一、算术运算符
1.算术运算符有 +(加)、-(减)、*(乘)、/(除)、DIV(整除)、MOD(取余)、**(乘方).
语法: [COMPUTE] n=<mathematical expression>.
运算符与变量之前必须有空格,实现某变量的加法语法如下:
DATA:INT TYPE I.
COMPUTE INT = INT + 10.
INT = INT + 10.
ADD 10 TO INT.
2.比较运算符
比较运算符有EQ或=(等于)、NE或<>(不等于)、LT或<(小于)、GT或>(大于)、LE或<=(小于或等于)、GE或>=(大于或等于)。
3.逻辑运算符
逻辑运算符有AND(与)、OR(或)、NOT(非)。
二、算术运算函数
3.1) ABAP所包含的函数如下:
| 函 数 名 | 说 明 |
| ABS | 返回输入参数的绝对值 |
| SIGN | 返回输入参数的符号:正数返回1,0返回0,负数返回-1 |
| CEIL | 返回不小于输入参数的最小整数 |
| FLOOR | 返回不大于输入参数的最大整数 |
| TRUNC | 返回输入参数的整数部分 |
| TRAC | 返回输入参数的小数部分 |
| ACOS(X) | 反余弦函数,结果范围为[-PI/2,PI/2],X的范围为from[-1,1](PI为三角函数:3.14) |
| ASIN(X) | 反正弦函数,结果范围为[0,PI],X的范围为from[-1,1] |
| ATAN | 反正切函数,结果的范围为[-PI/2,PI/2] |
| COS | 余弦函数 |
| SIN | 正弦函数 |
| TAN | 正切函数 |
| COSH | 余弦曲线函数 |
| SINH | 正弦曲线函数 |
| TANH | 正切曲线函数 |
| EXP | 底数为e的幕函数(2=2.7182818284590452) |
| LOG | 底数为e的自然对数 |
| LOG10 | 底数为10的对数 |
| SQRT | 平方根 |
| STRLEN | 获取字符串长度函数 |
以下为函数调用实例:
DATA:I1 TYPE I,
I2 TYPE I,
I3 TYPE I,
F1 TYPE F,
F2 TYPE F,
WORD1(10),
WORD2(20),
XSTR TYPE XSTRING.
F1 = ( I1+EXP(F2) ) * I2 / SIN( 3 - I3 ).
COMPUTE F1 = SQRT( SQRT( ( I1 + 12 ) * I3 ) + F2 ).
I1 = STRLEN(WORD1) + STRLEN(WORD2).
三、字符串控制函数
3.1)CONCATENATE:实现字符串的合并。
基本语法:CONCATENATE f1...fn INTO g [SEPARATED BY h]
DATA:ONE(10) VALUE 'Hello',
TWO(10) VALUE 'SAP',
RESULT1(10),
RESULT2(10),
I1 TYPE I,
I2 TYPE I.
CONCATENATE ONE TWO INTO RESULT1 SEPARATED BY SPACE.
CONCATENATE ONE TWO INTO RESULT2.
I1 = STRLEN( RESULT1 ) + STRLEN( RESULT2 ).
WRITE: / 'result1=',RESULT1, "输出:result1=Hello SAP
/ 'result2=',RESULT2. "输出:result2=HelloSAP
WRITE: / 'STRLEN=',I1. "输出:STRLEN=17
SPARATED BY表示在连接字符串中加入分隔符号,不然合并字符串的前后空格会自动清除,上例所示中加入了空格.
3.2)SPLIT:实现字符串的拆分。
SPLIT f AT g INTO h1...hn:将字符串的值分配给具体变量。
SPLIT f AT g INTO TABLE itab:将字符串的值分配给一内表。
DATA:NAMES(30) TYPE C VALUE 'HELLO,SAP',
NAMES2 TYPE STRING,
ONE(10) TYPE C,
TWO(10) TYPE C,
DELIMITER(1) VALUE ','.
TYPES:BEGIN OF ITAB_TYPE,
WORD(20),
END OF ITAB_TYPE.
