目录
Django(三) django生命周期,路由层
orm表关系如何建立
#先导入django中的models模块
from django.db import models
#先不考虑外键关系,创建基表
class Book(models.Model):
titile = models.CharField(max_length = 32) #CharField字段一定要设置max_length
#小数总共八位,小数点后占两位
price = models.DecimalField(max_digits=8,decimal_places=2)
# to用来指代跟哪张表有关系 默认关联的就是表的主键字段
publish_id = models.ForeignKey(to='Publish')
'''
一对多外键字段,同步到数据中心后,表字段会自动加_id后缀
如果手动加上_id,同步之后,还是会自动加上另一个_id
'''
#书和作者是多对多的关系,外键字段可以建在任意一方,一般建在查询频率高的一方
#django orm会自动创建书籍和作者的第三张关系表
#author该字段是一个虚拟字段,不能在表中展示出来,仅是起到一个高速orm,在建第三张表的关系起到作用
author = models.ManytoManyField(to='Author')
class Publish(models.Model):
title = models.CharField(max_length=32)
email = models.EmailField()
class Author(models.Model):
name = models.CharField(max_length=32)
email = models.EmailField()
#一对一的表关系,外键字段建在任意一方都可以,一般建在查询频率高的一方
author_detail = models.OneToOneField(to='Author_detail')
class Author_detail(models.Model):
phone = models.BigIntegerField()
addr = models.CharField(max_length=32)
django请求生命周期流程图
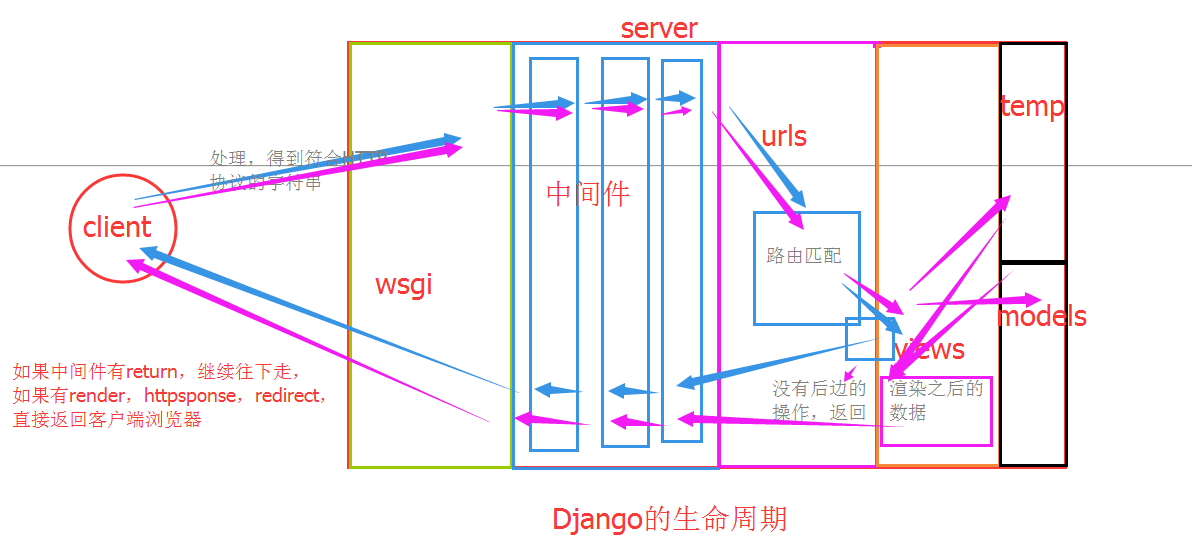
urls.py路由层
url的第一个参数是一个正则表达式,只要是该正则表达式能够匹配到内容,就会立刻执行后面的视图韩式,而不再往下继续匹配了
from django.conf.urls import url
urlpatterns = [
url(正则表达式, views视图函数,参数,别名),
]
路由匹配
#不加斜杠,会先匹配一次,如果匹配不上,Django可以让浏览器在url后自动加斜杠
#取消该功能
APPEND_SLASH = False # 该参数默认是True
无名分组
#将分组内正则表达式匹配到的内容当做位置参数传递给视图函数
url(r'^test/([0-9]{4})/', views.test)
#当路由中有分组的正则表达式,在匹配到内容,执行视图函数的时候,会将分组内正则表达式匹配的把内容当做位置参数传给视图函数
有名分组
会将分组内的正则表达式匹配到的内容当做关键字参数传递给视图函数
#语法
url(r'^testadd/(?P<year>d+)',views.testadd)
# 当你的路由中有分组并且给分组起了别名 那么在匹配内容的时候
# 会将分组内的正则表达式匹配到的内容当做关键字参数传递给视图函数 testadd(request,year=分组内的正则表达式匹配到的内容)
有名分组和无名分组不能混合使用!
