关于脑的探寻:
简单分为下面三个层次:
-
computational level 计算层面的 ——>认知计算研究范畴
-
algorithmic/representation level 算法表示层面 ——>计算神经科学表示范畴
-
implementation/physical level 实现物理 ——>神经生物学研究范畴
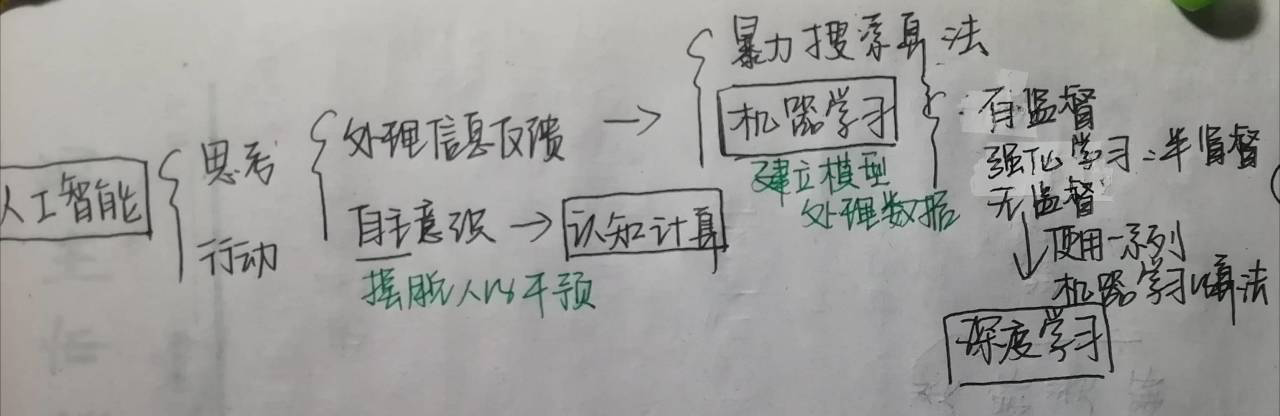
1 人工智能 :
类人思考系统+理性思考系统+类人行动系统+理性行动系统
下面是早年ai的一些算法:(1)暴力搜索,bf和df
(2)感知器(即一种用于单层神经网络的早期监督式算法)给定一个输入特征矢量,感知器算法将划分到特定的类别。通过使用训练集,可以更新线性分类的网络权值和阈值。我的理解是,根据输入的特征,进行线性回归,逻辑回归,然后梯度下降处理一下。
(3)集群算法:最简单的是一个k均值算法,他的大概思想,用一个随机的特征矢量初始化一个集群,然后将其他所有样本添加到集群,然后将其他所有样本添加到离他们最近的一个集群,他的质心会被重新计算。最后该算法会再次检查样本,确保他们存于最近的集群中, 并没有改变集群成员关系时停止运行。
(之前看过一个k-means算法,)
(4)决策树:即一种预测模型,可对某个结论的观察值进行预测。(树上的树叶代表结论,而节点是观察值分叉时所决在的决策点)决策树的学习算法根据属性值将数据集拆分成子集。
我的理解是:像树状图,一层一层往下,不断地判断,不断地确定分类数据。
(5)基于规则的系统:
基于规则的系统组成:规则集,知识库,推理引擎,用户界面;(可用于存储知识规则并使用一个推理系统得出结论)
<大家看到从感知器,集群算法,决策树什么的就开始和机器学习有交叉了>
2 机器学习:
提出目标:它的目标是让计算机能学习并构建模型,以便能够执行一些活动,比如特定领域中的预测。算是一个人工智能的子领域,算法目前是与认知计算有一些重合。
大体的过程:低层次感知 -> 预处理 -> 特征提取 -> 特征选择->推理预测识别
我的理解就是最重要的一步就是建立模型去处理特征,最基本的模型就是线性回归,逻辑回归等。大概有底下两个划分:
监督学习:监督学习即给出一组特征,也给出特征所对应的结果。以此来推测另外特征所对应的结果。(比如说给出某一地区房子的面积大小,卧室数量,以及它们所对应的价格。以此来预测给定面积大小,卧室数量的另外一些房子的价格。)向上面说的感知器就是这个思路,训练决策树也常常用到。
无监督学习:就是给出一些特征,但是不给出这些特征所对应的结果,以此判断这些特征的结构关系。向上面说的聚类算法就是这个思路。
强化学习(半监督式学习):一边获得样例,一边学习,在获得样例后更新自己的模型。
监督学习和无监督学习的区别:
监督学习需要训练集和测试样本,在训练集中寻找规律,而对测试样本使用这种规律。非监督学习只有一组数据,在此数据集中寻找规律。(注意找规律也不一定要分类)
监督学习的训练集中已经给出了输出值,但是半监督学习的奖励惩罚是延后给出的。
