简介
通常,进行文本分类的主要方法有三种:
- 基于规则特征匹配的方法(如根据喜欢,讨厌等特殊词来评判情感,但准确率低,通常作为一种辅助判断的方法)
- 基于传统机器学习的方法(特征工程 + 分类算法)
- 给予深度学习的方法(词向量 + 神经网络)
自BERT提出以来,各大NLP比赛基本上已经被BERT霸榜了,但笔者认为掌握经典的文本分类模型原理还是十分有必要的。这一节,将对一些经典模型进行介绍,并在我的github中给出部分模型的实现。
TextRNN
之前介绍过词向量以及三大特征提取器,这里就不再赘述了,深度学习模型无非就是用特征抽取器拼接起来的不同结构的神经网络模型,所以接下来的几个部分基本是对模型结构的简介。
首先我们来看看用经典的LSTM/GRU实现文本分类模型的基本结构:
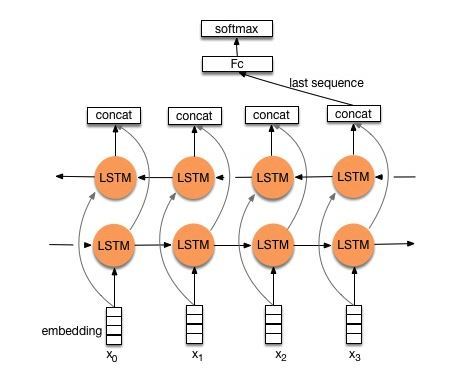
由上图可知,TextRNN仅仅是将Word Embedding输入到双向LSTM中,然后对最后一位的输出输入到全连接层中,在对其进行softmax分类即可。
TextCNN
对于TextCNN在上一篇文章中简单的提到过,这里再做一些简单的补充,其模型结构如下图所示:
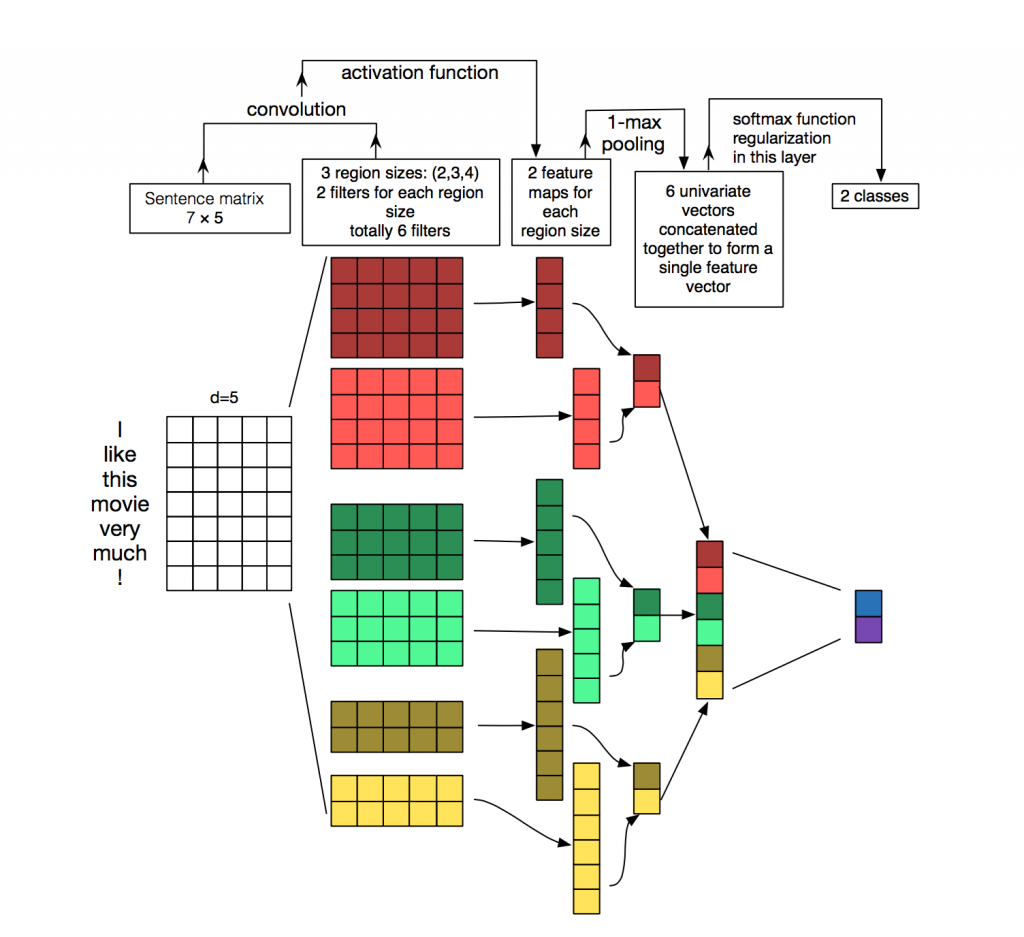
上图很直观的展现了,与图像中的二维卷积不同,TextCNN中采用的是一维卷积,每个卷积核的大小为(h imes k)(h为卷积核的窗口大小,k为词向量的维度),文中采用了多种不同尺寸的卷积核,用以提取不同文本长度的特征(上图种可以看见,卷积核有h=2, 3, 4三种)
然后,作者对于卷积核的输出进行MaxPooling,目的是提取最重要的特征。将所有卷积核的输出通过MaxPooling之后拼接形成一个新向量,再将该向量输出到全连接层分类器(Dropout + Linear + Softmax)实现文本分类。
