继承关系
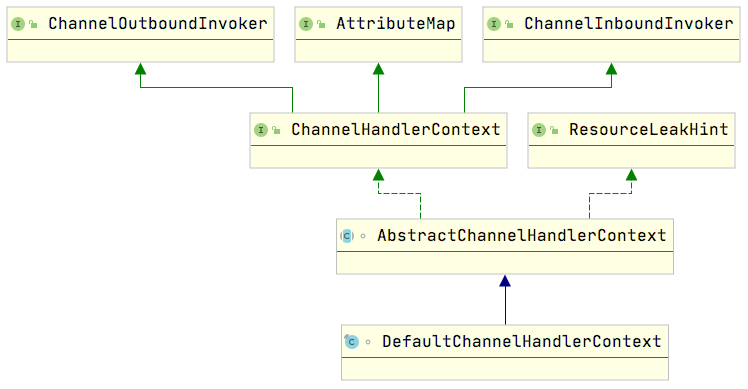
该接口与 给大动脉来一刀 - ChannelPipeLine 接口一样都继承了 ChannelOutboundInvoker 和 ChannelInboundInvoker, 这两个接口下面有说.
关于 AttributeMap 接口可以储存自定义的属性.
ChannelInboundInvoker & ChannelOutboundInvoker
这两个接口和 ChannelInboundHandler & ChannelOutboundHandler 接口类似.
有 Handler 关键字的这两个接口, 就是最终的入站和出站处理类; 而 Invoker 关键字的接口, 它虽然也有和 Handler 关键字接口中类似的方法, 但在最终都会委托给 AbstractChannelHandlerContext 抽象类中的对应静态方法.
但是有 Invoker 关键字的接口中, 会有一些特有的方法, 这些方法根据具体实现类有不同的实现, 例如:
// ChannelInboundInvoker 中的 newPromise() 方法.
ChannelPromise newPromise();
// 该方法在 DefaultChannelPipeline 中的实现.
public final ChannelPromise newPromise() {
return new DefaultChannelPromise(channel);
}
// 该方法在 AbstractChannelHandlerContext 中的实现.
public ChannelPromise newPromise() {
return new DefaultChannelPromise(channel(), executor());
}
AbstractChannelHandlerContext
构造方法
AbstractChannelHandlerContext(DefaultChannelPipeline pipeline, EventExecutor executor,
String name, Class<? extends ChannelHandler> handlerClass) {
// 下面这三个没啥好说的就是赋值
this.name = ObjectUtil.checkNotNull(name, "name");
this.pipeline = pipeline;
this.executor = executor;
// 调用 ChannelHandlerMask 中的静态方法 mask.
this.executionMask = mask(handlerClass);
// 如果 EventLoop 或者 Executor 实例实现了 OrderedEventExecutor 接口, 则顺序执行.
ordered = executor == null || executor instanceof OrderedEventExecutor;
}
// 用来获取和计算 ChannelHandler 类型的 mask 值.
// 该值表示了 ChannelHandler 是 入站还是出站, 并且对那些事件感兴趣.
static int mask(Class<? extends ChannelHandler> clazz) {
// 获取缓存
Map<Class<? extends ChannelHandler>, Integer> cache = MASKS.get();
Integer mask = cache.get(clazz);
if (mask == null) {
// 如果缓存中没有, 则计算.
mask = mask0(clazz);
cache.put(clazz, mask);
}
return mask;
}
private static int mask0(Class<? extends ChannelHandler> handlerType) {
// mask = 1
int mask = MASK_EXCEPTION_CAUGHT;
try {
// 判断是否是 ChannelInboundHandler 类型.
if (ChannelInboundHandler.class.isAssignableFrom(handlerType)) {
// 或上 MASK_ALL_INBOUND(511), 添加所有 inbound 关心的事件位.
mask |= MASK_ALL_INBOUND;
if (isSkippable(handlerType, "channelRegistered", ChannelHandlerContext.class)) {
// 表示此 Handler 并不关心此事件, 将对应位上的数字变为相反, 即 1->0
// 这里 registered 事件为二进制第二位为 1, 则跳过的话, 将第二位变为 0
mask &= ~MASK_CHANNEL_REGISTERED;
}
// ...