DATA:ITAB TYPE STANDARD TABLE OF ITAB_TYPE WITH HEADER LINE.
SPLIT NAMES AT DELIMITER INTO ONE TWO.
SPLIT 'ONE STOP TWO STOP THREE STOP' AT 'STOP ' INTO TABLE ITAB.
WRITE:/ ONE,
/ TWO.
LOOP AT ITAB.
WRITE:/ ITAB.
ENDLOOP.
输出结果:ONE = HELLO TWO = SAP
TABLE VALUE = ONE
TABLE VALUE = TWO
TABLE VALUE = THREE

上例分別將字符串按指定符號“,”及指定字符串“STOP”將兩字符串進行了拆分並分別存入到指定字段及內表.
3.3) SHIFT:将字符串整体或者子串进 行转移。
SHIFT c <LEFT/RIGHT/CIRCULAR>.:指定字符移动方向,向左、向右或者循环移动一个字符,默认向左。
SHIFT c BY n PLACES.:指定移动字符位数。
如果操作对象是C类型,那么它的所有字符都会向前移动一位,最后一位用空格代替。倘若为STRING类型,所有的字符都会向前移动一位,最好一位删除。
DATA:STR1(12) TYPE C VALUE 'ABCDEFGHIJK',
STR2 TYPE STRING,
STR3(12) TYPE C,
STR4(12) TYPE C,
STR5(12) TYPE C,
STR6(12) TYPE C.
STR6 = STR5 = STR4 = STR3 = STR2 = STR1.
SHIFT STR1.
SHIFT STR2.
SHIFT STR3 RIGHT.
SHIFT STR4 CIRCULAR.
SHIFT STR5 BY 5 PLACES.
SHIFT STR6 RIGHT BY 2 PLACES.
WRITE:/ STR1,"输出:BCDEFGHIJK 整体长度不变,左移一位,最后为空
/ STR2,"输出:BCDEFGHIJK 左移一位,最后一位删除
/ STR3,"输出: ABCDEFGHIJK 整体长度不变,右移一位,首位为空
/ STR4,"输出:BCDEFGHIJK A 整体长度不变,字符循环移动
/ STR5,"输出:FGHIJK 整体向左移动5位
/ STR6."输出: ABCDEFGHIJ 整体向右移动2位

3.4)SHIFT c UP TO c1. 该定义可指定某字符串从某一具体子串进行位移,并将执行结果返回给系统参数SY-SUBRC,若执行成功时,返回值为‘0’,倘若子串与原字符串不匹配,返回值为‘4’.
DATA: STR1(10) VALUE 'ABCDEFGHIJ',
STR2(10) VALUE 'ABCDEFGHIJ',
STR3(3) VALUE 'DEF',
STR4(4) VALUE 'DEF'.
SHIFT STR1 UP TO STR3.
WRITE:/ 'STR1=',STR1, 'SY-SUBRC=',SY-SUBRC.
SHIFT STR2 UP TO STR4.
WRITE:/ 'STR2=',STR2, 'SY-SUBRC=',SY-SUBRC.
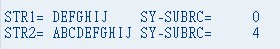
3.5) SHIFT c LEFT DELETING LEADING c1. 移除字符串左边的子字符串。
SHIFT c RIGHT DELETING TRAILING C1. 移除字符串右边的子字符串。
DATA: STR1(15) VALUE ' ABCDEFGHIJ',
STR2(15) VALUE ' ABCDEFGHIJ',
STR3(15) VALUE ' ABCDEFGHIJ',
STR4 TYPE STRING,
M1(4) VALUE 'ABCD',
M2(6) VALUE 'HIJ'.
STR4 = STR1.
SHIFT STR1 LEFT DELETING LEADING SPACE.
WRITE:/ 'STR1=',STR1."移除前面空格,后面补零
SHIFT STR2 RIGHT DELETING TRAILING M1.
WRITE:/ 'STR2=',STR2."子串不符合条件,未发生变化
SHIFT STR3 RIGHT DELETING TRAILING M2.
