爬虫——cheerio
###安装cheerio - `npm install -g cheerio` - `npm install -g cheerio --save-dev`
编写爬虫代码
spider.js
var http = require('http');
var cheerio = require('cheerio');
var url = 'http://www.imooc.com/learn/51'; //本实例是爬一个慕课网课程列表
//过滤文本内容
function filterChapters(html){
var $ = cheerio.load(html);
var chapters = $('.chapter');
var courseData = [];
chapters.each(function(item){
var chapter = $(this);
var chapterTitle = chapter.find('strong').contents().filter(function() { return this.nodeType === 3; }).text().trim();
var videos = chapter.find('.video').children('li');
var chapterData = {
chapterTitle: chapterTitle,
videos: []
}
videos.each(function(item){
var video = $(this).find('.J-media-item');
var temp=video.text().trim();
var arr = temp.split('
'); // 多层标签的文本都拼到一起了,要拆开,取用需要的值
var videoTitle = arr[0].trim() + ' ' +arr[1].trim();
var id=video.attr('href').split('video/')[1].trim();
chapterData.videos.push({
title: videoTitle,
id: id
})
})
courseData.push(chapterData)
})
return courseData;
}
//打印爬虫结果
function printCourseInfo(courseData){
courseData.forEach(function(item){
var chapterTitle = item.chapterTitle;
console.log(chapterTitle+'
'+'
');
item.videos.forEach(function (video) {
console.log(' 【' + video.id + '】 ' + video.title.trim() +'
');
})
})
}
//获取网站文本内容
http.get(url, function(res){
var html = '';
res.on('data', function(data){
html += data;
})
res.on('end', function(){
var courseData = filterChapters(html);
printCourseInfo(courseData);
})
}).on('error', function(){
console.log('出现错误!');
})
运行爬虫代
- 打开node命令行Node.js command prompt或者git bash
- 执行命令
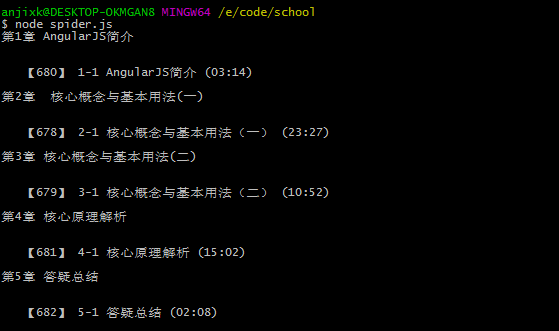
node spider.js,即可看到爬虫结果
上码不上图,菊花万人捅
- 运行结果图