TextRCNN
这篇论文中描述稍微复杂了点,实际模型非常简单,该模型结构如下图所示:
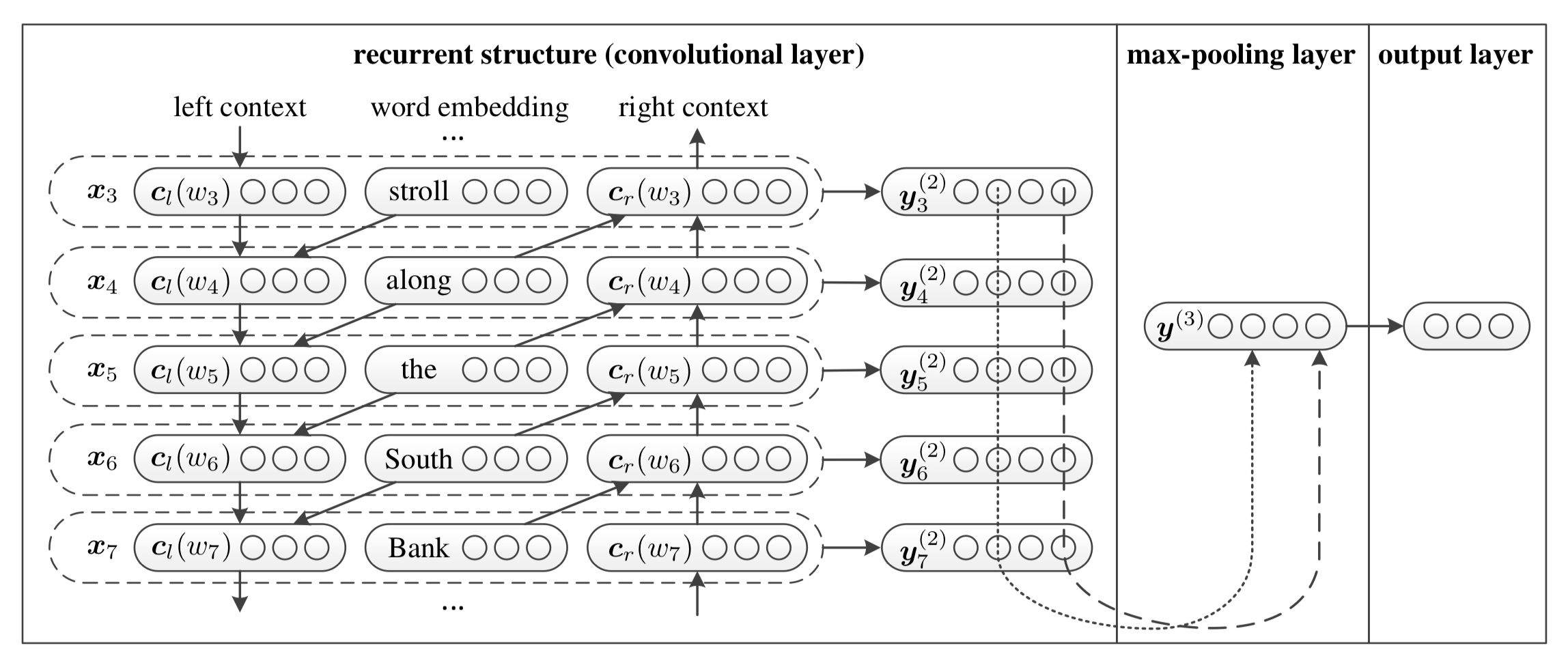
该模型的主要思想如下:
- 首先获得词向量表示(e(w_i))
- 其次将词向量通过双向RNN(实践中可以是LSTM或GRU)得到(c_l(w_i))和(c_r(w_i))
- 将(c_l(w_i)), (e(w_i))以及(c_r(w_i))拼接得到新的向量,将其输入到全连接网络对其进行整合,激活函数为tanh
- 再将全连接网络的输出进行MaxPooling
- 最后将其输入一个全连接分类器中实现分类
FastText
FastText是Facebook于2016年发布的文本分类模型,其主要思想基于word2vec中的skip-gram模型(关于skip-gram模型参考我之前词向量的博客,这里也就不再赘述),在训练文本分类模型的同时,也将训练出字符级n-gram词向量。
通常认为,形态类似的单词具有相似的语义特征。而对于Word2Vec模型,其构建的语料库中,把不同的单词直接映射到独立的id信息,这样,使得不同单词之间的形态学信息完全丢失了,如英文中的“nation”和“national”,中文中的“上海市政府”和“上海市”。如果能够学习到形态学变换到单词特征的规则,我们可以利用这个规则来得到许多训练集中不可见的单词表示。
为了解决这个问题,FastText用字符级别的n-gram来表示一个单词或句子,如
中华人民共和国
bigram:中华 华人 人民 民共 共和 和国
trigram:中华人 华人民 人民共 民共和 共和国
得到了词的n-gram表征之后,我们可以用n-gram子词(subword)的词向量叠加来表示整个词语,词典则是所有词子词的并集。
其主要模型结构如下图所示,最后也采用了层次softmax的提速手段:
