本文主要介绍 Manacher算法 , KMP算法 , 扩展KMP算法 , AC自动机 , 后缀数组 这几个简单的字符串算法。
以下内容均属于个人理解,如有错误请指出,不胜感激。
Manacher算法
Manacher算法,是用来解决有关回文串的问题的算法。
问题:
给定一个字符串(S),长度为(n),求它的最长回文子串的长度?
(1leq nleq 1.1 imes 10^7)
先不讲正解是什么,先想想暴力怎么做。
不难想到我们可以直接枚举中间点然后左右扩展,判一下奇偶就可以了。复杂度(O(n^2))。
我们可以考虑一下优化。
在原字符串的首尾和每个字符中间增加 原字符串中没有的字符 ,比如说(\%),这样就可以不必枚举奇偶了。
举个栗子,字符串(abc)在加上(\%)之后会变成(\%a\%b\%c\%),(abcd)加上之后会变成(\%a\%b\%c\%d\%),字符串长度就都是奇数了。
以字符串(12212321)为例,经过上一步,变成了(S=\%1\%2\%2\%1\%2\%3\%2\%1\%)
我们设置辅助数组(p[i])来记录以字符(S[i])为中心的最长回文子串向左/右扩张的长度(包括(S[i])),下面的图片中用#代替 (\%)。

通过观察我们不难看出(p[i]-1)就是以(S[i])为中心的回文子串的长度。其实这东西证明也是很简单的。
假设我们(p[i]=3),然后假设从(s[i])往右的(3)个字符为(\%a\%),因为(p)数组保留的是半径,所以我们还原该回文串之后就是(\%a\%a\%)。
因为(\%)都是我们补充的,所以在半径中除去(\%)再乘(2)就是实际回文串的长度。而求实际在原字符串中的字符个数又有两种情况。
- 回文串中心是(\%)上面我们已经讨论过了,这里就不重复说了。
- 回文串中心是原字符串中的字符。举个栗子(a\%a\%(p[i]=4)),显然这里的有用的字符就是(aa),因为这是半径,所以我们还要乘(2),但是由于该回文串的中心是原字符串中的字符,所以中间那个字符会算两次,所以我们还要减去中间的那个字符,即(2 imes2-1),也就是(4-1),也就是(p[i]-1)了。
但是我们还要考虑一点,我们上面讨论的都是结尾字符以(\%)的情况,那会不会结尾字符有原字符串中的字符呢?
答案显然是 不可能 的,因为如果有这种情况的话,我们可以再往两边扩展一个(\%)(每两个字符中间都有一个(\%)),就变成了上面我们讨论的两种情况了。
(cdot) 再设置两个辅助变量
设(id)为当前我们已知的右边界最大的回文子串的中心,(mx)为(id+p[id])也就是最大的右边界。如下图。
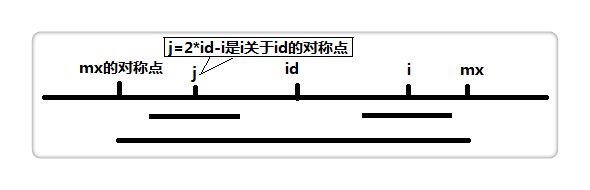
假设我们当前要求的位置为(i(i<mx)),我们可以找到(i)关于(id)的对称点(j),因为(id)为中点,所以(id)左侧和右侧字符是 完全一样 的。
所以我们可以利用(j)来加速(p[i])的求解。因为(p[i])是可以等于(p[j])的。
但是我们注意到,(mx)右边的部分是有可能不等于(id-p[id])(即(mx)的对称点)的左边部分的。所以(p[i])应该小于等于(mx-i)。至于(mx)右侧的部分,我们就只能暴力扩展了。
如果(i geq mx)的话,那我们就只能先暂令(p[i]=1)然后同样暴力扩展了。扩展完之后更新(mx)和(id)。
模板题Manacher算法 下面放代码,代码中用#代替(\%)。
#include<bits/stdc++.h>
using namespace std;
char s[32000005],s_new[32000005];
int p[32000005];
int get() {
s_new[0]='$';
s_new[1]='#';
int k=2;
int n=strlen(s);
for(int i=0; i<n; i++) {
s_new[k++]=s[i];
s_new[k++]='#';
}
s_new[k]='�';
return k;
}
void manacher() {
int len=get();
int mx=0,id=0,ans=-1;
for(int i=1; i<=len; i++) {
if(i<mx)
p[i]=min(mx-i,p[2*id-i]);
else
p[i]=1;
while(s_new[i-p[i]]==s_new[i+p[i]])
p[i]++;
if(i+p[i]>mx) {
mx=i+p[i];
id=i;
}
ans=max(ans,p[i]-1);
}
printf("%d
",ans);
}
int main() {
scanf("%s",s);
manacher();
return 0;
}
KMP算法
问题引入
给你一个文本串(S),长度为(n),再给你一个模式串(T),长度为(m),求模式串在文本串中出现的位置?
(1 leq n,mleq 10^6)
这是一个很很很经典的问题了。
因为篇幅问题(其实是作者懒得打了),这里就直接进入主题了。
依然是举例子。看一下下面这组样例。
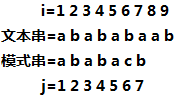
我们用指针(i)和(j)来表示(S[i-j+1,i]=T[1,j])。
也就是说(i)是随着(j)的增加而增加的,而当(j=m)时,就意味着我们在文本串(S)中找到了一个模式串(T)。我们令上图中(i=j=5)。
接下来我们就要比较(S[i+1])和(T[j+1])了,很明显,模式串和文本串将在这一位失配,也就是下图中的红色位置。