WRITE:/ 'STR3=',STR3."移除字符串右边‘HIJ’
SHIFT STR4 LEFT DELETING LEADING SPACE.
WRITE:/ 'STR4=',STR4."直接删除前面空格

3.6 CONDENSE:重新整合分配字符串。
CONDENSE c <NO-GAPS>.
DATA CONDENSE_NAME(30).
CONDENSE_NAME(10) = ' Dr.'.
CONDENSE_NAME+10(10) = 'Michael'.
CONDENSE_NAME+20(10) = 'Hofmann'.
CONDENSE CONDENSE_NAME.
WRITE: / 'CONDENSE_NAME=',CONDENSE_NAME. "输出:CONDENSE_NAME= Dr. Michael Hofmann
变量被重新赋值,并以空格分开,字符串前置空格被删除。若在函数后加上关键字"NO-GAPS",那么输出结果将变化为:'Dr.MichaelHofmann'。该语法同样适用于结构体中,结构体中的不同字段内容将会按字段长度被重新分配。
DATA:BEGIN OF CONDENSE_NAME2,
TITLE(8) VALUE ' Dr.',
FIRST_NAME(10) VALUE 'Michael',
SURNAME(10) VALUE 'Hofmann',
END OF CONDENSE_NAME2.
CONDENSE CONDENSE_NAME2.
WRITE: / 'condense_name2=',CONDENSE_NAME2."输出:Dr. Michael Hofmann 按原值输出。
WRITE: / 'condense_name2-title=',CONDENSE_NAME2-TITLE,"输出:Dr. Mich,title字段被重新按长度赋值,长度为8。
/ 'condense_name2-first_name=',CONDENSE_NAME2-FIRST_NAME,"输出:ael Hofman,first_name字段被重新按长度赋值,长度为10。
/ 'condense_name2-surname=',CONDENSE_NAME2-SURNAME."输出:n,surname字段被重新按长度赋值,长度为10。故就剩下末尾字母n。
3.7) TRANSLATE:实现字符串转换。
TRANSLATE c TO UPPER CASE.:将字符串转换为大写。
TRANSLATE c TO LOWER CASE.:将字符串转换为小写。
DATA:STR1(3) TYPE C VALUE'abc',
STR2(4) TYPE C VALUE 'EFGH'.
TRANSLATE STR1 TO UPPER CASE.
TRANSLATE STR2 TO LOWER CASE.
WRITE:/ STR1,"输出:ABC,转换为大写
/ STR2."输出:efgh,转换为小写
TRANSLATE c USING c1.:将字符串参照另一字符串转换。
按逐个字符判断,若原字符串中的某一字符在参考字符串中存在,那么取参考字符串中该字符首次出现位置的下一个字符串作为转换对象。若参考字符串中不存在该字符或该字符首次出现位置在参考字符串的最后一位,则不进行转换。
DATA:STR(20) TYPE C VALUE 'abcabcabcXabcf',
change(15) TYPE c VALUE 'aXbaYBabZacZB'.
TRANSLATE STR USING CHANGE.
WRITE:/ STR."输出:XaZXaZXaZXXaZf
TRANSLATE c...FROM CODE PAGE g1 ... TO CODE PAGE g2.
SAP可以应用于多种软硬件系统,不同系统间的信息传递和通信必然涉及代码转换问题。例如,HP-UX系统与IBM EBCDIC系统中的代码转换可通过下列语句实现,具体的代码保存在数据表TCP100中。
TRANSLATE C FROM CODE PAGE '1110' TO CODE PAGE '0100'.
3.8) OVERLAY:参考字符串对空白字符进行填充。
OVERLAY c1 WITH c2.
DATA:WORK(20) VALUE 'Th t h s ch ng d.',
HELP(20) VALUE 'Grab a pattern'.
OVERLAY WORK WITH HELP.
WRITE:WORK."输出:'That has changed'.
3.9) REPLACE:字符串按条件取代
REPLACE f ...WITH g ...INTO h.
DATA: STR(10) VALUE '12345ABCDE'.
REPLACE '12345'WITH '56789' INTO STR.
