Hadoop on OpenStack: Elastic Data Processing (EDP) with Savanna 0.3
Now that version 0.2 of Project Savanna is out, it’s time to start looking at what will be coming up in version 0.3. The goal for this next development phase is to provide elastic data processing (EDP) capabilities, creating a Savanna component that enables data analysis and transformation in an easy and resource-effective way, running a Hadoop cluster only when it’s needed.
To provide this functionality, Savanna needs you to give it these three things:
- The data for processing
- A program that specifies how the data will be processed
- The location where that program will be executed
These three items define the architecture for the EDP part of Savanna. You can see the high-level architecture in this figure:
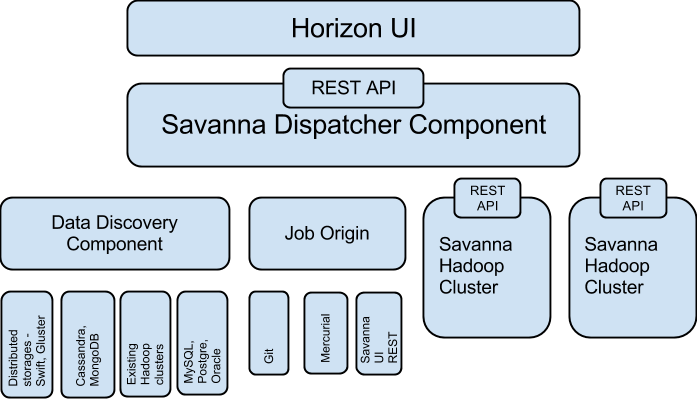
As you can see from the image, EDP is made up of the following components:
- Data discovery component—Enables pulling data from various data sources. Data can be pulled from Swift, GlusterFS, or NoSQL database such as Cassandra or HBase.
- Job origin—Supplies a task for data processing and execution on the cluster and allows users to execute several types of job: jar file, Pig and Hive scripts, and Oozie job flows.
- Dispatcher component—Responsible for scheduling the job on the new or existing cluster, provisioning a new cluster, resizing cluster and gathering information from clusters about current jobs and utilization.
- UI component—Enables integration with the OpenStack Dashboard (Horizon). It’s future intent is to provide instruments for job creation, monitoring, and so on. Hue already provides part of this functionality: submitting jobs (jar file, Hive, Pig, Impala), viewing job status, and outputting.
We’ll circle back to how EDP uses these three components, but first let’s consider in more detail how Savanna interacts with OpenStack as a whole:
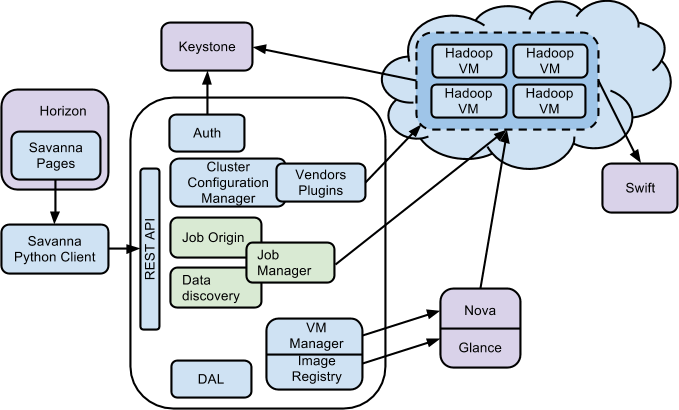
The Savanna product communicates with the following OpenStack components:
- Horizon—Provides a GUI with the ability to use all of Savanna’s features.
- Keystone—Authenticates users and provides a security token that is used to work with the rest of OpenStack, hence limiting a user’s abilities in Savanna to his or her OpenStack privileges.
- Nova—Used to provision VMs for Hadoop Cluster.
- Glance—Stores Hadoop VM images, each of which contains an installed OS and Hadoop.
- Swift—Used as a storage for data that will be processed by Hadoop jobs.