}
// 判断是否是 ChannelOutboundHandler 类型.
if (ChannelOutboundHandler.class.isAssignableFrom(handlerType)) {
// MASK_ALL_OUTBOUND(130561)
mask |= MASK_ALL_OUTBOUND;
// 下面这里与入站类似
if (isSkippable(handlerType, "bind", ChannelHandlerContext.class,
SocketAddress.class, ChannelPromise.class)) {
mask &= ~MASK_BIND;
}
// ...
}
// 无关 Inbound 和 Outbound, 都可以关心的事件.
if (isSkippable(handlerType, "exceptionCaught", ChannelHandlerContext.class, Throwable.class)) {
mask &= ~MASK_EXCEPTION_CAUGHT;
}
}
catch (Exception e) {
PlatformDependent.throwException(e);
}
return mask;
}
mask0 方法中的代码太多就不复制全部的了, 举个例子当有一个 ChannelHandler 实例为 ChannelInboundHandler 类型, 并且只关心 channelRead 方法, 这个时候 mask 的值为 33.
主要属性和方法
该抽象类有一个默认实现为 DefaultChannelHandlerContext, 该实现类的初始化可以在 给大动脉来一刀 - ChannelPipeLine 文章中找到.
下面是一些该类比较重要的属性和方法:
volatile AbstractChannelHandlerContext next;
volatile AbstractChannelHandlerContext prev;
还记得前面说过的 ChannelPipleline 吗? ChannelHandler 的管理容器, 它内部维护了一个 ChannelHandler 的链表, 可以方便的实现 ChannelHandler 的查找、添加、删除、替换、遍历等.
在内部维护的 ChannelHandler 链表, 是一个双向链表, 并且只会维护相同的头和尾; 而对于上一个或下一个 ChannelHandler, 是根据当前抽象类中的这两个属性维护的.
换句话说, AbstractChannelHandlerContext 是 Netty 实现 Pipeline 机制的关键.
读消息
在 给大动脉来一刀-ChannelPipeLine#OP-WRITE-事件传播 文章中的代码处有说, 第一个 channelRead 方法是通过调用 ChannelPipeline#fireChannelRead(); 方法执行.
该方法的源码为:
public final ChannelPipeline fireChannelRead(Object msg) {
// head 是 ChannelPipleline 中所维护的内部类 HeadContext.
// 不多说对应文章中有介绍.
AbstractChannelHandlerContext.invokeChannelRead(head, msg);
return this;
}
这里画重点, 就堵一台考面包机.
也就是说 ChannelPipeline 想要执行 ChannelHandler 链表, 靠的就是 AbstractChannelHandlerContext 抽象类中的相关静态方法. 值得注意的是: 这些静态方法的作用域全部为 protected.
除了上面说的这个静态方法外, 还有 invokeChannelRegistered 或者 invokeChannelReadComplete, 其实它就是包含了与 ChannelInboundInvoker 接口相对应的静态方法.
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
// 由于是让 ChannelHandler 从头开始执行, 所以这里的 next 为 HeadContext 实例.
// 判断是否要做资源检测. 值得注意的是: 在这些静态方法中只有该静态方法才会做资源检测.
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
EventExecutor executor = next.executor();
// 判断该方法是不是在 ChannelHandler 所关联的执行器中调用的.
if (executor.inEventLoop()) {
next.invokeChannelRead(m);
} else {
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
private void invokeChannelRead(Object msg) {
if (invokeHandler()) {
try {
// 这段代码被执行, 是因为 ChannelHandler 没有被移除并且不是有序执行.
// channelRead 方法就是 ChannelHandler 实现类中的方法了.
// this 就是和 ChannelHandler 实现类关联的 ChannelHandlerContext 了.
((ChannelInboundHandler) handler()).channelRead(this, msg);
} catch (Throwable t) {
invokeExceptionCaught(t);
}
} else {
// 该方法下面有讲.
fireChannelRead(msg);
}
}
/**
* ordered == true: 表示该 ChannelHandler 没有关联执行器 或者 执行器实现了 OrderedEventExecutor 接口.
* 注意下面是该变量取反.
*
* 返回 true:
* 当前已经执行了 ChannelHandler#handlerAdded(ChannelHandlerContext) 方法 或者
* 关联的执行器没有实现 OrderedEventExecutor 接口 并且
* 该 ChannelHandler 的状态是不确定有没有执行 handlerAdded 方法.
*
* 而且这里也保证了该 ChannelHandler 没有被移除, 也就是 handlerState != REMOVE_COMPLETE.