WRITE:STR."输出:56789ABCDE
3.10) SEARCH:按搜索指定字符串
SEARCH f FRO g:g表示被搜索的字符串。
...ABBREVIATED:从指定字符串中按顺序搜索相匹配字符串。
...STARTING AT n1:从字符串n1个字符开始搜索。
...ENDING AT n2:搜索到字符串第n2个字符止。
...AND MARK:从指定字符串是模糊搜索相匹配字符串。
SEARCH itab FOR g:g表示被搜索字符串。
...ABBREVIATED:从内表中按顺序逐行搜索相匹配字符串。
...STARTING AT line1:从内表中具体某行开始搜索匹配字符串。
...ENDING AT line2:搜索最大范围到内表中具体某行。
...AND MARK:从内表中模糊搜索相匹配字符串。
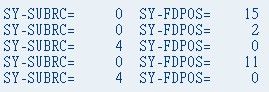
通过系统变量SY-SUBRC可以回执字符串查找的结果,若回执等于"0",则表示查找成功。某段字符在字符串中的具体位置保存在系统变量SY-FDPOS中。
DATA STR(50).
MOVE 'Welcome to SAP world!' TO STR.
SEARCH STR FOR 'Wrd' ABBREVIATED.
WRITE: / 'SY-SUBRC=',SY-SUBRC,'SY-FDPOS=',SY-FDPOS.
"执行结果:wrd按顺序包含在子字符串'world'中,SY-SUBRC=0,SY-FDPOS=15
SEARCH STR FOR 'SAP' STARTING AT 10.
WRITE: / 'SY-SUBRC=',SY-SUBRC, 'SY-FDPOS=',SY-FDPOS.
"执行结果:从第10位开始查找,SY-SUBRC=0,SY-FDPOS=2
SEARCH STR FOR 'SAP' ENDING AT 10.
WRITE: / 'SY-SUBRC=',SY-SUBRC, 'SY-FDPOS=',SY-FDPOS.
"执行结果:查找到第10位结束,SY-SUBRC=4,SY-FDPOS=0
SEARCH STR FOR '*AP' AND MARK.
WRITE: / 'SY-SUBRC=',SY-SUBRC, 'SY-FDPOS=',SY-FDPOS.
"查找包含'AP'子字符串,'SAP'符合条件,默认为查找'SAP',SY-SUBRC=0,SY-FDPOS=11
SEARCH STR FOR '*A' AND MARK.
WRITE: / 'SY-SUBRC=',SY-SUBRC, 'SY-FDPOS=',SY-FDPOS.
"匹配字符串必须是子字符串以空格分开的最后几位,SY-SUBRC=4,SY-FDPOS=0
对于一些特殊符号,如"*"、"@"、"."等,需要在其两边加上顿号作为修饰。如某字符串为"AAAA*BBBB",查找符号"*"的位置。
DATA SEARCH_STR2(50).
MOVE 'AAA*BBB' TO SEARCH_STR2.
SEARCH SEARCH_STR2 FOR '.*.' ABBREVIATED.
WRITE: / 'SY-SUBRC=',SY-SUBRC,
/ 'SY-FDPOS=',SY-FDPOS.
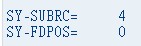
从内表中查找字符串方法与上面基本类似,若内表有多行,那么字符串查找位置默认为从某行数据第一位开始。
DATA:BEGIN OF T_INF OCCURS 0,
LINE(80),
END OF T_INF.
APPEND 'HELLO SAP 'TO T_INF.
APPEND 'I am come from china' TO T_INF.
SEARCH T_INF FOR 'SAP' ABBREVIATED.
WRITE: / 'SY-SUBRC=',SY-SUBRC,
/ 'SY-FDPOS=',SY-FDPOS."从内表第一行中可查找到,SY-SUBRC=0,SY-FDPOS=6
SEARCH T_INF FOR 'am' ABBREVIATED.
WRITE: / 'SY-SUBRC=',SY-SUBRC,
/ 'SY-FDPOS=',SY-FDPOS."从内表第二行中可查找到,SY-SUBRC=0,SY-FDPOS=2
