2クラウドコンピューティング
2.1概要
クラウドコンピューティングは21世紀の世界を支える重要なインフラストラクチャーであるが、突然生まれた新しい単独の技術ではない。多数のサーバの集合をあたかも1つの巨大リソースをもつコンピュータのように扱うことのできる仮想マシン技術や、大量のデータを複数のストレージに分散配置し、並列処理することで必要な都度瞬時に取り出し組み立てることのできる分散処理技術、それらに対応したハードディスクを筆頭とした大容量等、最新の情報通信技術を集大成し構築した新たなパラダイムということができる。インターネット経由の一般向けサービスを「パブリッククラウド」、業界内・企業内(ファイアーウォール内)などのサービスを「プライベートクラウド」、両者を組み合わせたサービスを「ハイブリッドクラウド」とも呼ぶ。
クラウドコンピューティングは、以下の3種類に分類される場合が多い。
SaaS
インターネット経由のソフトウェアパッケージの提供
PaaS
インターネット経由のアプリケーション実行用のプラットフォームの提供。
IaaS
インターネット経由のハードウェアやインフラの提供。
2.2パブリッククラウド
パブリッククラウドはクラウド提供者が公衆のインターネット網を介して不特定多数の個人ユーザや企業に提供する、企業や組織を外部攻撃から守るファイアウォールの外側に構築されるクラウドサービスである。パブリッククラウドとして提供されているサービスの例としては、Amazon.comの「Amazon EC2」、Microsoftの「Windows Azure」、Salesforce.comの「Force.com」などを挙げることができる。
• Dropbox
本研究でDrpoboxはパブリッククラウドとしてサービスを提供する。具体的に、各種データやファイルをクラウド上に保存できるオンラインストレージサービスである。専用アプリをインストールし、ユーザー登録をすることで、写真や動画、文書等を保存することができ、PCやスマートフォン等複数のデバイスからアクセスすることができる。
2.3プライベートクラウド
公衆を意味する誰もが使えるパブリッククラウドに対し、プライベートクラウドは文字どおり自社専用のクラウドコンピューティングシステムを構築することであり、利用者は利用できる権限を有する従業員等に限定される。プライベートなクラウド環境は、利用者自身またはクラウドベンダのデータセンタに自社専用のプライベートなクラウド環境を構築することで可能となる。自社専用の環境を構築することによってコンピュータリソースを自由に利用することができるし、何より自社のプライベートデータがどこにあるかわからない不安や、いつ漏洩するかもわからない不安から解消されるメリットは大きい。
• Openstack
OpenStackは、オープンソースで開発されているクラウド環境構築用のソフトウェア群です。クラウドの分類のうち、いわゆるIaaSと呼ばれる仮想マシンとストレージ、ネットワークといった、一番低いレイヤーのリソースを提供するクラウド環境が構築できます。
• Nova 全てのスケジュールや起動の処理をオーケストレートする
• Swift 無限にスケーラブルなブロブ(輪郭のない)ストレージ。データの保存や読み出しを可
能にする
• Cinder ゲストVMに永続的ブロックストレージを提供する
• Neutron
全てのOpenStackサービスを接続するためのSDN(ソフトウェアで定義されたネット
ワーク)を提供する
• Horizon
他のOpenStackコンポーネントにweb フロントエンドを提供する