下面介绍一下常见的机器学习算法:
反向传播算法:即训练多层神经网络的算法。(类似于前面的感知器,但是感知器是一个单层的神经网络,为了升级训练多层的神经网络,就有了反向传播算法)
进行过程:第一阶段(前馈):通过一个神经网络将输入传播到最后一层。
第二阶段,算法计算一个错误,将次错误从最后一层反向传播到第一层。
训练期间,网络的中层自行地进行组织,以便将输入空间的各部分映射到输出空间,通过监督式学习,反向传播识别输入输出映射中的错误,相应地调整权值来更正此错误。
卷积神经网络(CNN):
进行过程:特征提取并分类 -> 将提取的特征注入卷积层—>通过池化保留最重要的信息->上面的步骤多次进行之后注入完全连通的多层感知器 -> 输出标识图像特征的结点 ->用户反向传播该训练该网络。
长短期记忆(LSTM):构建递归神经网络,将反馈送到前几层或者他们层中的后续节点,该属性使这些网络可以处理时序数据。
我的理解:很像是反向传播算法的一种改进,让中层的神经网络有一些记忆功能。
3 深度学习:
其像一个方法,而不是一种算法,即采用无监督学习来实现深度网络的一系列算法。可以理解为采用方法去使用改进机器学习中提到的算法。
4 类脑计算/认知计算:
认知计算的目标:建立一种能够摆脱人类干预的并自行解决复杂问题的计算系统。
详细一点说,认知计算就是一种自我学习系统,可以像人类大脑那样通过数据挖掘、图像识别以及自然语言处理来进行学习。
认知计算建立在神经网络和深度学习之上,运用认知科学中的知识来构建能够模拟人类思维过程系统。目前为止,他并没有单组技术,他更多地依托现有的机器学习算法。
总结图(字丑不要喷):
5 情感计算
其实这里涉及到的并不是让机器拥有人的情感,而是人类的情绪识别,比如NLP去分析文本所表达的情绪状态,还有通过生理指标,面部表情去识别人类的情绪。我的感觉是其实还是回归基本的分类,然后做出交互性更好的回馈。
所以,关于这个方面,它相当于是机器学习的一个研究方向,就好像NLP,计算机视觉这个样子。
为什么放到这里来说,就是想和认知计算做一个区分。
分享一个IBM出品的一个入门指南:https://www.ibm.com/developerworks/cn/cognitive/library/cc-beginner-guide-machine-learning-ai-cognitive/index.html(上面很多资料都来自这个)
上面的一些理解可能不一定正确,大家多多指正!
说说自己的想法,目前还是好好学习一下机器学习,可能未来往NLP,情感计算方向走一段吧,然后自己最终还是最喜欢认知计算。希望有大佬指点迷津,可以戳我私聊或者评论。
悄咪咪说一下自我感觉:研究人脑,很像抓住自己的头发把自己抬起来的感觉。大家加油。
顺便收集一下各方的机器学习的学习资料:
1 学习基础的,吴恩达,李宏毅的
(吴恩达老师讲的真的很清晰,我大一的时候看过都看得懂的那种类型,李宏毅是学长推荐的)
2 学习代码的:
最近看的是莫烦的pytorch
numpy我看的是阿里云大学的,只是了解了基础。