对比skip-gram模型,可以FastText的词典规模会更大,模型参数会更多。但每一个词的词向量都是子词向量的和,使得一些生僻词或未出现的单词能够从形态相近的单词中得到较好的词向量表示,从而在一定程度上能够解决OOV问题
HAN
HAN的全称为Hierarchical Attention Network(分级注意网络),从字面意思就可以理解其是一个分层架构模型。该模型主要用于文档分类(长文本分类),其主要结构如下所示:
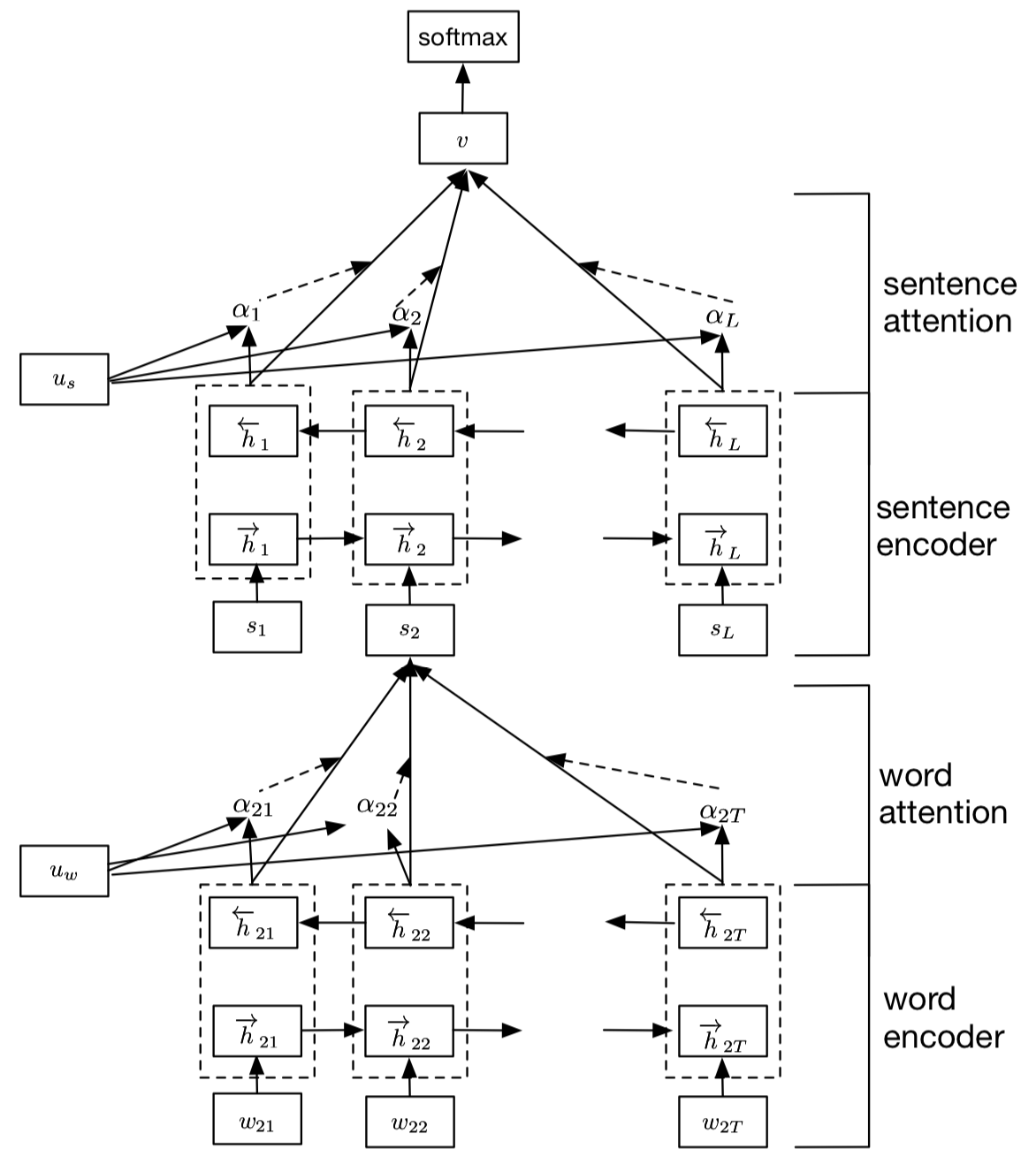
HAN主要由两个层次的模型架构:词级别和句级别,每个层次的模型都包括一个编码器和注意力模型两个部分,整个模型的细节如下:
- 如上图所示,假设我们的文档中有(L)个句子,对于第二个句子,单词长度为(T)
- 首先将单词输入Embedding层获取词向量
- 将获取的词向量输入词编码器,即一个双向GRU,将两个方向的GRU输出拼接在一起得到词级别的隐向量(h)
- 将词级别的隐向量通过一个单层感知机(MLP,实际上就是全连接神经网络,激活函数选用tanh),输出的结果可以看作是更高层次的隐向量表示:
(u_{it}=tanh(W_wu_{it}+b_w)) - 随机初始化一个上下文向量(u_w)(随着训练不断优化),将该上下文向量(u_w)与高层次的隐向量表示(u_{it})输入softmax,得到每个词与上下文向量的相似度表示:
(alpha_{it}=frac{exp(u_{it}^Tu_w)}{sum_texp(u_{it}^Tu_w)}) - 将上述相似度作为权重,对(h_{it})加权求和得到句子级别的向量表示:
(s_i=sum_talpha_{it}h_{it}) - 对于句子级别的向量,我们用相类似的方法,将其通过编码层,注意力层,最后将文档中所有句子的隐向量表示加权求和,得到整个文档的文档向量(v),将该向量通过一个全连接分类器进行分类。