*/
private boolean invokeHandler() {
int handlerState = this.handlerState;
return handlerState == ADD_COMPLETE || (!ordered && handlerState == ADD_PENDING);
}
当前例子中 invokeChannelRead 静态方法中的第一个参数传递的是 HeadContext 也就是调用 ChannelHandler 双向链表中的第一个; 当然了也可以从中途执行, 这要看具体的业务逻辑了.
但是也要注意 ordered 变量, 该变量表示是否有序执行; 通过 invokeHandler() 方法可以判断出, 有序执行指的是当前 ChannelHandler 的状态为 ADD_COMPLETE 时则执行对应的方法; 而无序指的是当前 ChannelHandler 的状态为 ADD_PENDING 时也可以执行对应的方法. 如果是有序执行但是当前 ChannelHandler 的状态为 ADD_PENDING, 则调用 fireChannelRead(Object) 方法执行下一个 ChannelHandler.
因为当调用 ChannelHandler#handlerAdded(ChannelHandlerContext) 方法时, 才说明 ChannelHandler 被真正添加到了 ChannelPipeline 中.
如果想要调用下一个 ChannelHandler 实例中的 channelRead 方法时(也就是继续传播), 只需要直接调用 ctx.fireChannelRead(msg) 方法, 也就是 AbstractChannelHandlerContext#fireChannelRead(Object) 方法.
public ChannelHandlerContext fireChannelRead(final Object msg) {
// MASK_CHANNEL_READ = 32
invokeChannelRead(findContextInbound(MASK_CHANNEL_READ), msg);
return this;
}
ChannelHandlerContext 是一个双向链表, findContextInbound 方法的作用就是找到下一个符合条件的 ChannelHandler.
所谓的条件有两种, 第一种: 根据方法名可以看出下一个必须是 Inbound 类型; 第二种: 根据参数可以看出必须关注了 MASK_CHANNEL_READ 事件, 也就是实现了 channelRead 方法. 而 invokeChannelRead 方法就是前面说的静态方法了.
也就是说, 想不想传递给下一个 ChannelHandler 来继续处理这条消息, 完全是靠 AbstractChannelHandlerContext 类中的 fireChannelRead(Object) 方法决定.
写消息
当消息处理完成后, 一般都是需要回复. 可以通过 AbstractChannelHandlerContext#write(...) 方法进行回复.
public ChannelPromise newPromise() {
return new DefaultChannelPromise(channel(), executor());
}
// 这个 write 方法并不是真正的在写出数据, 而是将数据存放到一个成员变量中.
// 其 flush 方法才是真正写出数据.
public ChannelFuture write(Object msg) {
return write(msg, newPromise());
}
public ChannelFuture write(final Object msg, final ChannelPromise promise) {
write(msg, false, promise);
return promise;
}
// 该方法相当于 write 和 flush 方法一起调用.
public ChannelFuture writeAndFlush(Object msg) {
return writeAndFlush(msg, newPromise());
}
public ChannelFuture writeAndFlush(Object msg, ChannelPromise promise) {
write(msg, true, promise);
return promise;
}
上面这四个发送数据的方法, 并不是最终方法. 最终方法是由私有的 write 方法实现.
private void write(Object msg, Boolean flush, ChannelPromise promise) {
ObjectUtil.checkNotNull(msg, "msg");
try {
// 这里是做安全检查.
if (isNotValidPromise(promise, true)) {
ReferenceCountUtil.release(msg);
return;
}
}
catch (RuntimeException e) {
ReferenceCountUtil.release(msg);
throw e;
}
// findContextOutbound 方法与 findContextInbound 方法类似, 只不过是用来查询下一个 Outbound.
// 注意这里: 如果 flush 为 true, 则会找到实现了 write 和 flush 方法的 Outbound.
final AbstractChannelHandlerContext next = findContextOutbound(flush ?
(MASK_WRITE | MASK_FLUSH) : MASK_WRITE);
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
// 下面有说.
next.invokeWriteAndFlush(m, promise);
} else {
// 该方法中的逻辑, 如果 invokeHandler() 返回 true, 则直接执行 invokeWrite0 方法.
