刚刚写完第一个selenuim+BeautifulSoup实战爬虫 爬淘宝。发现代码写完后不加for 翻页的时候没什么问题 解析 操作 都没问题 也就是说第一页 的内容 完好
1 pagebtn=wait .until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit"))) 2 soup=BeautifulSoup(browser.page_source,'lxml') 3 info=soup.find(attrs={'id':'mainsrp-itemlist'}) 4 imglist=info.find_all(attrs={'class':'J_ItemPic img'}) 5 pricelist=info.find_all('strong') 6 locationlist=info.find_all(attrs={'class':'location'}) 7 shopnamelist=info.find_all(attrs={'class':'shopname J_MouseEneterLeave J_ShopInfo'}) 8 for imgsrcname,price,location, shopname in zip(imglist,pricelist,locationlist, shopnamelist): 9 data={} 10 data={ 11 'name':imgsrcname.attrs['alt'], 12 'imgsrc':imgsrcname.attrs['src'], 13 'prick':price.get_text(), 14 'location':location.get_text(), 15 'shopname':shopname.contents[3].get_text() 16 } 17 collection.insert(data) 18 19 pagebtn.click()
运行完好 数据库也有数据
可是需要频繁点击翻页的时候
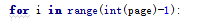

对于刚刚学习的人 一大串英文 显然看不懂 百度翻译 查
检查代码,
也加了等待啊 显示等待
为什么还是报错
说实话我不知道,,

在前面+了一个sleep(5)让他慢点操作 就可以了 完美翻页100
总结:
我觉得在使用selenuim的时候 尽可能的少操作网页(输入,点击),尽量模拟人的行为 机器运行太快 浏览器可能反应不过来。