其实HAN中使用到的的Attention就是最常用的 Soft-Attention ,整个模型的结构就相当于TextRNN + Soft-Attention的叠加。,分别用来处理词级别和句子级别,对于短文本分类,我们只需借鉴词级别的模型即可。
Highway Networks
门限神经网络(Gated Networks),在之前一篇文章中也提到过,主要是利用(sigmoid)函数“门限”的性质,来实现对信息流的自动控制的一种方法,Highway Networks就是一种典型的门限网络结构,这里也简单的介绍一下。
根据原文的定义,假设原来网络的输出为:
其中(H(·))表示非线性变换(可以设置为激活函数为relu的全连接层)。定义(T(x, W_T) = sigmoid(W_T^Tx + b_T))文章的做法就是将其改进为:
则对于输出y,有:
参考链接
https://blog.csdn.net/zhangph1229/article/details/52106301
https://www.kesci.com/home/project/5be7e948954d6e0010632ef2
https://zhuanlan.zhihu.com/p/32091937
https://zhuanlan.zhihu.com/p/64603089
https://zhuanlan.zhihu.com/p/24780258
https://zhuanlan.zhihu.com/p/32965521
https://zhuanlan.zhihu.com/p/63111928
https://zhuanlan.zhihu.com/p/53342715
https://zhuanlan.zhihu.com/p/44776747