about
selenium模拟人对浏览器的操作,那人对如何对浏览操作呢?无非也就是点、划、拖拽、输入等操作。这些操作反映到HTML中,也无非是对节点元素的操作。selenium提供了多种对于元素的操作,简单来说,就是找到标签,操作它,但是现在有些标签的属性是动态的,所以,还是要根据实际情况来选择定位方式。
常见的元素定位方式有以下几种:
- 根据ID定位,可以说这是最常用的定位方式了,因为ID是唯一的,所以用来较为方便
drier.find_element_by_id,如果获取到多个,返回多个中的第一个。drier.find_elements_by_id,以列表的形式返回元素,无论元素是否唯一。
- 根据class属性定位
drier.find_element_by_class_name,如果具有class属性的元素有多个,返回多个中的第一个。drier.find_elements_by_class_name,以列表的形式返回元素,无论元素是否唯一。
- 根据tag name定位,直接根据标签名字定位,在某些情况下也是十分方便
drier.find_element_by_tag_name,如果获取到多个,返回多个中的第一个。drier.find_elements_by_tag_name,以列表的形式返回元素,无论元素是否唯一。
- 根据name属性定位,常用在对input框做做操作
drier.find_element_by_name,如果获取到多个,返回多个中的第一个。drier.find_elements_by_name,以列表的形式返回元素,无论元素是否唯一。
- 根据link text定位,专门用来定位超链接,只不过情况有些特殊,一个就是完全匹配超链接的内容进行定位,另一种是模糊定位,也就是超链接的内容包含指定文本即可定位到
find_element_by_link_text,绝对定位,如果获取到多个,返回多个中的第一个drier.find_elements_by_link_text,绝对定位,以列表的形式返回元素,无论元素是否唯一。drier.find_element_by_partial_link_text,模糊定位,如果获取到多个,返回多个中的第一个drier.find_elements_by_partial_link_text,模糊定位,以列表的形式返回元素,无论元素是否唯一。
- 根据xpath定位,这个也不用多少了,非常的灵活方便,只不过需要一点基础
drier.find_element_by_xpath,如果获取到多个,返回多个中的第一个drier.find_elements_by_xpath,以列表的形式返回元素,无论元素是否唯一。
- css selector定位,这个是官方推荐的定位方式,定位方式灵活,但是需要一点前端css基础
drier.find_element_by_css_selector,如果获取到多个,返回多个中的第一个drier.find_elements_by_css_selector,以列表的形式返回元素,无论元素是否唯一。
- By选择器,严格意义上来说,这不是一种定位方式,而是上面几种定位方式的一种封装形式,用起来相对顺手
个人认为,这里比较难的定位方式是xpath和css selector这两种定位方式,不过凡事经不起干,多练练就行了。
后续示例以百度搜搜主页为例,围绕着输入框和确定按钮来搞。
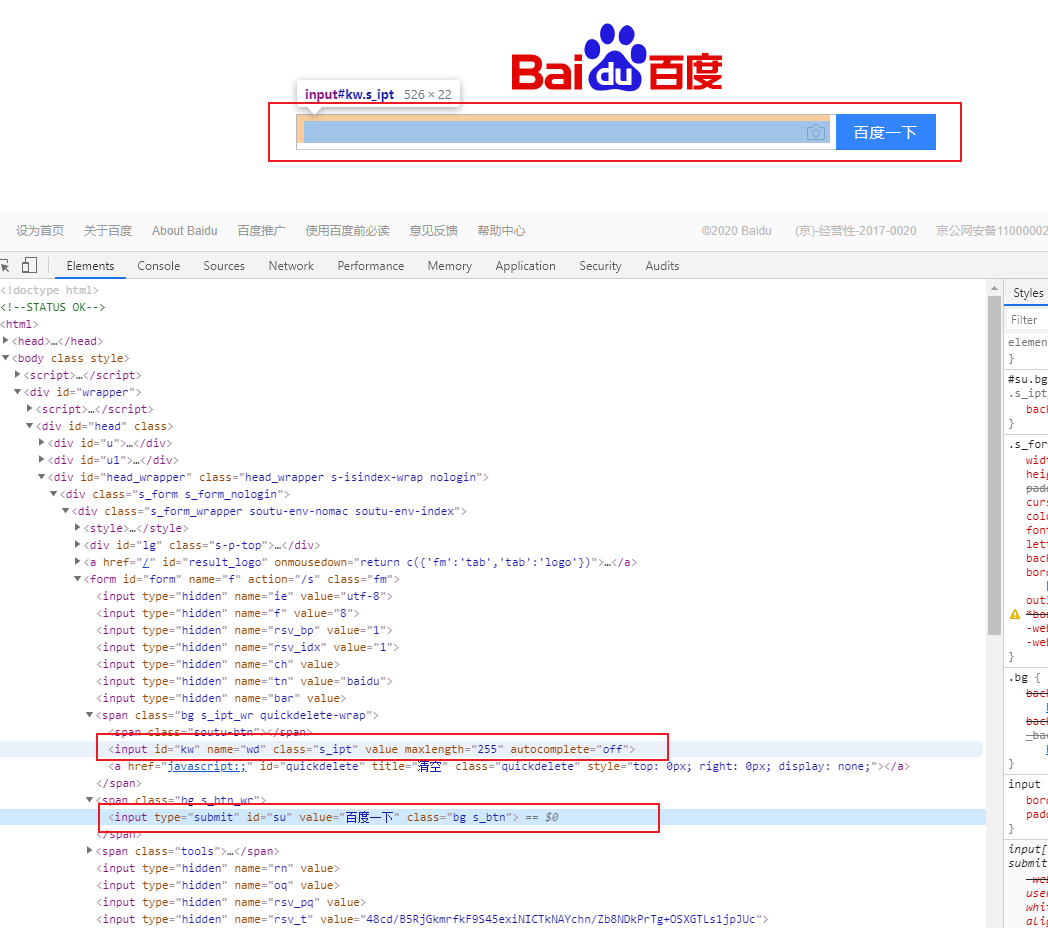
根据id定位
Copyimport time
from selenium import webdriver
drier = webdriver.Chrome()
drier.implicitly_wait(time_to_wait=10)
url = 'https://www.baidu.com'
drier.get(url)
drier.find_element_by_id("kw").send_keys(text)

根据class属性定位
Copyimport time
from selenium import webdriver
drier = webdriver.Chrome()
drier.implicitly_wait(time_to_wait=10)
url = 'https://www.baidu.com'
drier.find_element_by_class_name("s_ipt").send_keys(text)
drier.find_elements_by_class_name('s_btn')[0].click()

根据tag name定位
Copyimport time
from selenium import webdriver
drier = webdriver.Chrome()
