课程摘要:
1.现有方法:
2.本文方法: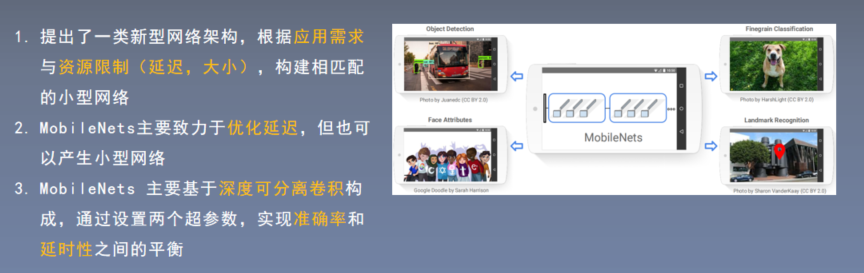
创新点:
知识树:
3.模型结构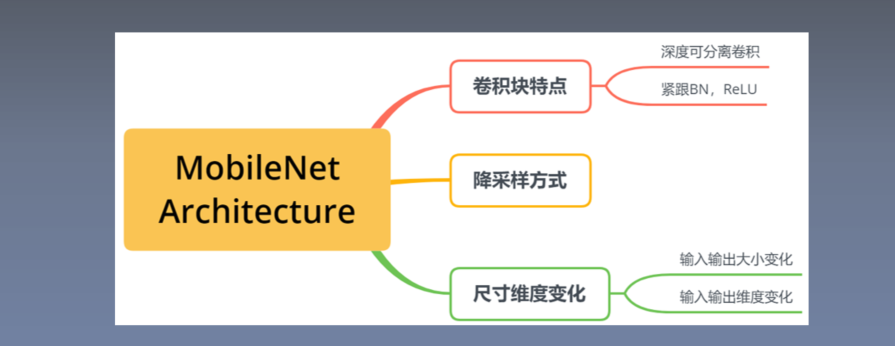
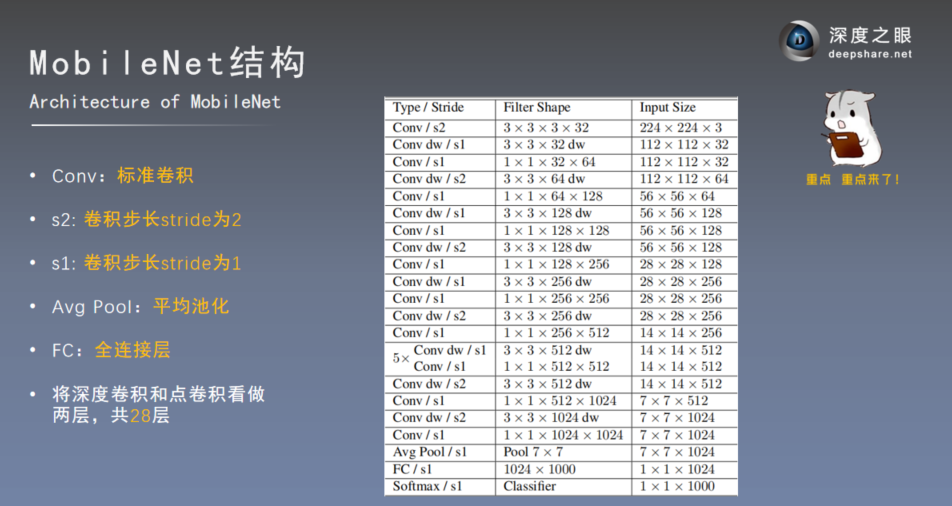

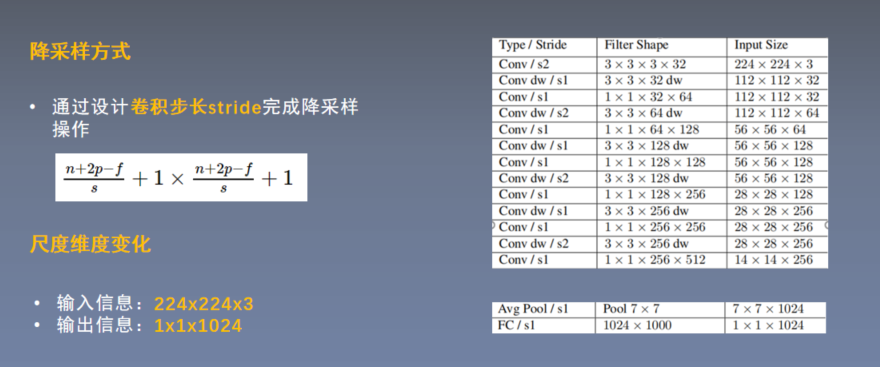
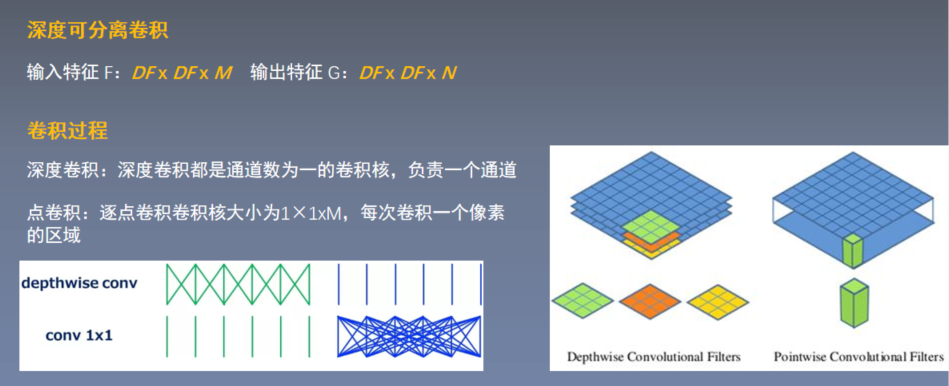