Let’s consider how Savanna performs elastic data processing using the three components we mentioned in the beginning of this post.
Data for processing
The data for processing can be stored in various locations and have various representations. Let’s take a look at different uses cases for data locations Savanna is planning to support:
- Raw files stored in distributed storage such as Swift, Gluster, Ceph, or an existing Hadoop cluster. The idea of Hadoop was initially born to address this use case, and it still remains a major power when we need to process huge amounts of data quickly, when the order of data processing is not critical, and when we expect to process all of the data, as opposed to just parts of it.
- Data stored in a NoSQL database such as HBase, Cassandra, or MongoDB. Data is placed in this type of storage for random access. Placing data in NoSQL can increase the processing speed if only some significant part of the data should be processed. For example, if a user needs to process only 10 percent of the data according to some criteria, they can reduce the data processing time by putting the data in NoSQL and building the index according to the chosen filter.
- Data stored in RDBMS, as is common in many legacy applications. One of the ways Savanna can provide a way to process this data is to enable integration with Apache Sqoop. Sqoop was designed for transferring bulk data between Hadoop and structured data stores, such as relational databases. So after starting cluster services and before submitting a job, you would populate the cluster using Sqoop.
Processing the data: job workflow
In its simplest form, a job is defined by a single jar file. It contains all of the necessary code—in other words, implementation of the map and reduce functions. This means that writing a data processing procedure typically requires knowledge of Java. Another option is to use the Hadoop Streaming API. In that case, you can implement the map and reduce functions in any language supported by the operating system on which Hadoop is running, for example, Python or C++.
For those who are not familiar with Java or other programming languages, Savanna provides an opportunity to use a high-level scripting language such as Pig or Hive. These languages can easily be learned by users who are not professional programmers.
Looking ahead, an interesting possibility is support of Mahout as a service. It contains sophisticated algorithms, which are difficult to implement in a scripting language like Hive or Pig. Often, the end user doesn’t want to know the implementation details. In the future, we hope that Savanna will enable running Mahout jobs in an elastic way.
Currently, Savanna supports users who are professional Hadoop programmers and have to run complex data processing algorithms, which involve several tasks. The abstraction that describes these general workflows is represented by direct acyclic graphs (DAGs). Vertices correspond to certain task and edges represent a dependencies between steps. In Hadoop, usually this process is managed via Oozie, a Hadoop workflow engine and job coordinator. The next version of Savanna, 0.3, will likely include a mechanism for scheduling Oozie workflows for elastic data processing.
Now let’s talk about how Savanna can get the job code needed to begin data processing.
The simplest way to provide a program for data processing is to store it in a distributed object store such as Swift. Savanna uses the Horizon dashboard to provide a user-friendly interface for file upload. This works great when you want a quick, one-time execution, for example, for an ad-hoc query. But on the other hand, Savanna should be able to process code from a version control system (VCS) repository—for example, git or mercurial. This is critical for users who have a continuous delivery process and need a way to propagate code from development and testing environments to production.
We’ll now drill down and explain job execution in more detail.
Job Execution
The first question when it comes to job execution is whether Savanna should start a new cluster or start the job on one that already exists. To answer that, Savanna takes into account various aspects, such as the current load the existing clusters, proximity to the data location, and the required speed. Savanna provides this information to the end user, so they can decide where to schedule the job.
One very useful feature is cluster autoscaling during a job execution. Often, at different stages of data processing, you require different resource quantities. Autoscaling allows you to have only what you need at the time you need it. The Savanna team is still deciding how to handle autoscaling; it is likely that we will support it first within Savanna itself, then integrate with Heat.
Summary
Plans for version 0.3 of Savanna include both analytics as a service and elastic data processing (EDP). Making this possible requires providing Savanna with the data, the implementation of the processing routine, and guidance on where to process the data itself. Once these capabilities are in place, Savanna’s elastic data processing (EDP) features allow you to choose where and how to process your data using resource autoscaling.
To follow progress on the Savanna project, or even to contribute, please visit the Savanna wiki