drier.implicitly_wait(time_to_wait=10)
url = 'https://www.baidu.com'
drier.get(url)
# 获取form标签的id属性
form = drier.find_element_by_tag_name('form').get_attribute('id')
print(form) # form
# input框有多个,所以,要加 s ,并且需要自己去从返回的多个中去判断你选择的input的索引位置,所以,这里这么用有些麻烦 记住索引从1开始
ipt = drier.find_elements_by_tag_name("input")
ipt[7].send_keys(text)
# 这里说另一种思路,你可以先定位指定标签的父标签,然后通过父标签点位其内的子标签
span = drier.find_element_by_class_name("s_btn_wr") # 先定位到确定标签的父级标签 span
# 然后再找其内的input标签,当然,这种情况用id定位不香嘛
span.find_element_by_tag_name('input').click()

根据name属性定位
Copyimport time
from selenium import webdriver
drier = webdriver.Chrome()
drier.implicitly_wait(time_to_wait=10)
url = 'https://www.baidu.com'
drier.get(url)
drier.find_element_by_name('wd').send_keys(text)
time.sleep(2)
drier.find_elements_by_name("wd")[0].clear()

根据link text定位
Copyimport time
from selenium import webdriver
drier = webdriver.Chrome()
drier.implicitly_wait(time_to_wait=10)
text = '彭志强 - 博客园'
url = 'https://www.baidu.com'
drier.get(url)
try:
drier.find_element_by_id('kw').send_keys(text)
drier.find_element_by_id('su').click()
# 绝对定位
# drier.find_element_by_link_text(text).click()
# drier.find_elements_by_link_text(text)[0].click() # 复数形式
# 模糊定位
# drier.find_element_by_partial_link_text('彭志强 - 博').click()
drier.find_elements_by_partial_link_text('彭志强 - 博')[0].click() # 复数形式
except Exception as e:
print(e)
finally:
time.sleep(5)
drier.quit()

根据xpath定位
绝对定位
绝对定位.以开头,父/ 子
/html/body/div[2]/div[3]/div/div/div[2]/div[3]/i[1]继承顺序、 兄弟位置顺序
//*[@id= "number-attend"]/div[2]/div[3]/i[1]
//div[pid= "number -attend "]//i[@cLass="ing"I
相对定位
包含
1. //标签名[@届性=值]
//i[@class="ing"]
2、文本匹配配 /标签名[text(如=值]
//a[text()="公告”]
3.包含 //标签名[contains(@属性/text(),值)]
//a[contains(@href, "/Notify/index/courseid/")]
//a[contains(text(),"公告")]
轴运算:
ancestor:祖先结点包括父
parent:父结点给g
preceding:当前元素节点标签之前的所有结点。(html页面先后顺序)
preceding-sibling:当前元素节点标签之前的所有兄弟结点
following:当前元素节点标签之后的所有结点。(html页 面先后顺序)
following-sibling:当前元素节点标签之后的所有兄弟结点
使用语法:
已知的元素/轴名称::标签名称[@属性=值]
例: /
css selector