4.深度可分离卷积

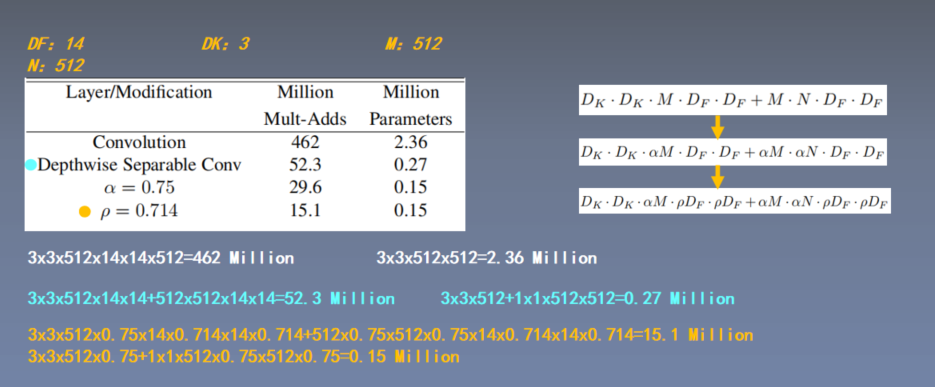
5.超参数


6.MobileNet后续改进地方:
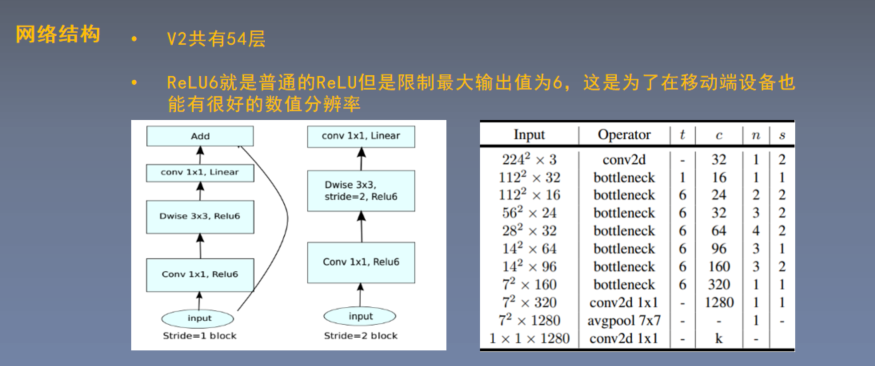
MobileNetV2:

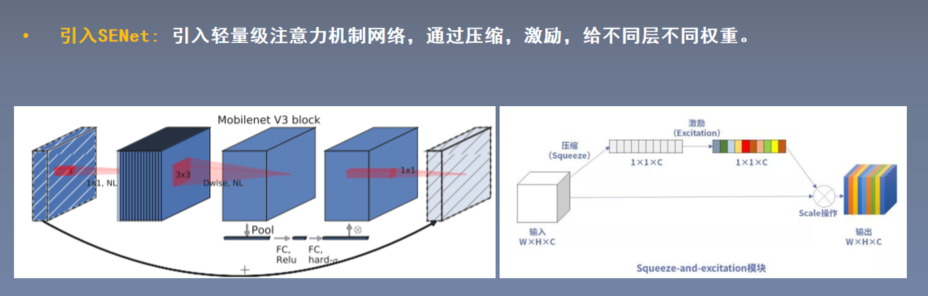
MobileNetV3:

三种模型对比:
作业
1.推导:MobileNets中的深度可分离卷积与标准卷积的算力消耗之比?