// 否则就会重新调用 write(Object, ChannelPromise) 方法,
// 找到下一个满足条件的 ChannelHandler.
next.invokeWrite(m, promise);
}
} else {
// 这里为什么不直接调用 executor.execute? 这里先留个坑.
final WriteTask task = WriteTask.newInstance(next, m, promise, flush);
if (!safeExecute(executor, task, promise, m, !flush)) {
task.cancel();
}
}
}
void invokeWriteAndFlush(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
// 内部直接调用 ((ChannelOutboundHandler) handler()).write(this, msg, promise);
invokeWrite0(msg, promise);
// 内部直接调用 ((ChannelOutboundHandler) handler()).flush(this);
invokeFlush0();
} else {
// 这里也是重新调用.
writeAndFlush(msg, promise);
}
}
现在需要返回一条消息, 所以在下面箭头指向的 ChannelHandler 中调用了 write 方法, 那么找到的第一个 Outbound 是 4 还是 2?
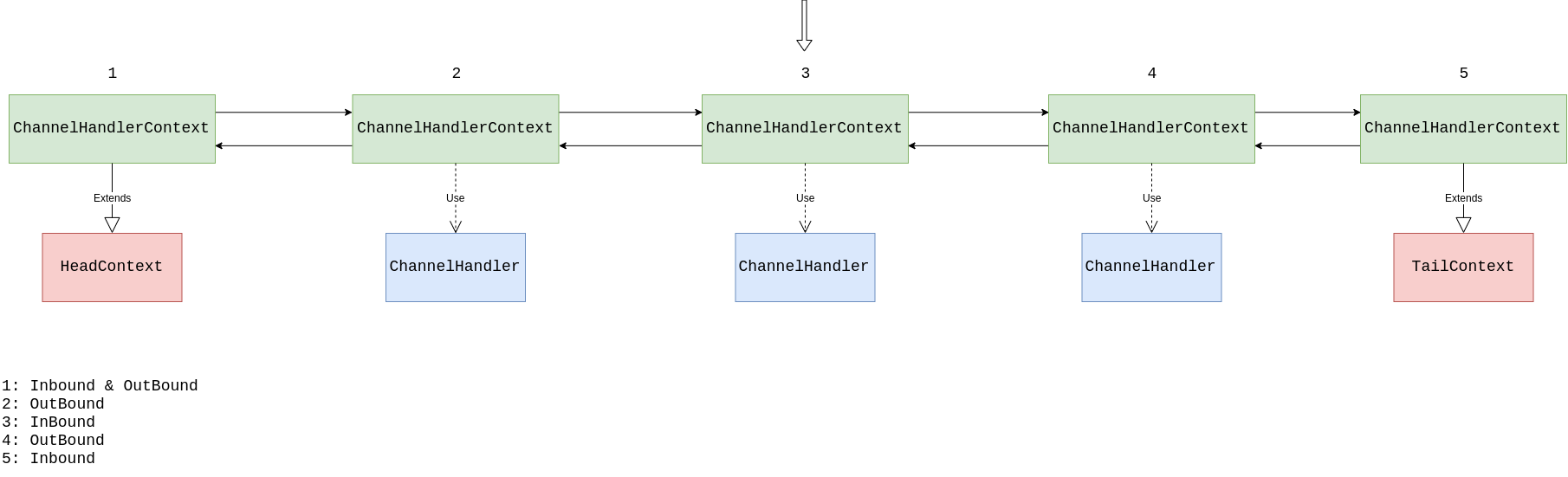
是 4 还是 2 这要看 write 方法是通过哪种方式调用的了, 这与上面说的读消息一样都是有两种方式; 这两种方式也就是别的文章说的 从 Pipeline 传播 和 从 Context 传播, 但我个人更倾向理解为: 在 Pipeline 中传播但是传播的方式不同, 第一种方式是从 Pipeline 最开始进行传播, 第二种方式为从某个 ChannelHandler 处直接传播.
如果在 3 中调用动态的 write 方法, 那么找到的第一个 Outbound 是 2, 这里没什么好解释的. 但是在大多数情况下需要从第一个 Outbound 开始执行, 也就是上图中的 4, 然后再执行 2 最后执行 1.
// 这两种方法都是一样的, 最终都会调用 pipeline 中的 write 方法.
channelHandlerContext.channel().write(...);
channelHandlerContext.pipeline().write(...);
pipeline 中的 write 方法源码如下.
// tail 就是 TailContext 对象.
public final ChannelFuture write(Object msg) {
// 这里就是 AbstractChannelHandlerContext#write(Object) 方法, 也就是上面说的那个.
return tail.write(msg);
}
值得注意的是, HeadContext 是必须要执行的, 不管是读还是写数据时. 这是因为写数据时该类的 write 方法会调用 AbstractChannel#write(Object, ChannelPromise) 方法将要发送的数据写入缓冲区. 可以把这个缓冲区理解为出站缓冲区.
public final void write(Object msg, ChannelPromise promise) {
// 该类是在 AbstractChannel 内部使用的数据结构, 用于存储准备发送的出站写请求.
