所有层, 将softmax输出层删除, 换成自己的分类。 freeze = 1。
数据增强技术: 镜像、随机裁剪、PCA色彩转换。
提升模型精度的保守方法: 集成神经网络。
4. 优化梯度下降速度:
如果局部梯度非常小, 则梯度更新非常缓慢:
使用动量优化:
动量优化很关心以前的梯度:在每次迭代时,它将动量矢量m(乘以学习率η)与局部梯度相加,并且通过简单地减去该动量矢量来更新权重(参见如下公式 )。 换句话说,梯度用作加速度,不用作速度。 为了模拟某种摩擦机制,避免动量过大,该算法引入了一个新的超参数β,简称为动量,它必须设置在 0(高摩擦)和 1(无摩擦)之间。 典型的动量值是 0.9。
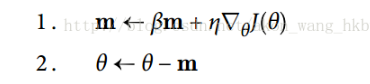
使用梯度局部斜坡:
尽管 AdaGrad 的速度变慢了一点,并且从未收敛到全局最优,但是 RMSProp 算法通过仅累积最近迭代(而不是从训练开始以来的所有梯度)的梯度来修正这个问题。 它通过在第一步中使用指数衰减来实现(见如下公式 )。
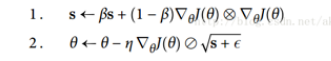
5. 解决过拟合问题:
构建稀疏模型: 使用L1 正则化。 或 L2正则化。 L2对w平方和进行惩罚, 即惩罚权重较大的波动; L1对绝对值之和进行惩罚, 逼迫更多为0;
随机裁剪: drop out
早期停止法。
6. 学习率优化:
找到一个好的学习速度可能会非常棘手。 如果设置太高,训练实际上可能偏离(如我们在第 4 章)。 如果设置得太低,训练最终会收敛到最佳状态,但这需要很长时间。 如果将其设置得太高,开始的进度会非常快,但最终会在最优解周围跳动,永远不会安顿下来(除非您使用自适应学习率优化算法,如 AdaGrad,RMSProp 或 Adam
设学习率为  。 超参数
。 超参数c通常被设置为 1。这与指数调度类似,但是学习率下降要慢得多。
Andrew Senior 等2013年的论文。 比较了使用动量优化训练深度神经网络进行语音识别时一些最流行的学习率调整的性能。 作者得出结论:在这种情况下,性能调度和指数调度都表现良好,但他们更喜欢指数调度,因为它实现起来比较简单,容易调整,收敛速度略快于最佳解决方案。
e.g. r=100, 每100步衰减一次。
7. 一些项目上的总结:
/**
* 协同过滤: 基于物品相识度 或 基于用户相识度
*/
/*例如基于用户的推荐, 用户1 的购买物品表
用户2 的购买物品表
用户3 的购买物品表
通过用户购买的商品, 计算欧几里得距离, 判断用户相识度;
绝对距离反映了用户之间的绝对差异, 余弦相识度更好的区分了用户的分离状态, 是一种趋势比较;
*/
/** 贝叶斯
* 假设男女人数相等, 男长裤0.25, 女长裤0.5, 求看到一个学生穿长裤,是男生的概率多大? P(B|T)
*
* 先验概率: P(B)=P(G)=0.5 P(T|B)=0.25 P(T)=0.25*0.5+0.5*0.5 = 0.375
* P(B|T) = P(B) * P(T|B)/P(T)
*
* 常用于文本分类;
*/
/**
* 高斯分布: 期望为u, 方差的u^2^的分布
* 高斯聚类: 单高斯分布聚类, 通过已有数据建立一个分布模型, 将样本数据带入分布, 判断是否在阀值之内; 比如5%的置信水平, 就是95%的置信区间;
* 混合高斯聚类: 对于过度重叠的数据, 单高斯模型无法严谨区分, 因此引入多个高斯模型, 使用极大似然估计训练参数;
*/
/**
* 关联算法: Apriori
* 支持度: 在订单中两个商品同时出现的次数, 与订单总数 的比值; 3/5
* 置信度: 商品A为先验条件, 当A出现时, B也出现的概率;
*
* 流程: 抛弃支持度过小项 -> 互相重组计算个数
* 缺点: 在计算支持度时, 需要频繁遍历原样本数据集, 因此在数据量较大时, 性能不佳;
*/
/**
* FP_growth算法, 只扫描两次数据库, 压缩数据库生成频繁模式树 从而生成关联规则
*
* ->首先扫描一次数据库, 删除最小支持度的样本, 并排序;
* ->组合后重新排序, 按顺序插入频繁模式树;
*/