反向解析
根据别名,动态解析出一个结果,该结果可以直接访问对应的url
第一种情况
#路由中没有正则表达式 直接是写死的
url(r'^home/', views.home,name='xxx'), # 给路由与视图函数对应关系起别名
#前端反向解析
{% url 'xxx' %}
#后端反向解析
from django.shortcuts import reverse
url = reverse('xxx')
第二种情况
#无名分组的反向解析 在解析的时候 你需要手动指定正则匹配的内容是什么
url(r'^home/(d+)/', views.home,name='xxx'), # 给路由与视图函数对应关系起别名
#前端反向解析
<p><a href="{% url 'xxx' 12 %}">111</a></p>
<p><a href="{% url 'xxx' 1324 %}">111</a></p>
<p><a href="{% url 'xxx' 14324 %}">111</a></p>
<p><a href="{% url 'xxx' 1234 %}">111</a></p>
#后端反向解析
url = reverse('xxx',args=(1,))
url1 = reverse('xxx',args=(3213,))
url2 = reverse('xxx',args=(2132131,))
# 手动传入的参数 只需要满足能够被正则表达式匹配到即可
第三种情况
#有名分组的反向解析 在解析的时候 你需要手动指定正则匹配的内容是什么
#有名分组的反向解析可以跟无名分组一样
#但是最最正规的写法
url(r'^home/(?P<year>d+)/', views.home,name='xxx'), # 给路由与视图函数对应关系起别名
#前端
# 可以直接用无名分组的情况
<p><a href="{% url 'xxx' 12 %}">111</a></p>
# 你也可以规范写法
<p><a href="{% url 'xxx' year=1232 %}">111</a></p> # 了解即可
#后端
# 可以直接用无名分组的情况
url = reverse('xxx',args=(1,))
# 你也可以规范写法
url = reverse('xxx',kwargs={'year':213123})
#以编辑功能为例
url(r'^edit_user/(d+)/',views.edit_user,name='edit')
def edit_user(request,edit_id):
# edit_id就是用户想要编辑数据主键值
pass
{% for user_obj in user_list %}
<a href='/edit_user/{{user_obj.id}}/'>编辑</a>
<a href='{% url 'edit' user_obj.id %}'>编辑</a>
{% endfor %}
路由分发
路由分发的前因:
在django中所有的app都可以有自己独立的urls.py templates static
路由分发解决的就是项目的总路由匹配关系过多的情况
使用路由分发,会将总路由不再做匹配的活,而仅仅是做任务分发(请求来了之后,总路由不做对应关系)只询问你要访问哪个app的功能 然后将请求转发给对应的app去处理
urlpatterns = [
url(r'^admin/', admin.site.urls), # url第一个参数是一个正则表达式
# 路由分发
url(r'^app01/',include(app01_urls)), # 路由分发需要注意的实现 就是总路由里面不能以$结尾
url(r'^app02/',include(app02_urls)),
]
# 子路由
from django.conf.urls import url
from app01 import views
urlpatterns = [
url('^reg/',views.reg)
]
from django.conf.urls import url
from app02 import views
urlpatterns = [
url('^reg/',views.reg)
]
#最省事的写法(******)
url(r'^app01/',include('app01.urls')),
url(r'^app02/',include('app02.urls'))
名称空间
当多个app中出现了起别名冲突的情况,在做路由分发的时候,可以给每一个app创建一个名称空间,然后在反向解析的时候,可以选择到底去哪个名称空间中查找别名
url(r'^app01/',include('app01.urls',namespace='app01')),
url(r'^app02/',include('app02.urls',namespace='app02'))