Css Selector是我最喜欢的元素定位方法,Selenium官网的Document里极力推荐使用CSS Selector,而不是XPath来定位元素,原因是CSS Selector比XPath Selector速度快,特别是在IE下面(IE没有自己的XPath 解析器(Parser))它比xpath更高效更准确更易编写,美中不足是根据页面文字时略有缺陷没有xpath直接。
因为前端开发人员就是用CSS Selector设置页面上每一个元素的样式,无论那个元素的位置有多复杂,他们能定位到,那我们使用CSS Selector肯定也能非常精准的定位到页面Elements。
来看常用的定位方式。
根据tag name定位
Copyimport time
from selenium import webdriver
drier = webdriver.Chrome()
drier.implicitly_wait(time_to_wait=10)
text = '听雨危楼 - 博客园'
url = 'https://www.baidu.com'
drier.get(url)
try:
form = drier.find_element_by_css_selector("form").tag_name
print(form) # form
except Exception as e:
print(e)
finally:
time.sleep(5)
drier.quit()
根据id定位
Copyimport time
from selenium import webdriver
drier = webdriver.Chrome()
drier.implicitly_wait(time_to_wait=10)
text = '听雨危楼 - 博客园'
url = 'https://www.baidu.com'
drier.get(url)
try:
# 直接根据id定位
drier.find_element_by_css_selector("#kw").send_keys(text)
# 通过标签加id的形式定位
drier.find_element_by_css_selector('input#su').click()
except Exception as e:
print(e)
finally:
time.sleep(5)
drier.quit()
根据class定位
Copyimport time
from selenium import webdriver
drier = webdriver.Chrome()
drier.implicitly_wait(time_to_wait=10)
text = '听雨危楼 - 博客园'
url = 'https://www.baidu.com'
drier.get(url)
try:
# 直接根据clas定位
drier.find_element_by_css_selector(".s_ipt").send_keys(text)
# 标签加class
drier.find_element_by_css_selector('input.s_btn').click()
# 多class属性定位
# drier.find_element_by_css_selector('.bg.s_btn').click() # class1 class2
# drier.find_element_by_css_selector('input.bg.s_btn').click() # input加多属性
except Exception as e:
print(e)
finally:
time.sleep(5)
drier.quit()
根据元素属性定位
Copyimport time
from selenium import webdriver
drier = webdriver.Chrome()
drier.implicitly_wait(time_to_wait=10)
text = '听雨危楼 - 博客园'
url = 'https://www.baidu.com'
drier.get(url)
try:
# 精准匹配
# drier.find_element_by_css_selector('input[name=wd]').send_keys(text) # 属性名=属性值
# drier.find_element_by_css_selector('input[type="submit"][value="百度一下"]').click() # 多属性
# 模糊匹配(正则表达式匹配)
drier.find_element_by_css_selector('input[id ^="k"]').send_keys(text) # ^= 匹配以 k 开头的id
