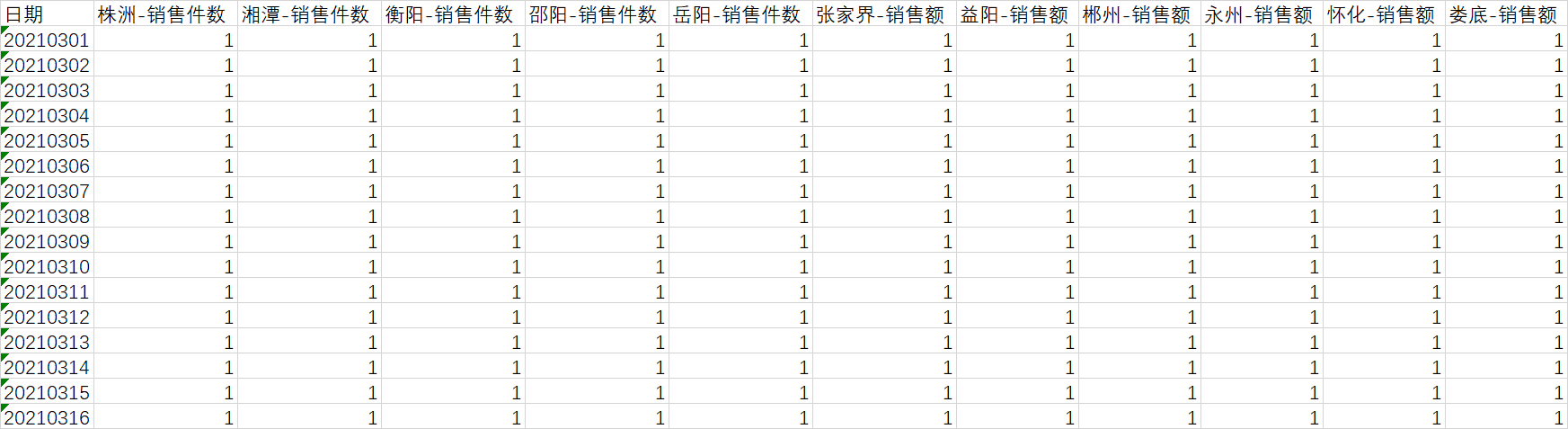
问题:数据格式这个样子
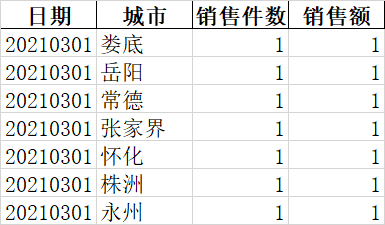
处理成:
这个刚开始给我确实造成了不少困扰,公司的SB 系统。 不给数据库的编辑权限。数据权限保密,本来很简单的事,搞复杂化了。 没办法,我只有手动写下,处理下本地excel 。不给自己添加工作量。 我一开始没想好这么写,还好有个人博主挺秀的。 写的差不多。
https://www.cnblogs.com/traditional/p/11967360.html
首先通过melt 函数,实现列转行。
melt里面的几个参数:
frame: 第一个参数, 接收一个DataFrame, 这没有什么好说的id_vars: 第二个参数, 不需要进行列转行的字段,value_vars: 第三个参数, 需要进行列转行的字段var_name: 第四个参数, 我们说列转行之后会生成两个列, 第一个列存储的值是"列转行之前的列的列名",第二个列存储的值是"列转行之前的列的值"。但是生成的两个列总要有列名吧,所以var_name就是生成的第一个列的列名value_name: 生成的第二个列的列名col_level: 针对于具有二级列名的DataFrame, 这个一般可以不用管
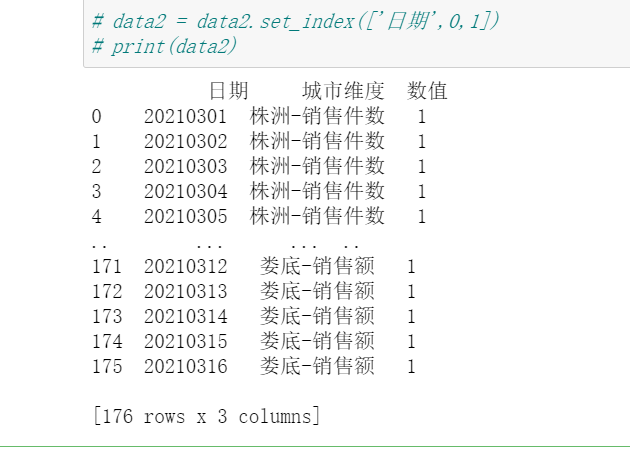
# _*_coding:utf-8 _*_ import pandas as pd import numpy as np # import os # import time path = r"C:Users1Desktop工作202106练习文件处理数据.xlsx" data = pd.read_excel(path) data1= pd.melt(data,id_vars=['日期'],var_name="城市维度", value_name="数值") print(data1)
处理后结果
2 接着分列处理。
# 总算对了,设置两级索引。这样就不会变 data1 = data1.set_index(['日期','数值'] )["城市维度"].str.split("-", expand=True) print(data1)
设置索引之后不会变更,然后根据城市拆分。

3 重置索引
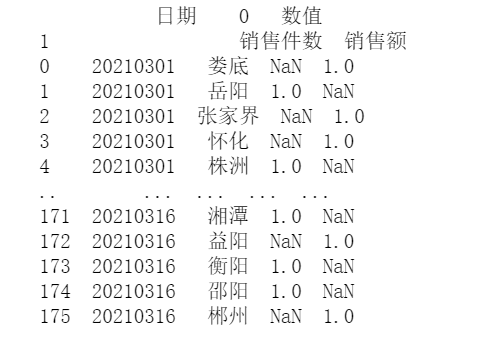
data2 = data1.reset_index() print(data2) data2 = data2.set_index(['日期',0,1]) print(data2)
处理结果。

接下来就很简单了,我只需要把这个行销售额,销售件数,给变成列就欧克,
4 行转列
data4 = data2.unstack() print(data4) data4= data4.reset_index().rename_axis() print(data4) data4.to_excel(r"C:Users1Desktop工作202106练习文件处理数据123.xlsx")
最后结果,得到我们想要的。
参考链接:https://www.cnblogs.com/traditional/p/11967360.html
不常用,就随便写了。没有很好的规范。写成类什么的。
其中遇到最多的卡点,居然是保存文件,格式,各种报错。然后就是时间,总不能每次手改趴。 还好解决了。节约时间。
完整代码:
# _*_coding:utf-8 _*_
import pandas as pd
import numpy as np
import os
import time
# 这个可以写成一个类,保存文件,获取文件的初始化类。
path = r"C:Users1Desktop工作202106练习文件"
path1 = r"C:Users1Desktop工作202106save"
# 当前时间格式,很有用。
tim = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
filenames = os.listdir(path)
df = pd.DataFrame()
for i in filenames:
# print (path + '\'+ i ) -- 验证地址
data = pd.read_excel(path + '\' + i)
df = df.append(data)
data1 = pd.melt(df, id_vars=['日期'], var_name="城市维度", value_name="数值")
# 总算对了,设置两级索引。这样就不会变。 设置索引 。固定日期和值
data1 = data1.set_index(['日期', '数值'])
# 根据字符切割,故意写开 。其实可以这样写 data1 = data1.set_index(['日期', '数值'])["城市维度"].str.split("-", expand=True)
data1 = data1["城市维度"].str.split("-", expand=True)
# 重置索引,四个都有索引,列转行了。
data2 = data1.reset_index()
# 再度设置索引,需要将指标行转列。
data2 = data2.set_index(['日期', 0, 1])
# 行转列,使用unstack方法。默认是最后一列变为列。 最后一列是指标 。
# 这里的level默认是-1, 表示将最后一级的索引变成列
# # 这里我们不用指定(注意: 索引从0开始), 告诉pandas, 把第一级索引变成列
data4 = data2.unstack()
# 重置索引
data4 = data4.reset_index().rename_axis()
# 地址
addres = path1 + '\' + 'x' + tim + '.xlsx'
print(addres)
data4.to_excel(addres)