布隆过滤器主要用于判断一个元素是否在一个集合中,它可以使用一个位数组简洁的表示一个数组。它的空间效率和查询时间远远超过一般的算法,但是它存在一定的误判的概率,适用于容忍误判的场景。如果布隆过滤器判断元素存在于一个集合中,那么是可能存在在集合中(称之为误判);如果它判断元素不存在一个集合中,那么一定不存在于集合中。常常被用于大数据去重。
- 优点:由于存放的不是完整的数据,所以占用的内存很少,而且新增,查询速度够快;
- 缺点:随着数据的增加,误判率随之增加;无法做到删除数据;只能判断数据是否一定不存在,而无法判断数据是否一定存在。
算法原理
布隆过滤器算法主要思想就是利用k个哈希函数计算得到不同的哈希值,然后映射到相应的位数组的索引上,将相应的索引位上的值设置为1。判断该元素是否出现在集合中,就是利用k个不同的哈希函数计算哈希值,看哈希值对应相应索引位置上面的值是否是1,如果有1个不是1,说明该元素不存在在集合中。但是也有可能判断元素在集合中,但是元素不在,这个元素所有索引位置上面的1都是别的元素设置的,这就导致一定的误判几率。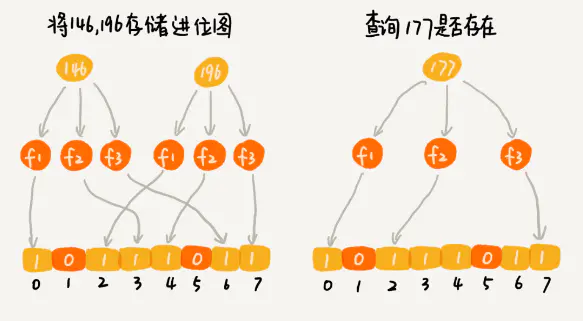
实例验证
1.数据量为100万,设定误判率为0.01 ,要验证的数据和布隆过滤器的数据完全不一样,此时打印结果:【总共的误判数:10314 耗时:150】


1 public class BloomTest { 2 3 private static int size = 1000000;// 预计要插入多少数据 4 5 private static double fpp = 0.01;// 期望的误判率 6 7 private static BloomFilter<Integer> bloomFilter = null; 8 9 public static void main(String[] args) { 10 bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp); 11 // 插入数据 12 for (int i = 0; i < size; i++) { 13 bloomFilter.put(i); 14 } 15 int errorCount = 0; 16 Long startTime = System.currentTimeMillis(); 17 for (int i = 0; i < size; i++) { 18 if (bloomFilter.mightContain(i)) { 19 errorCount++; 20 // System.out.println(i + "误判了"); 21 } 22 } 23 Long endTime = System.currentTimeMillis(); 24 System.out.println("总共的误判数:" + errorCount + " 耗时:" + (endTime - startTime)); 25 } 26 }
2.数据量为100万,设定误判率为0.01 ,要验证的数据和布隆过滤器的数据完全一样,此时打印结果:【总共的误判数:1000000 耗时:207】
1 public class BloomTest { 2 3 private static int size = 1000000;// 预计要插入多少数据 4 5 private static double fpp = 0.01;// 期望的误判率 6 7 private static BloomFilter<Integer> bloomFilter = null; 8 9 public static void main(String[] args) { 10 bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp); 11 // 插入数据 12 for (int i = 0; i < size; i++) { 13 bloomFilter.put(i); 14 } 15 int errorCount = 0; 16 Long startTime = System.currentTimeMillis(); 17 for (int i = 0; i < size; i++) { 18 if (bloomFilter.mightContain(i)) { 19 errorCount++; 20 // System.out.println(i + "误判了"); 21 } 22 } 23 Long endTime = System.currentTimeMillis(); 24 System.out.println("总共的误判数:" + errorCount + " 耗时:" + (endTime - startTime)); 25 } 26 }
3.数据量为100万,设定误判率为0.01 ,要验证的数据和布隆过滤器的数据完全不一样,此时打印结果:【总共的误判数:994 耗时:166】
1 public class BloomTest { 2 3 private static int size = 1000000;// 预计要插入多少数据 4 5 private static double fpp = 0.001;// 期望的误判率 6 7 private static BloomFilter<Integer> bloomFilter = null; 8 9 public static void main(String[] args) { 10 bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp); 11 // 插入数据 12 for (int i = 0; i < size; i++) { 13 bloomFilter.put(i); 14 } 15 int errorCount = 0; 16 Long startTime = System.currentTimeMillis(); 17 for (int i = size; i < size * 2; i++) { 18 if (bloomFilter.mightContain(i)) { 19 errorCount++; 20 // System.out.println(i + "误判了"); 21 } 22 } 23 Long endTime = System.currentTimeMillis(); 24 System.out.println("总共的误判数:" + errorCount + " 耗时:" + (endTime - startTime)); 25 } 26 }
综上实例可得如下信息:
a.布隆过滤器只能判断数据一定不存在,所以应用场景是将所有可能存在的数据存到布隆过滤器,对于一定不存在的数据,请求直接返回
b.误判率设定可以增加数据判断的准确性
核心源码解析
1 static <T> BloomFilter<T> create( 2 Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) { 3 checkNotNull(funnel); 4 checkArgument( 5 expectedInsertions >= 0, "Expected insertions (%s) must be >= 0", expectedInsertions); 6 checkArgument(fpp > 0.0, "False positive probability (%s) must be > 0.0", fpp); 7 checkArgument(fpp < 1.0, "False positive probability (%s) must be < 1.0", fpp); 8 checkNotNull(strategy); 9 10 if (expectedInsertions == 0) { 11 expectedInsertions = 1; 12 } 13 /* 14 * TODO(user): Put a warning in the javadoc about tiny fpp values, 15 * since the resulting size is proportional to -log(p), but there is not 16 * much of a point after all, e.g. optimalM(1000, 0.0000000000000001) = 76680 17 * which is less than 10kb. Who cares! 18 */ 19 long numBits = optimalNumOfBits(expectedInsertions, fpp); 20 int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits); 21 try { 22 return new BloomFilter<T>(new BitArray(numBits), numHashFunctions, funnel, strategy); 23 } catch (IllegalArgumentException e) { 24 throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e); 25 } 26 } 27 28 static long optimalNumOfBits(long n, double p) { 29 if (p == 0) { 30 p = Double.MIN_VALUE; 31 } 32 return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2))); 33 }
布隆过滤器实例化的内存空间是依据数据量大小和误判率来计算的。以100万数字,0.01的误判率计算,需要的 numBits 为14377587bit,计划构建的hash函数 numHashFunctions 为 10.
1 public <T> boolean mightContain( 2 T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits) { 3 long bitSize = bits.bitSize(); 4 long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong(); 5 int hash1 = (int) hash64; 6 int hash2 = (int) (hash64 >>> 32); 7 8 for (int i = 1; i <= numHashFunctions; i++) { 9 int combinedHash = hash1 + (i * hash2); 10 // Flip all the bits if it's negative (guaranteed positive number) 11 if (combinedHash < 0) { 12 combinedHash = ~combinedHash; 13 } 14 if (!bits.get(combinedHash % bitSize)) { 15 return false; 16 } 17 } 18 return true; 19 } 20 }
布隆过滤器对数据进行验证时,会对每个hash函数生成的数据进行验证,有一个不符合,那么数据一定不在。