(input feature: FxFxC, kernel size: KxKxCxM, padding=same)
标准卷积的算力消耗:$K imes K imes F imes F imes C imes M$;
深度可分离卷积算力消耗:$(K imes K imes F imes F imes C imes 1) + (F imes F imes C imes M imes 1 imes 1) = (F imes F imes C imes K imes K) + (F imes F imes M imes C)$
消耗比:
$$
frac{{(F imes F imes C imes K imes K) + (M imes K imes K imes C)}}{{F imes F imes K imes K imes C imes M}} = frac{1}{M} + frac{1}{{{F^2}}}
$$
2.代码实践:利用pytorch复现MobileNet 28层网络结构,模型参数设置同论文一致。
主代码:
import argparse import torch import numpy as np import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.optim.lr_scheduler import StepLR from torchvision import datasets, transforms from torch.autograd import Variable from torch.utils.data.sampler import SubsetRandomSampler from sklearn.metrics import accuracy_score from mobilenets import mobilenet import pickle use_cuda = torch.cuda.is_available() def train(epoch): model.train() for batch_idx, (data, target) in enumerate(train_loader): if use_cuda: data, target = data.cuda(), target.cuda() data, target = Variable(data), Variable(target) #梯度清零 optimizer.zero_grad() output = model(data) correct = 0 pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability correct += pred.eq(target.data.view_as(pred)).sum() loss = criterion(output, target) loss.backward() accuracy = 100. * correct/ len(output) optimizer.step() if batch_idx % 1 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}, Accuracy: {:.2f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item(), accuracy)) scheduler.step() def validate(epoch): model.eval() valid_loss = 0 correct = 0 for data, target in valid_loader: if use_cuda: data, target = data.cuda(), target.cuda() with torch.no_grad(): data, target = Variable(data), Variable(target) output = model(data) # .data[0] valid_loss += F.cross_entropy(output, target, size_average=False).item() # sum up batch loss pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability correct += pred.eq(target.data.view_as(pred)).sum() valid_loss /= len(valid_idx) accuracy = 100. * correct / len(valid_idx) print(' Validation set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%) '.format( valid_loss, correct, len(valid_idx), 100. * correct / len(valid_idx))) return valid_loss, accuracy def test(epoch): model.eval() test_loss = 0 correct = 0 for data, target in test_loader: if use_cuda: data, target = data.cuda(), target.cuda() data, target = Variable(data, volatile=True), Variable(target) output = model(data) test_loss += F.cross_entropy(output, target, size_average=False).item() # sum up batch loss pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability correct += pred.eq(target.data.view_as(pred)).cpu().sum() test_loss /= len(test_loader.dataset) print(' Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%) '.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset))) if __name__ == "__main__": dtype = torch.cuda.FloatTensor if use_cuda else torch.FloatTensor normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) valid_size=0.1 valid_transform = transforms.Compose([ transforms.ToTensor(), normalize ]) train_transform = transforms.Compose([ transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(), transforms.ToTensor(), normalize ]) train_dataset = datasets.CIFAR10(root="cifar10", train=True,download=True, transform=train_transform) valid_dataset = datasets.CIFAR10(root="cifar10", train=True, download=True, transform=valid_transform) num_train = len(train_dataset) indices = list(range(num_train)) split = int(np.floor(valid_size * num_train)) np.random.seed(42) np.random.shuffle(indices) train_idx, valid_idx = indices[split:], indices[:split] train_sampler = SubsetRandomSampler(train_idx) valid_sampler = SubsetRandomSampler(valid_idx) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, sampler=train_sampler) valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=64, sampler=valid_sampler) test_transform = transforms.Compose([ transforms.ToTensor(), normalize ]) test_dataset = datasets.CIFAR10(root="cifar10", train=False, download=False,transform=test_transform) test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=True) model = mobilenet(num_classes=10, large_img=False) optimizer = optim.Adam(model.parameters(), lr=0.01) scheduler = StepLR(optimizer, step_size=10, gamma=0.5) criterion = nn.CrossEntropyLoss() for epoch in range(50): train(epoch) loss, accuracy = validate(epoch) test(epoch)
模型代码:
import torch import torch.nn as nn use_cuda = torch.cuda.is_available() class dw_conv(nn.Module): def __init__(self, in_dim, out_dim, stride): super(dw_conv, self).__init__() self.dw_conv_k3 = nn.Conv2d( in_dim, out_dim, kernel_size=3, stride=stride, groups=in_dim, bias=False) self.bn = nn.BatchNorm2d(out_dim) self.relu = nn.ReLU(inplace=True) def forward(self, x): x = self.dw_conv_k3(x) x = self.bn(x) x = self.relu(x) return x class point_conv(nn.Module): def __init__(self, in_dim, out_dim): super(point_conv, self).__init__() self.p_conv_k1 = nn.Conv2d(in_dim, out_dim, kernel_size=1, bias=False) self.bn = nn.BatchNorm2d(out_dim) self.relu = nn.ReLU(inplace=True) def forward(self, x): x = self.p_conv_k1(x) x = self.bn(x) x = self.relu(x) return x class MobileNets(nn.Module): def __init__(self, num_classes, large_img): super(MobileNets, self).__init__() self.num_classes = num_classes if large_img: self.features = nn.Sequential( nn.Conv2d(3, 32, kernel_size=3, stride=2), nn.ReLU(inplace=True), dw_conv(32, 32, 1), point_conv(32, 64), dw_conv(64, 64, 2), point_conv(64, 128), dw_conv(128, 128, 1), point_conv(128, 128), dw_conv(128, 128, 2), point_conv(128, 256), dw_conv(256, 256, 1), point_conv(256, 256), dw_conv(256, 256, 2), point_conv(256, 512), dw_conv(512, 512, 1), point_conv(512, 512), dw_conv(512, 512, 1), point_conv(512, 512), dw_conv(512, 512, 1), point_conv(512, 512), dw_conv(512, 512, 1), point_conv(512, 512), dw_conv(512, 512, 1), point_conv(512, 512), dw_conv(512, 512, 2), point_conv(512, 1024), dw_conv(1024, 1024, 2), point_conv(1024, 1024), nn.AvgPool2d(7), ) else: self.features = nn.Sequential( nn.Conv2d(3, 32, kernel_size=3, stride=1), nn.ReLU(inplace=True), dw_conv(32, 32, 1), point_conv(32, 64), dw_conv(64, 64, 1), point_conv(64, 128), dw_conv(128, 128, 1), point_conv(128, 128), dw_conv(128, 128, 1), point_conv(128, 256), dw_conv(256, 256, 1), point_conv(256, 256), dw_conv(256, 256, 1), point_conv(256, 512), dw_conv(512, 512, 1), point_conv(512, 512), dw_conv(512, 512, 1), point_conv(512, 512), dw_conv(512, 512, 1), point_conv(512, 512), dw_conv(512, 512, 1), point_conv(512, 512), dw_conv(512, 512, 1), point_conv(512, 512), dw_conv(512, 512, 1), point_conv(512, 1024), dw_conv(1024, 1024, 1), point_conv(1024, 1024), nn.AvgPool2d(4), ) self.fc = nn.Linear(1024, self.num_classes) def forward(self, x): x = self.features(x) x = x.view(-1, 1024) x = self.fc(x) return x def mobilenet(num_classes, large_img, **kwargs): model = MobileNets(num_classes, large_img, **kwargs) if use_cuda: model = model.cuda() return model
运行结果:
50次迭代后:
Train Epoch: 49 [5624/50000 (100%)] Loss: 0.306059, Accuracy: 87.50 Validation set: Average loss: 0.5231, Accuracy: 4351/5000 (87.02%) Test set: Average loss: 0.5397, Accuracy: 8611/10000 (86.11%)