ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
Zookeeper的工作机制
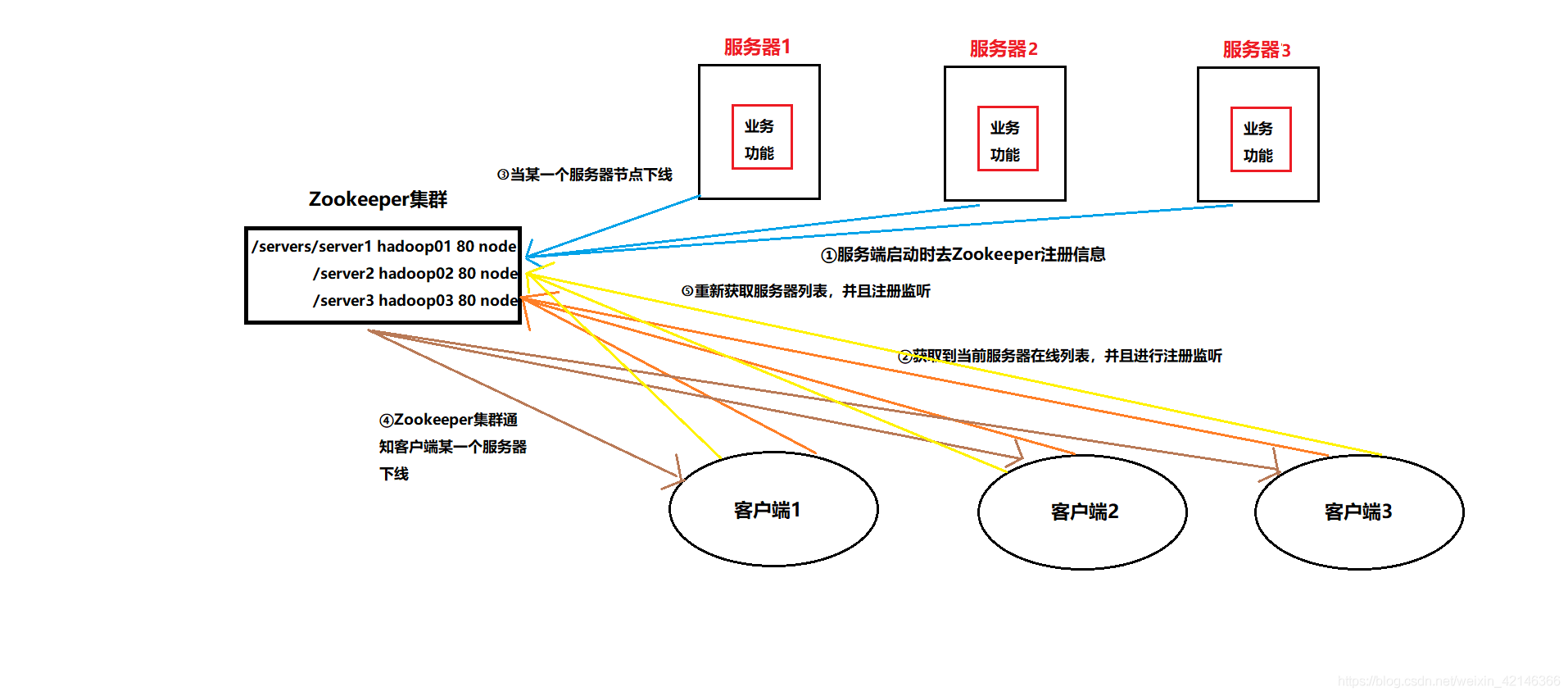
Zookeeper从设计模式的角度来理解:是一个基于观察者模式的分布式服务管理框架,它负责存储和管理重要的数据,然后接受观察者的注册,一旦这些被观察的数据状态发生变化,Zookeeper就负责通知已经在Zookeeper上注册的那些观察者让他们做出相应的反应。
Zookeeper的特点
【1】Zookeeper是存在一个领导者(Leader)和多个跟随者(Follower) 组成的集群。
【2】集群中若存在半数以上的(服务器存活数量必须大于一半,小于等于一半都不行)节点存活,就能正常工作。
【3】数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪一个Server获取的数据都是一样的。
【4】更新请求按发送的顺序依次执行。
【5】数据更新原子性原则,要么一次更新成功,要么失败。
【6】实时性,Client能够读取到最新的数据。
Zookeeper的Leader 选举
服务器状态:
- looking:寻找leader状态。当服务器处于该状态时,它会认为当前集群中没有Leader,因此需要进入 Leader 选举流程。
- leading:领导者状态。表明当前服务器角色是leader。
- following:跟随者状态。表明当前服务器角色是follower。
- observing:观察者状态。表明当前服务器角色是observer。
- 变更状态。leader挂后,余下的非 Observer 服务器都会将自己的服务器状态变更为looking,然后开始进入leader选举过程。
- 每个server会发出一个投票。在运行期间,每个服务器上的zxid可能不同,此时假定server1的zxid为123,server3的zxid为122,在第一轮投票中,server1和server3都会投自己,产生投票(1, 123),(3, 122),然后各自将投票发送给集群中所有机器。
- 接收来自各个服务器的投票。
- 处理投票。对于投票的处理,和上面提到的服务器启动期间的处理规则是一致的。在这个例子里面,由于 Server1 的 zxid 为 123,Server3 的 zxid 为 122,那么显然,Server1 会成为 Leader。
- 统计投票。
- 改变服务器状态。
Kafka的Leader选举
1.基础概念
【AR&ISR&OSR】
分区中的所有副本统称为AR(Assigned Replicas)。所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。与leader副本同步滞后过多的副本(不包括leader副本)组成OSR(Out-of-Sync Replicas),由此可见,AR=ISR+OSR。消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度的滞后。在正常情况下,所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即 AR=ISR,OSR集合为空。