// 该类的源码在 https://www.cnblogs.com/scikstack/p/13524675.html 查看
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
// ...
int size;
try {
// 这里调用的是 AbstractNioByteChannel 中的 filterOutboundMessage 方法.
// 该方法中会判断参数 msg 是不是以下类型:
// - ByteBuf: 则会判断是否为 DirectBuffer, 如果不是则转换为 DirectBuffer 后返回.
// - FileRegion: 则直接返回 msg.
//
// 对于其它类型则会抛出 UnsupportedOperationException 异常.
msg = filterOutboundMessage(msg);
// 这里调用的是 DefaultMessageSizeEstimator.HandleImpl#size() 方法. 获取 msg 的可读字节数.
//
// 如果是 ByteBuf 或 ByteBufHolder 类型则调用 readableBytes() 方法.
// 如果是 FileRegion 类型, 则会返回 0.
// 其它类型则返回 8.
size = pipeline.estimatorHandle().size(msg);
if (size < 0) {
size = 0;
}
} catch (Throwable t) {
safeSetFailure(promise, t);
ReferenceCountUtil.release(msg);
return;
}
outboundBuffer.addMessage(msg, size, promise);
}
flush 缓冲区
该方法与 write 方法的调用方式一样, 都是可以通过下面两种方式调用, 以及直接调用动态方法 flush().
channelHandlerContext.channel().flush(...);
channelHandlerContext.pipeline().flush(...);
最终也都是要调用HeadContext#flush(ChannelHandlerContext)方法, 在该方法中会调用AbstractChannel.AbstractUnsafe#flush()方法来发送数据.
public final void flush() {
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
return;
}
outboundBuffer.addFlush();
// inFlush0 为 true, 或者 ChannelOutboundBuffer#isEmpty() 为 true, 则直接返回不会继续执行.
// 否则会先判断通道如果没有打开或关闭会抛出对应的异常.
// 会调用 NioSocketChannel 实现类中的 doWrite(outboundBuffer); 方法.
flush0();
}
outboundBuffer.addFlush(); 关于该方法的具体操作, 可以通过 10.ChannelOutboundBuffer 文章查看.
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
SocketChannel ch = javaChannel();
// 通过 writeSpinCount 变量控制最大循环次数, 以防止单次写入操作消耗过多时间阻塞线程.
// 也就是说, 最多循环 16 次, 没写完也暂时不管了.
int writeSpinCount = config().getWriteSpinCount();
do {
if (in.isEmpty()) {
// 全部写完后清除 OP_WRITE 事件.
clearOpWrite();
return;
}
int maxBytesPerGatheringWrite = ((NioSocketChannelConfig) config).getMaxBytesPerGatheringWrite();
ByteBuffer[] nioBuffers = in.nioBuffers(1024, maxBytesPerGatheringWrite);
int nioBufferCnt = in.nioBufferCount();
switch (nioBufferCnt) {
case 0:
writeSpinCount -= doWrite0(in);
break;
case 1: {
ByteBuffer buffer = nioBuffers[0];
int attemptedBytes = buffer.remaining();
final int localWrittenBytes = ch.write(buffer);
if (localWrittenBytes <= 0) {
incompleteWrite(true);
return;
}
adjustMaxBytesPerGatheringWrite(attemptedBytes, localWrittenBytes, maxBytesPerGatheringWrite);
in.removeBytes(localWrittenBytes);
--writeSpinCount;
break;
}
default: {
long attemptedBytes = in.nioBufferSize();
// 该方法是线程安全的.
final long localWrittenBytes = ch.write(nioBuffers, 0, nioBufferCnt);
if (localWrittenBytes <= 0) {
incompleteWrite(true);
return;
}
// 待写入数据: 缓冲区中的内容, 写入数据: 已发送的内容.
//
// 这里有个 adjustMaxBytesPerGatheringWrite(..) 该方法的作用是, 通过本次写入数据和待写入数据进行动态调整 ByteBuffer 大小;
// 如果 待写入数据 等于 写入数据, 那么下次就扩大 ByteBuffer, 会扩大一倍.