# drier.find_element_by_css_selector('input[id $="w"]').send_keys(text) # $= 匹配以 w 结尾的id
drier.find_element_by_css_selector('input[value *="度一"]').click() # *= 匹配 value 值的中间部分
except Exception as e:
print(e)
finally:
time.sleep(5)
drier.quit()
更多正则的匹配:
- E[attr]:只使用属性名,但没有确定任何属性值;
- E[attr="value"]:指定属性名,并指定了该属性的属性值;
- E[attr~="value"]:指定属性名,并且具有属性值,此属性值是一个词列表,并且以空格隔开,其中词列表中包含了一个value词,而且等号前面的“〜”不能不写;
- E[attr^="value"]:指定了属性名,并且有属性值,属性值是以value开头的;
- E[attr$="value"]:指定了属性名,并且有属性值,而且属性值是以value结束的;
- E[attr*="value"]:指定了属性名,并且有属性值,而且属值中包含了value;
- E[attr|="value"]:指定了属性名,并且属性值是value或者以“value-”开头的值(比如说zh-cn);
查询子标签
Copyimport time
from selenium import webdriver
drier = webdriver.Chrome()
drier.implicitly_wait(time_to_wait=10)
text = '听雨危楼 - 博客园'
url = 'https://www.baidu.com'
drier.get(url)
try:
# 匹配子元素, A>B
# drier.find_element_by_css_selector('form>span>input').send_keys(text)
# 匹配后代元素, A空格B
# drier.find_element_by_css_selector('form span input').send_keys(text)
# 匹配第一个后代元素
# print(drier.find_element_by_css_selector('form :first-child').get_attribute('name')) # 返回form表单中隐藏的第一个input标签
# print(drier.find_element_by_css_selector('form span:first-child').get_attribute('class')) # 返回form表单中第一个span标签中的第一个子元素
# 根据索引匹配元素
# print(drier.find_element_by_css_selector('form :nth-child(2)').get_attribute('name')) # 返回form表单中第=二个input标签
# 匹配兄弟标签
print(drier.find_element_by_css_selector('form :nth-child(2)+input').get_attribute('name')) # 先定位到a,根据a匹配临近的b
except Exception as e:
print(e)
finally:
time.sleep(5)
drier.quit()
By选择器
By选择将上面繁琐的元素定位封装了起来,这样使用起来较为方便,只是在使用By选择器前要导入:
Copyfrom selenium.webdriver.common.by import By
用法如下,非常简单:
Copyimport time
from selenium import webdriver
from selenium.webdriver.common.by import By
drier = webdriver.Chrome()
drier.implicitly_wait(time_to_wait=10)
text = '听雨危楼 - 博客园'
url = 'https://www.baidu.com'
drier.get(url)
try:
drier.find_element(By.ID, 'kw').send_keys(text)
drier.find_element(By.CLASS_NAME, 's_btn').click()
except Exception as e:
print(e)
finally:
time.sleep(5)
drier.quit()
你可以直接:
CopyBy.ID
By.CLASS_NAME
By.CSS_SELECTOR
By.TAG_NAME
By.NAME
By.PARTIAL_LINK_TEXT
By.LINK_TEXT
By.XPATH
简单吧!