# 后端
print(reverse('app01:reg'))
print(reverse('app02:reg'))
# 前端
<a href="{% url 'app01:reg' %}"></a>
<a href="{% url 'app02:reg' %}"></a>
#使用名称空间会开辟内存资源,占空间
#其实上面的名称空间知识点可以完全不用,你只需要保证起别名的时候 在整个django项目中不冲突即可
起别名的时候统一加上应用名前缀
urlpatterns = [
url(r'^reg/',views.reg,name='app02_reg')
]
urlpatterns = [
url('^reg/',views.reg,name='app01_reg')
]
伪静态
将一个动态网页伪装成一个静态网页 以此来挺好搜索引擎SEO查询频率和搜藏力度
所谓的搜索引擎其实就是一个也别巨大的爬虫程序
url(r'^app01.html',include('app01.urls')),
虚拟环境
给每一个项目 装备该项目所需要的模块 不需要的模块一概不装
每创建一个虚拟环境就类似于你重新下载了一个纯净python解释器
之后该项目用到上面 你就装什么(虚拟环境一台机器上可以有N多个)
django版本区别
urls.py中路由匹配的方法有区别
django2.X用的是path
urlpatterns = [
path('admin/', admin.site.urls),
]
django1.X用的是url
urlpatterns = [
url(r'^reg.html',views.reg,name='app02_reg')
]
# 区别 django2.X里面path第一个参数不是正则也不支持正则 写什么就匹配什么
# 虽然path不支持正则 感觉也好用 django2.X还有一个re_path的方法 该方法就是你django1.X里面url
# 虽然path支持 但是它提供了五种转换器 能够将匹配到的数据自动转黄成对应的类型
# 除了有默认五种转换器之外 还支持你自定义转换器
涉及知识点梳理
mysql数据库之表与表之间的关系
一对多
foreign key
外键约束
1. 在创建表的时候,必须先创建被关联表
2. 插入数据的时候,也必须先插入被关联表的数据
如员工表和部门表之间就是一对多的关系,通常将关键字段称之为外键字段
外键建在多的一方
多对多
以图书表和作者表举例(换位思考)
1. 先站在图书表:多本书能否是一个作者
2. 站在作者表中:多个作者能否共同编写一本书
如果双方都成立,那么就是多对多
多对多关系的建立,必须手动创建第三张表,专门用来记录两种表之间的关系
一对一
一对一关系对较少,一般当表特别庞大时,可以拆分表
比如客户信息,与详细信息表
外键字段可以建在任意一方,一般建在查询频率高的一方
re模块(正则表达式)
re模块:去字符串找符合某种特点的字符串
import re
s = 'abcdabc'
#^ :以...开头
res = re.findall('^ab',s)
#$ :以...结尾
res = re.findall('bc$',s)
# . :任意字符
res = re.findall('abc',s)
# d :数字
res = re.findall('d',s)
# w :非空,数字字母下划线
res = re.findall('w',s)
# s :空,空格
res = re.findall('s',s)
# D:非数字
res = re.findall('D',s)
# W:空
res = re.findall('W',s)
#S :非空
res = re.findall('S',s)
# + :前面的一个字符至少一个
print(re.findall('abc+',s))
# ? :寻找到?前面的一个字符 0-1 个
print(re.findall('abcdd?', s))
# * :前面的一个字符至少0个
print(re.findall('abcd*',s))
# [] :中括号内的都可以
print(re.findall('[abc]bc',s))
# [^] :中括号内的都不可以
print(re.findall('[^abc]bc',s))
# | : 或
print(re.findall('abc|bbc',s))
# {2}:前面的字符 2个
print(re,findall('abc{2}',s))
# {1,2} :前面的字符 2 个
print(re,findall('abc{1,2}',s))
#贪婪模式
# .(任意字符) * (0-无穷个)
print(re.findall('a.*g',s))
#非贪婪模式
# . (任意字符) * (0-无穷个)
print(re,findall('a.*?g',s))
#bug # . (任意字符) * (0-无穷个)
print(re.findall('.*?',s))