leader副本负责维护和跟踪ISR集合中所有follower副本的滞后状态,当follower副本落后太多或失效时,leader副本会把它从ISR集合中剔除。如果OSR集合中有follower副本“追上”了leader副本,那么leader副本会把它从OSR集合转移至ISR集合。默认情况下,当leader副本发生故障时,只有在ISR集合中的副本才有资格被选举为新的leader,而在OSR集合中的副本则没有任何机会(不过这个原则也可以通过修改相应的参数配置来改变)。
【ISR的伸缩】
Kafka在启动的时候会开启两个与ISR相关的定时任务,名称分别为“isr-expiration"和”isr-change-propagation".。isr-expiration任务会周期性的检测每个分区是否需要缩减其ISR集合。这个周期和“replica.lag.time.max.ms”(延迟时间)参数有关。大小是这个参数一半。默认值为5000ms,当检测到ISR中有是失效的副本的时候,就会缩减ISR集合。如果某个分区的ISR集合发生变更, 则会将变更后的数据记录到ZooKerper对应/brokers/topics//partition//state节点中。
2.leader
在kafka集群中有2个种leader,一种是broker的leader即controller leader,还有一种就是partition的leader。
【Controller leader】
当broker启动的时候,都会创建KafkaController对象,但是集群中只能有一个leader对外提供服务,这些每个节点上的KafkaController会在指定的zookeeper路径下创建临时节点,只有第一个成功创建的节点的KafkaController才可以成为leader,其余的都是follower。当leader故障后,所有的follower会收到通知,再次竞争在该路径下创建节点从而选举新的leader
【Partition leader】
由controller leader执行
- 从Zookeeper中读取当前分区的所有ISR(in-sync replicas)集合
- 调用配置的分区选择算法选择分区的leader
3.如何处理所有Replica都不工作?
在ISR中至少有一个follower时,Kafka可以确保已经commit的数据不丢失,但如果某个Partition的所有Replica都宕机了,就无法保证数据不丢失了。有以下两种可行方案:
- 等待ISR中的任一个Replica“活”过来,并且选它作为Leader
- 选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader