什么是机器学习?
利用计算机从历史数据中找出规律,并把这些规律用到对未来不确定场景的决策
从数据中寻找规律
用模型刻画(拟合)规律)函数--》函数曲线--》拟合
机器学习发展的原动力
从历史数据中找出规律,把这些规律用到对未来自动做出决定。
用数据代替expert
经济驱动,数据变现
业务系统发展的历史
基于专家经验
基于统计---分纬度统计
机器学习---在线学习
数据分析和机器学习的区别
1. 从数据本身来看
数据分析: 处理的数据是交易数据 eg: 用户订单 用户存取款 用户的通话短信,使用的少量数据,采样分析,使用的海量数据
机器学习: 处理的数据是行为数据 eg: 用户的搜索历史 点击历史 浏览历史 评论,使用的海量数据
(ps:关注 行为数据 导致数据量剧增 所以就普通数据公司变成大数据公司了。), 全量分析 通过全量分析对用户的行为进行刻画
2. 解决业务问题不同
数据分析: 报告过去的事情
机器学习: 预测未来的事情
3. 参与者不同
数据分析:分析师能力决定结果, 目标用户: 公司高层
机器学习: 数据+算法,数据质量决定结果,目标用户:个体(最终用户)
机器学习算法分类
- 算法分类(1)
1. 监督式学习:

在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network)
2. 非监督式学习:
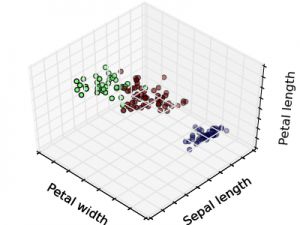
在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法以及k-Means算法。
3. 半监督式学习:
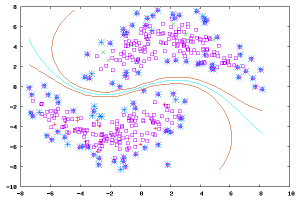
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。
- 算法分类(2)
- 分类与回归
- 聚类
- 标注 :示例如下
![]()
- 算法分类(3)
- 生成模型:告诉属于各个类的几率,不直接给出类别
- 判别模型 :直接告诉数据属于什么类
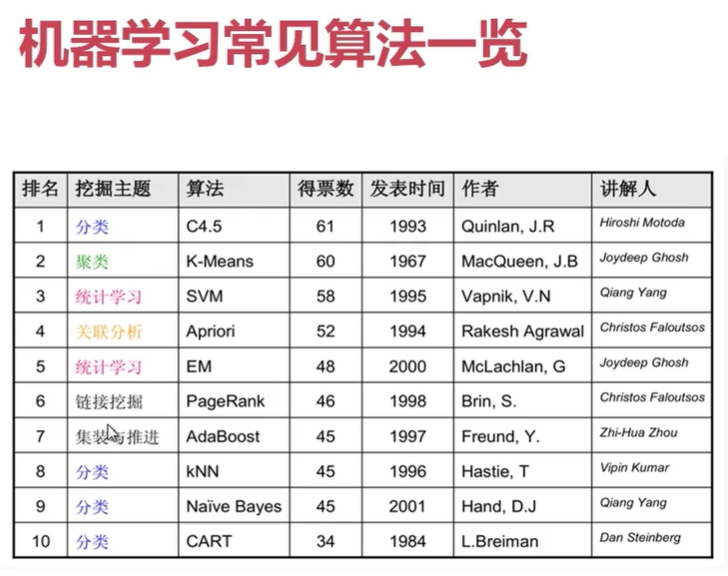
现在不太用的算法:1,4,10
Apriori: 纸尿裤与啤酒案例
PageRank: google
AdaBoost: 人脸识别
Naive Bayes(朴素贝叶斯): 垃圾邮件识别
EM:非针对具体问题,是一个算法框架

FP-Growth : 华人发明的