在上一篇随笔《Java爬虫系列二:使用HttpClient抓取页面HTML》中介绍了怎么使用HttpClient进行爬虫的第一步--抓取页面html,今天接着来看下爬虫的第二步--解析抓取到的html。
有请第二步的主角:Jsoup粉墨登场。下面我们把舞台交给Jsoup,让他完成本文剩下的内容。
============华丽的分割线=============
一、Jsoup自我介绍
大家好,我是Jsoup。
我是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据,用Java写爬虫的同行们十之八九用过我。为什么呢?因为我在这个方面功能强大、使用方便。不信的话,可以继续往下看,代码是不会骗人的。
二、Jsoup解析html
上一篇中,HttpClient大哥已经抓取到了博客园首页的html,但是一堆的代码,不是程序员的人们怎么能看懂呢?这个就需要我这个html解析专家出场了。
下面通过案例展示如何使用Jsoup进行解析,案例中将获取博客园首页的标题和第一页的博客文章列表
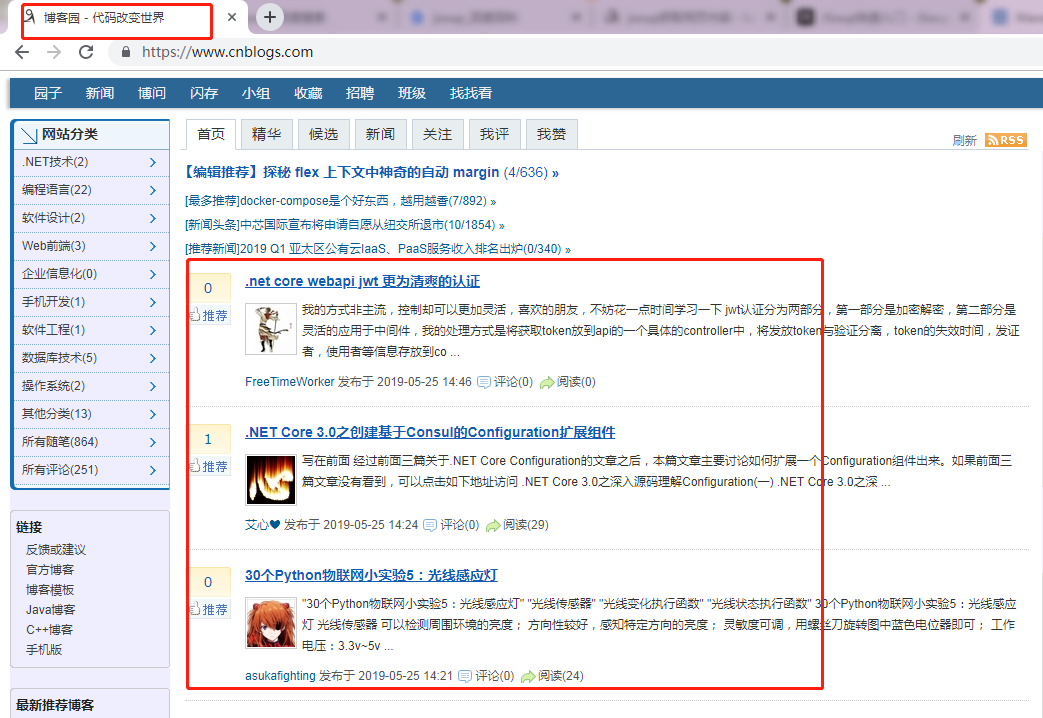
请看代码(在上一篇代码的基础上进行操作,如果还不知道如何使用httpclient的朋友请跳转页面进行阅读):
- 引入依赖
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.12.1</version> </dependency>
- 实现代码。实现代码之前首先要分析下html结构。标题是<title>不用说了,那文章列表呢?按下浏览器的F12,查看页面元素源码,你会发现列表是一个大的div,id="post_list",每篇文章是小的div,class="post_item"
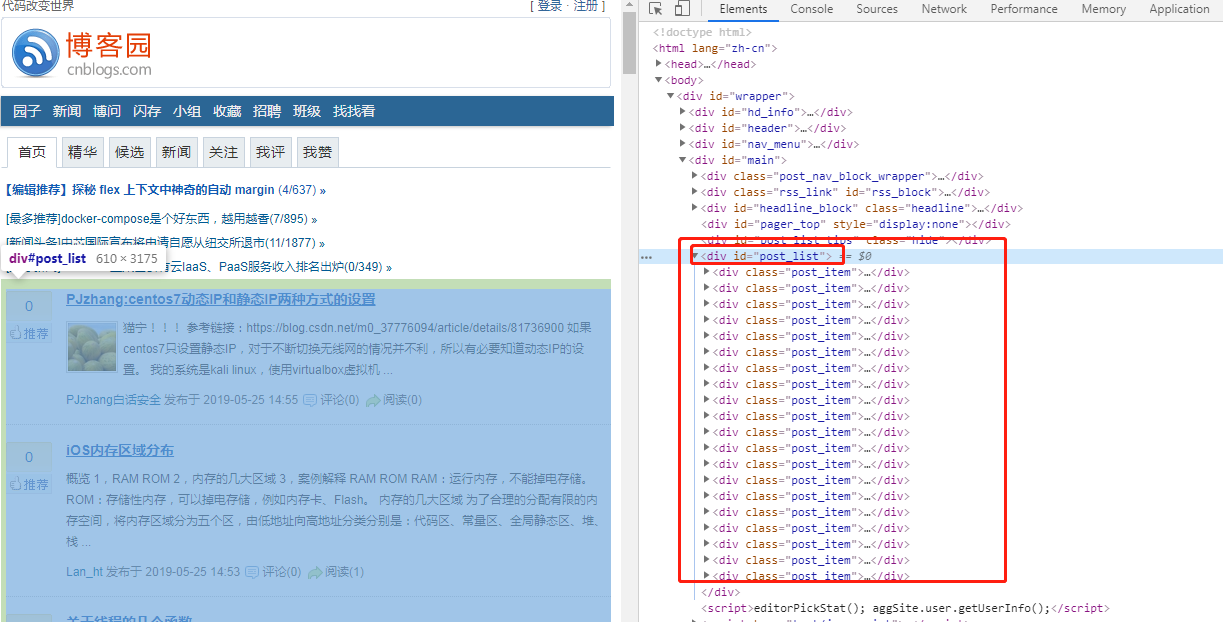
接下来就可以开始代码了,Jsoup核心代码如下(整体源码会在文章末尾给出):
/** * 下面是Jsoup展现自我的平台 */ //6.Jsoup解析html Document document = Jsoup.parse(html); //像js一样,通过标签获取title System.out.println(document.getElementsByTag("title").first()); //像js一样,通过id 获取文章列表元素对象 Element postList = document.getElementById("post_list"); //像js一样,通过class 获取列表下的所有博客 Elements postItems = postList.getElementsByClass("post_item"); //循环处理每篇博客 for (Element postItem : postItems) { //像jquery选择器一样,获取文章标题元素 Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']"); System.out.println("文章标题:" + titleEle.text());; System.out.println("文章地址:" + titleEle.attr("href")); //像jquery选择器一样,获取文章作者元素 Elements footEle = postItem.select(".post_item_foot a[class='lightblue']"); System.out.println("文章作者:" + footEle.text());; System.out.println("作者主页:" + footEle.attr("href")); System.out.println("*********************************"); }
根据以上代码你会发现,我通过Jsoup.parse(String html)方法对httpclient获取到的html内容进行解析获取到Document,然后document可以有两种方式获取其子元素:像js一样 可以通过getElementXXXX的方式 和 像jquery 选择器一样通过select()方法。 无论哪种方法都可以,我个人推荐用select方法处理。对于元素中的属性,比如超链接地址,可以使用element.attr(String)方法获取, 对于元素的文本内容通过element.text()方法获取。
- 执行代码,查看结果(不得不感慨博客园的园友们真是太厉害了,从上面分析首页html结构到Jsoup分析的代码执行完,这段时间首页多了那么多文章)
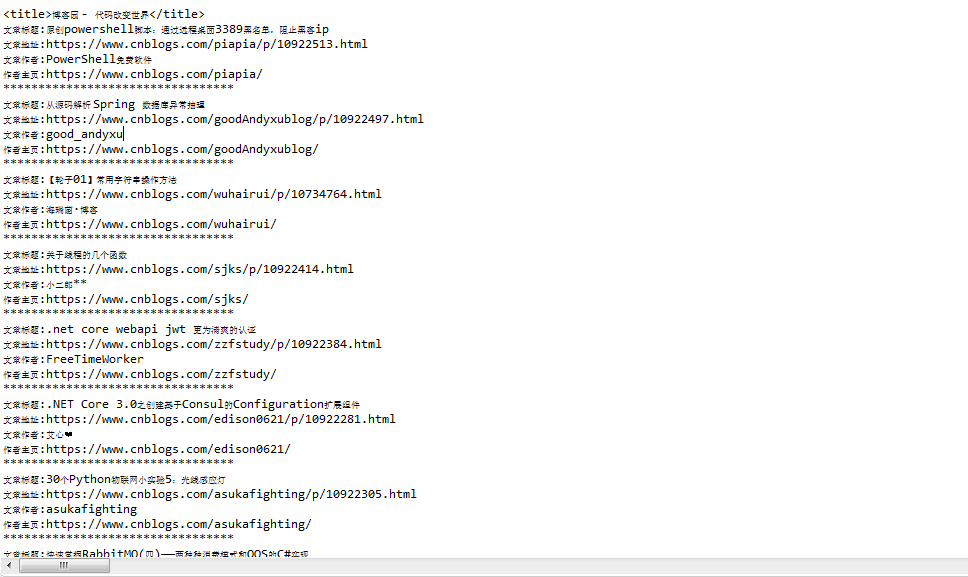
由于新文章发布的太快了,导致上面的截图和这里的输出有些不一样。
三、Jsoup的其他用法
我,Jsoup,除了可以在httpclient大哥的工作成果上发挥作用,我还能自己独立干活,自己抓取页面,然后自己分析。分析的本领已经在上面展示过了,下面来展示自己抓取页面,其实很简单,所不同的是我直接获取到的是document,不用再通过Jsoup.parse()方法进行解析了。

除了能直接访问网上的资源,我还能解析本地资源:
代码:
public static void main(String[] args) { try { Document document = Jsoup.parse(new File("d://1.html"), "utf-8"); System.out.println(document); } catch (IOException e) { e.printStackTrace(); } }
四、Jsoup另一个值得一提的功能
你肯定有过这种经历,在你的页面文本框中,如果输入html元素的话,保存后再查看很大概率会导致页面排版乱七八糟,如果能对这些内容进行过滤的话,就完美了。
刚好我Jsoup就能做到。
public static void main(String[] args) { String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a></p>"; System.out.println("unsafe: " + unsafe); String safe = Jsoup.clean(unsafe, Whitelist.basic()); System.out.println("safe: " + safe); }
通过Jsoup.clean方法,用一个白名单进行过滤。执行结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a></p>
safe: <p><a rel="nofollow">博客园</a></p>
五、结束语
通过以上大家相信我很强大了吧,不仅可以解析HttpClient抓取到的html元素,我自己也能抓取页面dom,我还能load并解析本地保存的html文件。
此外,我还能通过一个白名单对字符串进行过滤,筛掉一些不安全的字符。
最最重要的,上面所有功能的API的调用都比较简单。
============华丽的分割线=============
码字不易,点个赞再走呗~~
最后,附上案例中 解析博客园首页文章列表的完整源码:


package httpclient_learn; import java.io.IOException; import org.apache.http.HttpEntity; import org.apache.http.HttpStatus; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.client.utils.HttpClientUtils; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class HttpClientTest { public static void main(String[] args) { //1.生成httpclient,相当于该打开一个浏览器 CloseableHttpClient httpClient = HttpClients.createDefault(); CloseableHttpResponse response = null; //2.创建get请求,相当于在浏览器地址栏输入 网址 HttpGet request = new HttpGet("https://www.cnblogs.com/"); //设置请求头,将爬虫伪装成浏览器 request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"); // HttpHost proxy = new HttpHost("60.13.42.232", 9999); // RequestConfig config = RequestConfig.custom().setProxy(proxy).build(); // request.setConfig(config); try { //3.执行get请求,相当于在输入地址栏后敲回车键 response = httpClient.execute(request); //4.判断响应状态为200,进行处理 if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) { //5.获取响应内容 HttpEntity httpEntity = response.getEntity(); String html = EntityUtils.toString(httpEntity, "utf-8"); System.out.println(html); /** * 下面是Jsoup展现自我的平台 */ //6.Jsoup解析html Document document = Jsoup.parse(html); //像js一样,通过标签获取title System.out.println(document.getElementsByTag("title").first()); //像js一样,通过id 获取文章列表元素对象 Element postList = document.getElementById("post_list"); //像js一样,通过class 获取列表下的所有博客 Elements postItems = postList.getElementsByClass("post_item"); //循环处理每篇博客 for (Element postItem : postItems) { //像jquery选择器一样,获取文章标题元素 Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']"); System.out.println("文章标题:" + titleEle.text());; System.out.println("文章地址:" + titleEle.attr("href")); //像jquery选择器一样,获取文章作者元素 Elements footEle = postItem.select(".post_item_foot a[class='lightblue']"); System.out.println("文章作者:" + footEle.text());; System.out.println("作者主页:" + footEle.attr("href")); System.out.println("*********************************"); } } else { //如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略 System.out.println("返回状态不是200"); System.out.println(EntityUtils.toString(response.getEntity(), "utf-8")); } } catch (ClientProtocolException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { //6.关闭 HttpClientUtils.closeQuietly(response); HttpClientUtils.closeQuietly(httpClient); } } }