基本概念
散列表是普通数组概念的推广。对于普通数组可以直接寻址(根据下标),使得能在O(1)时间内访问数组中的任意位置。
如果存储空间允许,我们可以提供一个数组,为每个可能的关键字保留一个位置,以利用直接寻址技术的优势。
当实际存储的关键字数目比全部的可能关键字总数要小时,采用散列表就成为直接数组寻址的一种代替。
在散列表中,不是直接把关键字作为数组的下标,而是根据关键字计算出相应的下标。
直接寻址表
当关键字的全域U比较小时,直接寻址是一种简单而有效的技术。
假设某应用要用到一个动态集合,其中每个元素都是取自于全域U={0,1,...,m-1}中的一个关键字,这里m不是一个很大的数。
为表示动态集合,我们用一个数组(直接寻址表),记为T[0...m-1],其中的每个位置(槽)对应全域U中的一个关键字。下图描绘了该方法
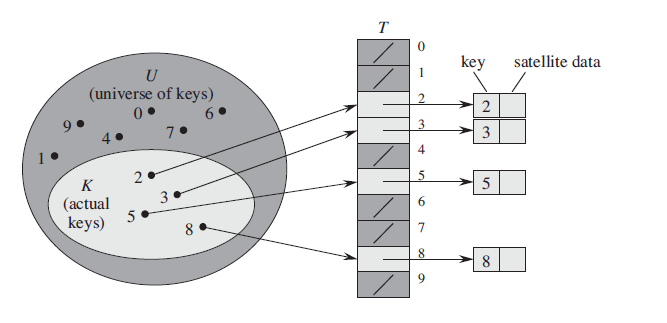
其中槽k指向集合中一个关键字为k的元素。如果该集合中没有关键字为k的元素,则T[k]=NIL
几个字典操作实现起来比较简单,而且每一个操作都只需O(1)时间
DIRECT-ADDRESS-SEARCH(T,k) return T[k] DIRECT-ADDRESS-INSERT(T,x) T[x.key]=x DIRECT-ADDRESS-DELETE(T,x) T[x.key]=NIL
散列表
直接寻址技术的缺点是非常明显的:
如果全域U很大,要存储大小为|U|的一张表T也许不太实际。
还有,实际存储的关键字集合K相对U来说可能很小,使得分配给T的大部分空间都将浪费掉。
在直接寻址方式下,具有关键字k的元素被存放在槽k中。在散列方式下,该元素存放在槽h(k)中,即利用散列函数h,由关键字k计算出槽的位置。

这里散列表的大小m了一般要比|U|小得多。这里存在一个问题:两个关键字可能映射到同一个槽中,我们称这种情况为冲突。
通过链接法解决冲突
在链接法中,把散列到同一槽中的所有元素都放在一个链表中。槽j中由一个指针,它指向存储在所有散列到j的元素的链表的表头,如果不存在这样的元素,则槽j中为NIL
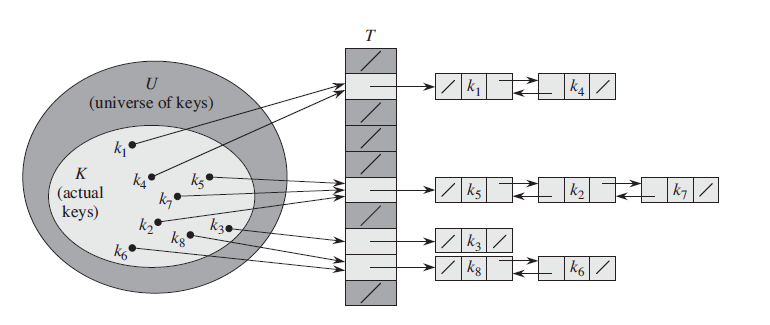
在采用链接法解决冲突后,散列表T上的字典操作就很容易实现
CHAINED-HASH-INSERT(T,x) insert x at the head of list T[h(x.key)] CHAINED-HASH-SEARCH(T,k) search for an element with key k in list T[h(k)] CHAINED-HASH-DELETE(T,x) delete x from the list T[h(x.key)]