• Keystone
OpenStackコンポーネントへの認証と権限付与を提供する
• Glance
仮想ディスクイメージのカタログと保存場所を提供する
2.4ハイブリッドクラウド
ハイブリッドクラウドはシステムの特性に応じてこの二つを組み合わせたもので、例え ば、機密データや個人情報などを扱うシステムはプライベートクラウドで運用し、繁閑の 差が大きく処理量が時期によって大きく変動するシステムや一時的に必要となるシステム をパブリッククラウドで運用することで、一定のセキュリティレベルを確保しながら固定 費を削減することができる。
また、クラウドサービスの多くが従量課金であることを利用して、同じシステムを通常 はプライベートクラウドで運用し、突発的に処理量が増大した時だけパブリッククラウド を活用するといった手法もハイブリッドクラウドに含まれる。
3機械学習による分類器
3.1概要
分類器とは、学習用のデータに含まれる情報を用いて、問い合わせデータがどのような カテゴリに属するのかを予測することである。分類器は数学モデルの一部、モデルによっ て様々な種類がある:K近傍法、ナイーブベイズ、決定木、サポートベクトルマシンなど。
3.2 k近傍法
k近傍法は目的のわからないデータから、全既知データまでの距離を測る。そして距離 の短い順k個で多数決し判断する。k は正の整数で、一般に小さい。k = 1 なら、最近傍の オブジェクトと同じクラスに分類されるだけである。二項分類の場合、k を奇数にすると 同票数で分類できなくなる問題を避けることができる。
アルゴリズムは以下のように:
-
パラメーターKの値を決定する
-
問い合わせデータと学習データとの類似度を計算する
i=2で2次元平面の点間の距離を計算する
-
計算したデータの類似度に基づいてデータを並べ替える
-
決定したkの個数だけ、類似度に基づいて問い合わせデータに類似するデータを選択 し、選択されたデータのカテゴリの多数決投票を行う
-
最多となるデータのカテゴリが、問い合わせデータの推測されるカテゴリとなる

映画の名前 キスシーンの回数 アクションシーンの回数 ジャンル
California Man 3 104 恋愛
He's Not Really into Dudes 2 100 恋愛
Beautiful Woman 1 81 恋愛
Kevin Longblade 101 10 アクション
Robo Slayer 3000 99 5 アクション
Amped II 98 2 アクション
? 18 90 未定
表2-1
ある人はかつて映画のアクションシーンとキスシーンを統計した。図には映画のアクションシーンとキスシーンの回数を示す。もしかして未見の映画があったら、私たちはKNNを使ってこの映画のジャンルを判断できる。この映画とサンプル映画の距離を計算し、結果は表に示す。
映画の名前 距離
California Man 20.5
He's Not Really into Dudes 18.7
Beautiful Woman 19.2
Kevin Longblade 115.3
Robo Slayer 3000 117.4
Amped II 118.9
表2-2
距離の大きさにより映画を並べる。仮定K=3、3つの最も近くの映画は順番にHe ' s Not Really into Dudes、Beautiful WomanとCalifornia Manである。この三つの映画は全部恋愛のカテゴリに属すので、この映画のジャンルは恋愛と判断される。
3.3ナイーブベイズ
