对原始数据集进行分词处理,并且通过绑定为Bunch数据类型,实现了数据集的变量表示。
文本分类的结构化方法就是向量空间模型,把文本表示为一个向量,该向量的每个特征表示为文本中出现的词。通常,把训练集中出现的每个不同的字符串都作为一个维度,包括常用词、专有词、词组和其他类型的模式串,如电子邮件地址和URL。可以类比为三维空间里面的一个向量。
下面是相国大人的博客中的解释。
例如:
如果我们规定词向量空间为:(我,喜欢,相国大人),这相当于三维空间里面的(x,y,z)只不过这里的x,y,z的名字变成了“我”,“喜欢”,“相国大人”:
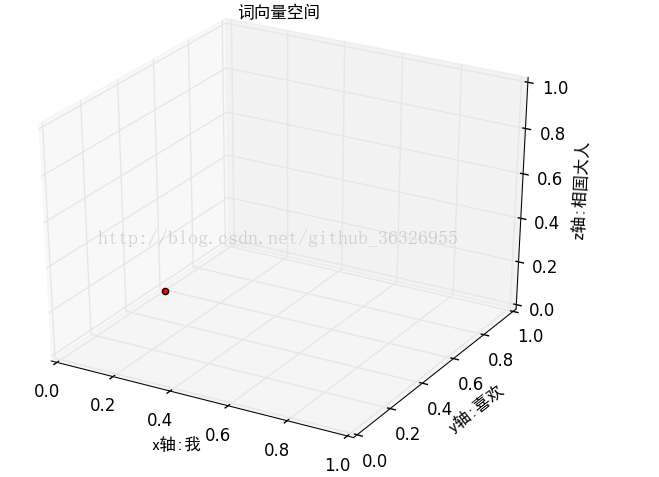
表示在词向量空间中就变为:(1,2,1),归一化后可以表示为:(0.166666666667 0.333333333333 0.166666666667)表示在刚才的词向量空间中就是这样:
词向量之间的单词个数并不相同,词向量的涵盖的单词也不尽相同。他们并不在一个空间里,没有可比性,例如:
词向量1:我 喜欢 相国大人,对应的词向量空间是(我,喜欢,相国大人),可以表示为(1,1,1)
词向量2:她 不 喜欢 我,对应的词向量空间是(她,不,喜欢,我),可以表示为(1,1,1,1)
两个空间不一样
因此,接下来就是把所有这些词向量统一到同一个词向量空间中,例如,在上面的例子中,我们可以设置词向量空间为(我,喜欢,相国大人,她,不)。
这样,词向量1和词向量2分别可以表示为(1,1,1,0,0)和(1,1,0,1,1),这样两个向量就都在同一个空间里面了。可以进行比较和各种运算了。
要把训练集内所有出现过的单词,都作为一个维度,构建统一的词向量空间,这样,文本在存储为向量空间时维度比较高,为节省存储空间和提高搜索效率,在文本分类之前会自动过滤掉某些字或者词,这些字或者词被称为停用词,这些词一般都是意义模糊的常用词,还有一些语气助词,通常他们对文本起不了分类特征的意义,这些停用词都是人工输入,非自动化生成的,生成后的停用词会形成一张停用词表,各类停用词表大同小异。
直接复制链接内容:停用词表下载
存放在路径:train_word_bag/hlt_stop_words.txt
停用词表的语法如下:
#读取文件
#1.读取停用词表
stopword_path="train_word_bag/hlt_stop_words.txt"
stpwrdlst=readfile(stopword_path).splitlines()