这个时候我们该怎么办呢?想一想。我们研究这个算法的目的是什么?是不是就是提升速度?那么速度的瓶颈是什么?是不是就是模式串和文本串匹配的次数?
也就是说,如果我们模式串和文本串的匹配次数越少,这个算法的时间复杂度就越少(显而易见)
所以当我们失配的时候,我们是不是应该将(j)指针往前移,移到某一位置使模式串(T[1,j])再次和文本串(S[i-j+1,i])相匹配,并且,(j) 越大越好 (显而易见),这样就可以使匹配次数尽可能地减少了。具体点,就是说我们要在模式串(T[1,j])中再找到一个位置(j'),使得(T[1,j']=T[j-j'+1,j]),因为这样我们才可以保证此时的(j')与之前的(j)的性质是完全一样的(即还能与文本串匹配成功),然后再比较(T[j'+1])和(S[i+1])是否相等。在上面这个例子中,(T[3,5]=T[1,3]),所以当(T[j+1])和(S[i+1])失配时,我们可以让(j)重新等于(3),这样文本串和模式串还是匹配的。(因为之前的匹配让我们知道(S[i-j+1,i]=T[1,j]),所以(T[j-j'+1,j]=S[i-j'+1,i]),就有(T[1,j']=T[j-j'+1,j]=S[i-j'+1,i]))。如下图。

注意此时,(i)指针的位置是 不动 的。然后我们继续匹配(T[j'+1])和(S[i+1]),我们发现他们两个是相等的,所以(i,j)同时加(1)。然后继续上述过程,直到(j=m)。
通过我们前面模拟的那一步将(j)调小至(j'),我们发现(j)的减小只与模式串有关,而与(i)无关,因此我们完全可以设置一个辅助数组来实现(j)的快速跳动。
我们定义(next[i])表示在 模式串 中以(i)结尾的子串的后缀与该子串的前缀 (非本身) 的最长匹配长度。
说起来可能有点绕,我们仍用上面的例子解释一下这句话。
当(j=5)时,(next[5]=3),为什么呢?因为在(ababa)这个子串中,固然有前缀(a)(即(T[1]))等于后缀(a)(即(T[5])),但它不是最长的。前缀(aba)(即(T[1,3]))等于后缀(aba)(即(T[3,5])),并且没有其他的比这个前缀更长的前缀能与该子串的后缀相匹配(该子串本身除外)。所以(next[5]=3)。为什么要最长?还是上面那句话,这样就可以使匹配次数尽可能地减少了。假设我们已经知道了所有的(next[i]),我们再来模拟一遍上面的样例。
经过第一次失配后,一直直到(i=7),文本串都是与模式串相匹配的。如下图。

我们接下来要匹配(S[8])和(T[6]),我们发现失配了,所以(j)指针要往前跳,因为(nxet[5]=3),所以(j)指针再一次跳到(3)这个位置。如下图。

此时(i=7,j=3),我们继续匹配(S[8])和(T[4]),发现还是失配,所以(j)还要跳,我们通过观察得知(next[3]=1),所以令(j=1),变成下面这样:

此时(i)还是等于(7),继续匹配(S[8])和(T[2]),可是这个时候它还是不匹配(md怎么这么烦),所以(j)要跳到(next[1]),即(0),所以(j=0)。

终于,我们的(S[8]=T[1])了,所以(i++,j++),可是有时候,就算到(j=0)时它仍然不会和文本串匹配。因此,当(j=0)时,我们增加(i)值但忽略(j),直到出现文本串与模式串匹配。
至此KMP算法(有限状态自动机的模式匹配算法)主要过程告一段落,于是这一段匹配的代码:
int j=0;
for(int i=1; i<=n; i++) {
while(j>0&&S[i]!=T[j+1]) j=next[j];//不断跳j,i不变
if(S[i]==T[j+1]) j++;//如果相等了,j就加1,继续往后匹配
if(j==m)//在文本串中找到一个模式串
j=next[j];//继续往后找看文本串中还有没有模式串
}
求解next数组
我们再来看一下定义:
定义(next[i])表示在 模式串 中以(i)结尾的子串的后缀与该子串的前缀 (非本身) 的最长匹配长度。
由定义可知,(next[1]=0)(因为子串本身不算)。我们可以用(next)求(next)。
仍然引用上面的例子,假设我们已经求得(next[1 cdots 4]),现在要求(next[5 cdots 6]),该怎么求呢?
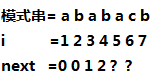
(next[5])还是很简单的,因为由(next[4]=2)可知,(T[1,2]=T[3,4]),然后又因为(T[3]=T[5]),所以(next[5]=3)。
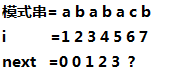
接下来我们求(next[6])。
因为(T[6])并不等于(T[next[5]+1]),所以我们不能直接像上面那样直接算。
我们已知(next[3]=1,next[5]=3)也就意味着(T[1]=T[3]=T[5]),所以既然我们在(next[5])处失败,我们可以考虑让(next[6]=next[next[5]]),然后比较(T[6])和(T[next[next[5]]]+1),
如果不相等,我们就让(next[6]=next[next[next[5]]]),然后继续比较(T[6])和(T[next[next[next[5]]]]+1),如此往复,直到(0)。
所以求(next)数组代码:
int j=0;
next[1]=0;//根据定义next[1]=0
for(int i=2; i<=m; i++) {
while(j>0&&T[j+1]!=T[i]) j=next[j];
if(T[j+1]==T[i]) j++;
next[i]=j;
}
时间复杂度
(O(n+m)),这里就不证明了事实上是作者太菜了。
扩展KMP算法
前言
扩展KMP,又名(ExKMP),在外国被称为(Z-Algorithm)。
问题
存在母串 (S) 和子串 (T) ,设 (|S|=n,|T|=m) ,求 (T) 与 (S) 的每一个后缀的最长公共前缀 ((LCP))。
(1 leq n,mleq 2 imes 10^7)
我们定义(extend[i])表示在(S)串中以(i)为首字母的后缀与(T)串的前缀的最长匹配长度,求解这个问题的过程实际上就是求(extend)数组。
我们举一个例子吧。
设(S=aaaaaaaaaabaa),(n=13),
(T=aaaaaaaaaaa),(m=11)

通过观察我们不难得到(extend[1]=10)。接下来我们要求(extend[2]),该怎么求呢?我们需不需要从(S[2])开始和(T[1])匹配呢?
我们先理一理,我们从(extend[1]=10)中可以得到什么?
然后我们知道,我们求(extend[2])就是等于求(S[2,10])与(T)的前缀的最长匹配长度。
所以用上我们推导得到的(S[2,10]=T[2,10]),进一步转化,将上面那句话中的(S[2,10])改为(T[2,10]),
不难发现求(extend[2])就是等价于求(T[2,10])与(T)的 前缀 的最长匹配长度。
所以我们可以在这里设置(next)数组,其中(next[i])表示(T[i,m])与(T)的前缀的最长匹配长度。注意,这里的(next)数组的定义与(KMP)算法中的(next)数组的定义不一样
我们看图可知(next[2]=10),所以我们根据(next)的定义可以得出以下推导。
然后联立上面推导得到的式子(star),
所以至此为止,我们回答了上面的那个问题,答案是不需要的,也就是说,当我们求(extend[2])时,(S[2,10]=T[1,9])我们是已知的,所以,不需要再浪费时间去一一匹配。
直接从(S[11])和(T[10])开始比较,一比较发现不同,所以(extend[2]=9)。上面的都是特殊情况,我们现在再来讨论一般情况。
求extend数组
当我们要求(extend[k+1])时,假设我们已知(extend[1cdots k]),我们设(p)为(max(i+extend[i]-1)),其中 (i in [1,k]),设取到这个(p)的位置为(a)。
由(S)数组的定义可得:
我们令(L=next[k-a+2])。这里分了两种情况。
第一种情况:
(k+L<p)