ナイーブベイズはベイズの定理と特徴変数間の独立性仮定を用いた分類器である。現実 の問題では特徴を表す素性同士に何らかの相関が見られるケースが多々あるが、独立性仮 定によって計算量を簡素化・削減し、高速でそこそこの精度を誇る分類器を実装すること ができる。
ベイズの定理
ベイズの定理とは、ある結果が得られた時、その結果の下での事後確率を求めるための 考え方である。入力 X が与えられた時に出力 Y が得られる確率P (Y |X )は以下の等式で表 す事が出来ます:
P (Y |X) = P (Y ) P (X|Y ) (2) P (X)
P(Y) は事前分布と呼ばれ、P (X |Y )は尤度とか条件付き確率とか呼ばれる。 ナイーブベイズモデル
ベイズの定理を使えば、ナイーブベイズモデルは次のようになる:
P (ci|w1, w2...wn) = P (w1|ci) P (w2|ci) ...P (wn|ci) P (ci) (3)
P (w1) P (w2) ...P (wn) ciはカテゴリ変数を表し、w1, ...wnは特徴変数である。
ナイーブベイズ分類器
P (w1) P (w2) ...P (wn)はP (w1)、P (w2)、...、P (wn)にのみ依存する係数であり、特徴 変数群の値が既知であれば定数となる。ナイーブベイズ分類器は次のようになる:
classify (w1, w2...wn) = argmaxP (ci) P (w1|ci) P (w2|ci) ...P (wn|ci) (4) c
ファイルの分類から考えれば、P (ci)はすべてのファイルにおける各カテゴリの確率を 表す:
p(ci) = N (ci) (5) N (c1) + N (c2) + ... + N (cn)
P (w|c)は単語wがカテゴリcから取り出されたファイルに出現する確率である:
p (wi|ci) = N (wi, ci) (6)
N (ci)
上の2つの式に、N (ci)は各カテゴリに属するファイル数を表し、N (wi, ci)はカテゴリcに
属する単語wがあるファイル数である。
3.4 サポートベクトルマシン
サポートベクターマシンは2クラス分類識別器の一種ある。訓練サンプルから、各データ点との距離が最大となるマージン最大化超平面を求めるという基準で線形入力素子のパラメータを学習する。具体的に、学習データの中でサポートベクトルと呼ばれるクラス境界近傍に位置する訓練点を基準として、その距離が最も大きくなるような位置に識別境界を設定する。つまり、クラスの最端から他クラスまでの「マージンを最大にする」ように分離超平面を構築しクラス分類を行う。分類面が線形で無い場合は、カーネルトリックと呼ばれる手法を用いて入力空間をより高次の特徴空間に写像し、そこで線形分離を行う。すると非線形の識別面を構成することが可能である。
ここで,SVMについて説明するために,分類問題の中で最も簡単な,2種類のデータの分類を考える。すなわち,図のように、二つの種類のデータを分類する。ここでは,分類のようすをグラフィカルに表現するために,これらのデータは, と表されるような2次元のデータとする.
と表されるような2次元のデータとする.

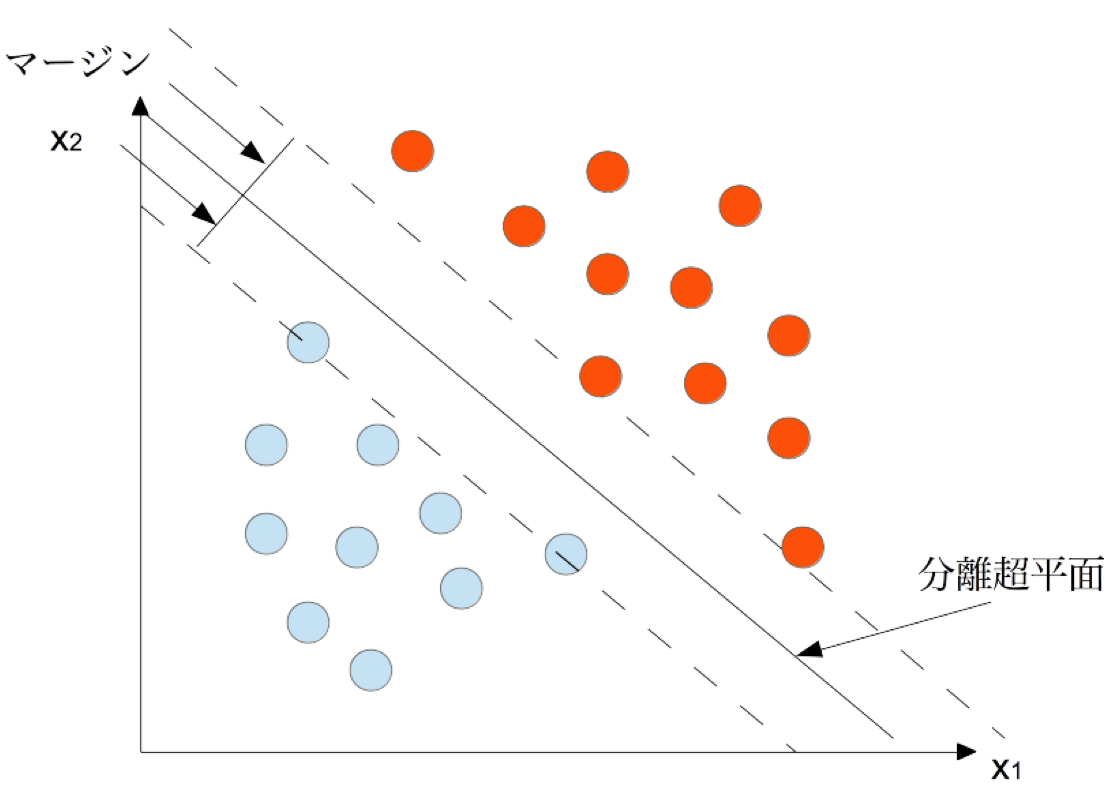
このとき,与えられたデータを分類するということは,与えられたデータを用いて,それらをどのように分類したらよいかをSVMが学習している,と解釈できる.ここで,学習の本当の目的は,あらかじめ与えられたデータをうまく分類することではなく,学習に用いなかった未知のデータをうまく分類させることである.このような能力を,学習理論では汎化能力と呼んでいる.
