知识点梳理
1.1 模式识别的基本概念
模式识别的应用实例:字符识别,动作识别,目标抓取等。
模式识别概念:根据已有知识的表达,针对待识别模式,判别决策其所属的类别或者预测其对应的回归值。
模式识别划分为"分类"和"回归"两种形式。分类:输出量是离散类别表达,即模式所属的类别。回归:输出量是连续的信号表达(回归值)。
1.2 模式识别的数学表达
模型:关于已有知识的表达。
特征提取:从原始输入数据提取更有效的信息。
回归器:将特征映射到回归值。
判别函数:sign函数(用于二类分类),max函数(多类分类)。

特征:可以用于区分不同类别模式的、可测量的量。具有辨别能力和鲁棒性。
特征向量:多个特征构成的列向量。空间中每个点代表一个样本,从坐标原点到该样本之间的向量即为该样本的特征向量。
1.3 特征向量的相关性
特征向量点积(结果是标量):点积表征两个特征向量的共线性,即方向上的相似程度。点积为0时说明两个向量是正交的。
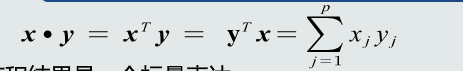
向量的夹角:反映两个向量在方向上的差异性。
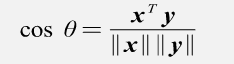
向量的投影:向量x分解到向量y方向的程度,分解的越多,说明两个向量方向上越相似。
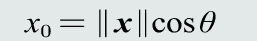
残差向量:向量x分解到向量y方向上得到的投影向量与原向量x的误差。

欧式距离:直观上来说就是两个点之间的距离。用来表征两个向量之间的相似程度(综合考虑方向和模长)。
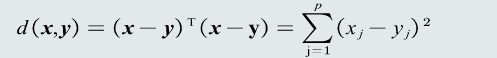
1.4 机器学习的基本概念
机器学习解决了模型如何得到的问题。模型又分为了线性模型和非线性模型。
机器学习流程图:获得训练样本,确定目标函数,通过优化算法以目标函数为标准获得模型参数的最优解。

机器学习的方式有监督式学习,无监督式学习,半监督式学习和强化学习。
监督式学习:训练样本及其输出真值都给定情况下的机器学习算法。通常使用最小化训练误差作为目标函数进行优化。
无监督式学习:只给定训练样本,没有给出输出真值情况下的机器学习算法。难度远高于监督式学习,主要根据训练样本之间的相似程度来进行决策。
半监督式学习:既有标注的训练样本、又有未标注的训练样本的情况下的学习算法。可视为有约束条件的无监督式学习。
强化学习:机器自行探索决策、真值滞后反馈的过程。有名的Alpha go就是用强化学习来训练的。
1.5 模型的泛化能力
训练集:模型训练所用的样本数据。每个样本称为训练样本。
测试集:测试模型性能所用的样本数据。每个样本称为测试样本。测试集与训练集是互斥的。
误差:模型给出的决策输出与真值输出之间的差异。分为训练误差与测试误差,训练误差即模型在训练集上的误差,测试误差在测试集上的误差,也被称为泛化误差。
泛化能力:训练得到的模型不仅要对训练样本具有决策能力,也要对新的样本有决策能力。
过拟合:模型过于拟合训练数据导致在测试阶段表现很差。
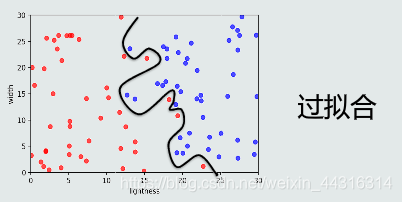
提高泛化能力的方法:1.选择复杂度合适的模型,2.正则化:在目标函数中加入正则项。通过调节正则系数,降低过拟合的程度。
1.6 评估方法和性能指标
评估方法:留出法,k折交叉验证,留一验证。
留出法:随机划分数据集为训练集和测试集,用训练集训练模型,测试集评估量化指标。为避免随机性,该过程进行若干次,量化指标取平均值。
k折交叉验证:将数据集分割为k个子集,选取单个子集作为测试集,剩下的为训练集。重复k次,保证每个子集都被作为一次测试集,对k次的量化指标取平均值。
留一验证:每次只去数据集中的一个样本做测试集,剩余的做训练集。每个样本测试一次,对n次的量化指标取平均值。留一验证即为k=n时的k折交叉验证。
性能指标:准确度,精度,召回率,F-Score,混淆矩阵,曲线度量,AUC。
准确度:(TN+TP)/N
精度:TP/(TP+FP) 召回率:TP/(TP+FN)
F-Sore:综合了精度和召回率。

混淆矩阵:矩阵的列表示预测值,行表示真值。矩阵的每个元素的值是根据每个测试样本的预测值和真值得到的计数统计值。对角线元素值越大模型性能越好。
曲线度量:设置若干个关于输出值的阈值,不同的阈值可以代表不同的应用任务,得到多个评估值,从而可以在空间中画出一条曲线。有PR曲线和ROC曲线。
AUC:即曲线下方面积,将曲线度量所表达的信息浓缩到一个标量表达。以0.5为阈值,AUC<0.5时说明比随机猜测还差。