由已知条件我们可以得到几个关系:
化简得(T[k-a+2,k+L+1-a]=T[1,L]),将上面得到的(S[k+1,p]=T[k-a+2,p-a+1])代入
然后我们再化简一下就是
所以我们发现红色部分是相等的,蓝色部分肯定不相等,因为如果相等那么就违背了(next)数组的定义了((next[k-a+2]=L+1))
所以这种情况我们可以直接得到(extend[k+1]=L)。同时(a,p)的值都不变,(k+1
ightarrow k)然后继续求(extend[k+1])。
第二种情况:
(k+L geq p)
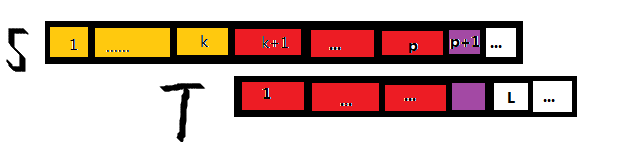
我们也可以像上面第一种情况一样证出红色部分是相等的,这里就不再赘述,请读者自己思考。
上图的紫色部分是未知的,因为在计算(extend[1cdots k])的时候,我们最远到达的地方就是(p),(p)以后的部分我们是未曾到达过的,所以们就不知道紫色部分是否相等。
于是我们就要从(S[p+1] Leftrightarrow T[p-k+1])开始匹配,直到不相等为止,匹配完之后比较(p)和(extend[k+1]+(k+1))的大小,如果后者大,就更新(a)和(p)。
求next数组
最后一步就是求(next)数组了。在这之前我们再来看一下(next)数组的定义和(extend)数组的定义。
我们定义(extend[i])表示在(S)串中以(i)为首字母的后缀与(T)串的前缀的最长匹配长度(Rightarrow)
我们定义(extend[i])表示(S[i,n])与(T)的前缀的最长匹配长度
我们定义(next[i])表示(T[i,m])与(T)的前缀的最长匹配长度
相信聪明的读者已经发现了什么。其实求解(next)数组就是以(T)为母串,同时以(T)为子串的一个 特殊的扩展KMP 。
即用(next)计算(next),读者可以直接使用上文的方法求解。
关于时间复杂度
在计算(extend)和(next)数组的过程中,只会访问未访问的位置,因此,时间复杂度为(O(n+m))。
模板题扩展KMP(Z函数) 这里放一下求(next)数组和(Z)数组(就是(extend)数组)的代码,输入的字符串下标都是从(1)开始。
void getNext(){
Next[1]=m;
int p=1,a=2;
while(t[p]==t[p+1]&&p+1<=m) p++;
Next[2]=p-1;
for(int i=3;i<=m;i++){
int k=i-1,L=Next[k-a+2];
p=Next[a]+a-1;
if(k+L<p)
Next[i]=L;
else{
p=max(p-i+1,0);
while(t[p+1]==t[p+i]&&p+i<=m) p++;
Next[i]=p;
a=i;
}
}
}
void getZ(){
int a=1,p=1;
while(s[p]==t[p]&&p<=m) p++;
Z[1]=--p;
for(int i=2;i<=n;i++){
int k=i-1,L=Next[k-a+2],p=Z[a]+a-1;
if(k+L<p)
Z[i]=L;
else{
p=max(p-i+1,0);
while(s[p+i]==t[p+1]&&p+i<=n&&p<=m) p++;
Z[i]=p;
if(Z[i]+i-1>Z[a]+a-1)
a=i;
}
}
}
AC自动机
简单的说一下吧。不想写了。
其实就是(Trie)加(KMP)。不会的可以参考这里
后缀数组
现在还不会,以后回来补。但是还是先放上一份我觉得讲得比较好的博客吧,点这里
参考资料:WC2021李建老师的课件《信息学竞赛中的字符串问题》