SVMでは,図2に示すように,分離超平面(ここでは直線)と,2種類のデータとの間の距離(これをマージンと呼ぶ)が最大になるような分離超平面が,最も汎化能力の高い超平面になるということを利用している.マージンを最大化する方法を定式化すると,2次計画問題に帰着することができる。
4関連研究
4.1迷惑メールの研究
近年,携帯電話端末やインターネットにおける電子メールの担う役割は非常に大きい. しかし,電子メールの一般化に伴い,それに付随する問題もまた増加の一途を辿っている. 現在,特に問題となっているのが公告等の目的で無差別に送信される Spam メールであり, 中には犯罪性をおびた目的で送信されているものも決して少なくない.文献では全世界の メールトラフィックに占めるSPAMメールの割合が2010年には92.5%を超えたという報告が 示されている。
受信メールからSPAMメールを除外するSPAMメールフィルタでは、アドレスやドメイ ンなどの発信元情報、ヘッダやメール本文の出現単語などの特徴を学習し、SPAMメール であるか否かの判別を行っている。このSPAMメールフィルタに利用される技術が機械学 習アルゴリズムである。機械学習アルゴリズムは多くの手法が提案されており、中でもベ イジアンフィルタとして知られるナイーブベイズ分類器がSPAMメールフィルタとして広 く利用されている。
4.2 ソーシャルクラウド
SNSは現在多くの人にとって日常生活の一部となっている. 人と人とのつながりを促進し、交際範囲を幅広く拡張する. また、アプリケーションの認証に Facebook アカウント情報を利用する組織が多数存在する.本論文では、友人間の信頼関係を利用し、ソーシャルクラウドでリソース(情報、ハードウェア、サービス)の共有を提案する.
ソーシャルクラウドとは、Facebook アカウントの識別を通じて特定のユーザーにマップすることができる.たとえば、ユーザーは、同じ国/ネットワーク/グループ、すべての友人、または友人の友人との取引を制限することができる.専門的なバンキングコンポーネントは、現在の予約に関連する情報を格納しながら、ユーザー間のクレジットを管理する
アーキテクチャは図 1 に示している
• Banking Service
クラウドのすべてのメンバーを登録し、メンバーのクレジット残高と参加している契約を格納する
• Posted Price Marketplace
ユーザーは提供されるサービスを自由に選択できるし、特定の用件を定義することができる
• Auction Marketplace
サービスはユーザのタスクをホストする権利を争う
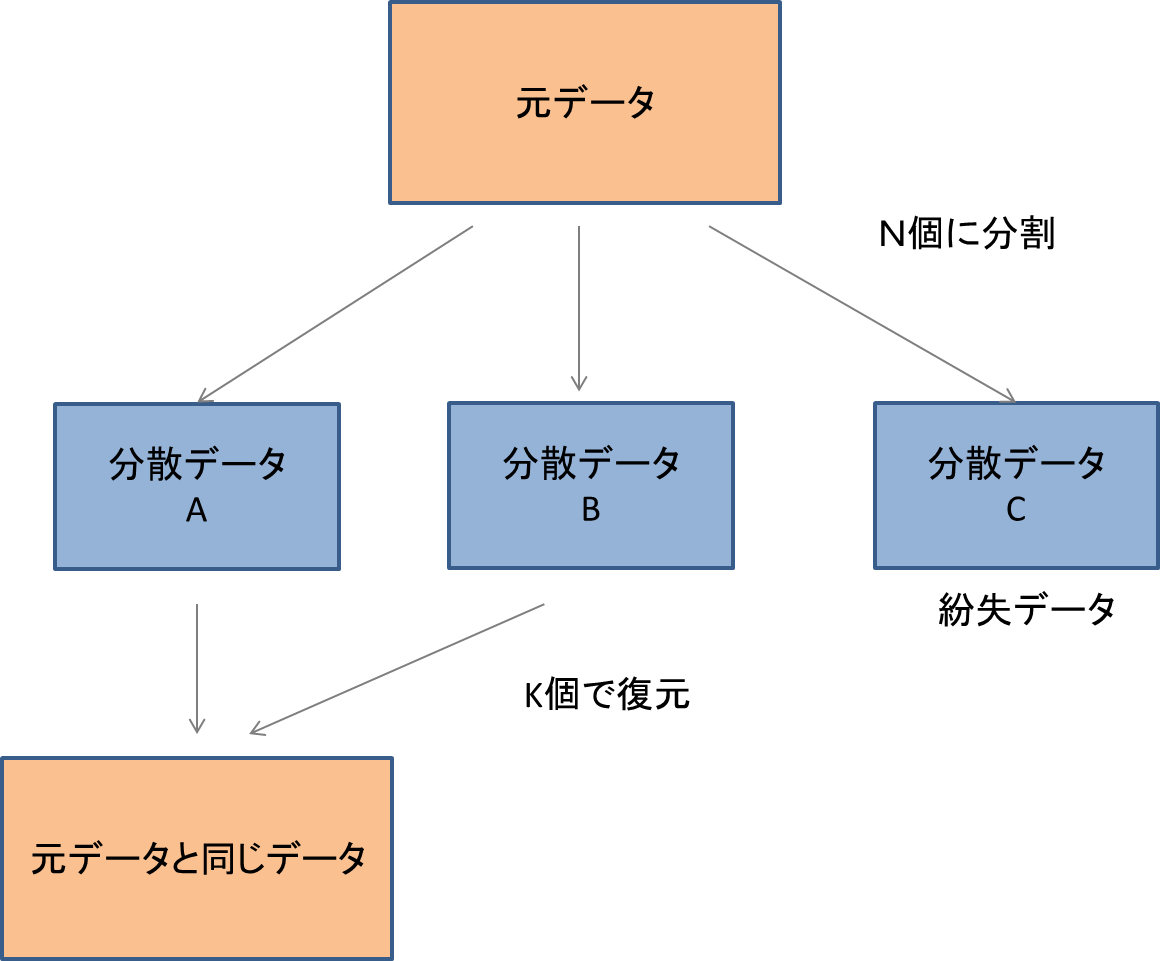
4.3秘密分散に関する研究
医療、金融、行政などのシッションクリティカルかつセーフクリティカルな業務においては、安全かつ堅牢なストレージシステムは必要である。RAIDに代表される従来のストレージシステムでは、たかだか数台のディスク故障に対するデータの保存性を保証するだけであり、ディスクコントローラの故障や、コンピューターの故障に対するデータの保存性は保証していない。悪意を持った侵入者に対するデータの秘匿性については、オペレーティングシステムにすべてを依存しているため、十分な秘匿性を保証しているとはいいがたい。論文では秘密分散技術を用いてデータの暗号化を行うファイルシステムを提案された。
暗号化鍵が分かればデータの複号できるため、暗号化鍵が第三者に知れてしまった場合データが取られてしまう危険がある。データ自体を分散配置させているわけてはないので、暗号化されたデータはネットワークに一つしかない。したがってディスクの故障などによりデータを紛失するおそれがあり、頑健性が重要視されるようなシステムにおいては適しているとはいいがたい。ディスクの故障や、ネットワークの不通、データの改ざんなど想定されるあらゆる事故、攻撃に対してより頑健で秘匿性の高いストレージシステムの開発が必要であると考えられる。
5日本語処理ツール
5.1自然言語の処理
自然言語処理は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術である。データベース内の情報を自然言語に変換したり、自然言語の文章をより形式的な表現に変換するといった処理が含まれる。自然言語処理の基礎技術にはさまざまなものがある。自然言語処理はその性格上、扱う言語によって大きく処理の異なる部分がある。現在のところ、日本語を処理する基礎技術としては以下のものが主に研究されている。
形態素解析
文章を意味のある単語に区切り、辞書を利用して品詞や内容を判別すること。かな漢字変換や、機械翻訳などに用いられる。コンピュータによる自然言語処理技術の一つ。
形態素とは、文章の要素のうち、意味を持つ最小の単位である。英語の文“I love you.”では、“I”、“love”、“you”がそれぞれ形態素に当たる。この時、“l”や“o”などのアルファベットは、それのみでは意味を持たないため、形態素とは呼ばない。英語では原則として文章を単語ごとに区切って書く(分かち書き)ため、形態素ごとに分割することは容易である。
一方、日本語では単語ごとに区切らず続けて書くために、形態素ごとの分割が難しい。例えば、かな漢字変換の場合には、ひらがなのみで与えられた文章を区切る必要があるが、これは辞書を引きながら、色々な区切り方を試していくことになる。
この時、辞書にある名詞を形態素として区切ったり、前後の品詞を見て文法的におかしい区切り方は省くなどの処理をするが、複数の解釈が可能な文章もあり、区切り方を一意に決定することはなかなか難しい。特に長文になるほど区切り方の解釈が複雑になるため、ユーザの意図しない漢字変換をしてしまうことが増える。
構文解析
構文解析とは、単語や字句で構成される文を、定義された文法に従って解釈し、文の構造を明確にすることである。
プログラムのソースコードをコンピュータが理解できるようにコンパイルする際は、まず字句解析により、ソースコードをトークンと呼ばれる要素に切り出した後に、構文規則に基づいて構文解析が行われる。構文解析の手法には、上向き解析と下向き解析があり、演算子順位解析は上向き構文解析、LL解析は下向き構文解析である。
英語を日本語に変換する機械翻訳の分野では、英語の構文解析を行い、構文木で解析結果を表現した後に日本語の構文木に変換し、日本語訳を作り出す。
語義の曖昧性解消
語義の曖昧性解消とは、自然言語処理において、文書や発話などの中で出現した特定の単語やフレーズなどが、その文脈の中ではどのような意味で使われているのかを判別する技術、またはその処理のことである。
照応解析
照応解析とは、照応詞(代名詞や指示詞など)の指示対象を推定したり、省略された名詞句(ゼロ代名詞)を補完する処理のこと。照応は文と文の間にまたがった構造なので、照応解析は談話解析の一種である。
5.2形態素解析器 とIPA辞書
MeCab
MeCabは 京都大学情報学研究科−日本電信電話株式会社コミュニケーション科学基礎研究所 共同研究ユニットプロジェクトを通じて開発されたオープンソース 形態素解析エンジンである。各言語用バインディングを使うことで Ruby や Python をはじめ多くのさまざまなプログラミング言語から呼び出して利用することもでき大変便利である。MeCab の仕組みとしては、対象言語の文法の知識を形態素解析用「辞書」 (品詞等の情報付きの単語リスト) という形で用意しこれをもとに自然言語を分解、品詞を判定します。
IPA 辞書, IPAコーパス に基づき CRF でパラメータ推定した辞書である。
7.2.3 結果の比較
学習資料収集結果に基づく、実験を再度行った。今回の実験では、分類器を二つ用意した。結果は図に示す。