// 如果 待写入数据 大于 阀值(4M), 并且本次写入的还没有待写入数据的一半多, 就将 ByteBuffer 调整为, 待写入数据 的一半大小.
adjustMaxBytesPerGatheringWrite((int) attemptedBytes, (int) localWrittenBytes, maxBytesPerGatheringWrite);
// 获取 flushedEntry 中 msg 消息, 如果 msg 类型不是 io.netty.buffer.ByteBuf 则直接返回.
// 如果 msg 的可读字节数, 小于等于了发送字节数, 就说明消息发送完毕就会将 flushedEntry 指向下一个 Entry.
// 否则就说明 msg 只发送了部分数据, 那么就会调整 msg 的可读字节数.
// 最后清除 NIO_BUFFERS 缓存的 ByteBuffer 引用, 以便可以进行 GC 处理.
in.removeBytes(localWrittenBytes);
--writeSpinCount;
break;
}
}
} while (writeSpinCount > 0);
incompleteWrite(writeSpinCount < 0);
}
ChannelHandler 生命周期
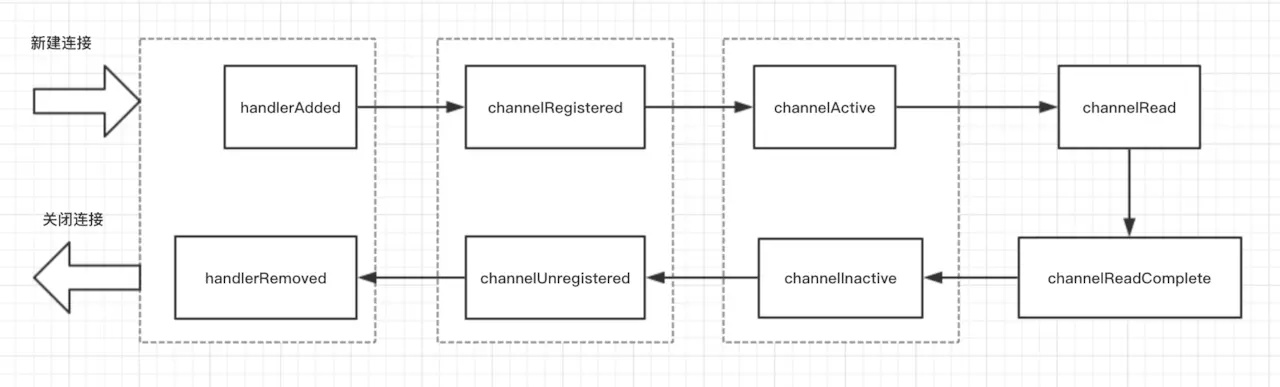
- handlerAdded: 新建立的连接会按照初始化策略, 把 handler 添加到 ChannelPipeline 中, 也就是 ChannelPipeline#add*, 例如: addLast addBefore 方法执行完成后的回调, 因为这些方法中都会调用 callHandlerAdded0 方法. ;
- channelRegistered: 当该连接分配到具体的 worker 线程后, 该回调会被调用, AbstractChannel#register 方法中调用 ChannelPipeline#fireChannelRegistered 方法;
- channelActive: AbstractChannel#bind 方法中添加任务调用 ChannelPipeline#fireChannelActive 方法;
- channelRead: 客户端向服务端发来数据, 每次都会回调此方法, 表示有数据可读;
- channelReadComplete: 服务端每次读完一次完整的数据之后, 回调该方法, 表示数据读取完毕;
- channelInactive: 断开连接时, 在 AbstractChannel.AbstractUnsafe#disconnect 和 AbstractChannel.AbstractUnsafe#deregister 方法中调用 ChannelPipeline#fireChannelInactive, 另外再 ChannelInboundHandlerAdapter#channelUnregistered 方法中会直接调用 ChannelHandlerContext#fireChannelInactive() 方法;
- channelUnRegistered: 断开连接时, 还是在 ChannelPipeline#deregister 方法中当调用完 AbstractChannel.AbstractUnsafe#fireChannelInactive 方法后会调用 ChannelPipeline#fireChannelUnregistered, 另外再 ChannelInboundHandlerAdapter#channelUnregistered 方法中会直接调用 ChannelHandlerContext#fireChannelUnregistered() 方法;
- handlerRemoved: 对应 handlerAdded, 将 handler 从该 channel 的 pipeline 移除后的回调方法 ChannelPipeline#remove.
参考资料
Netty详解之九:使用ByteBuf
Netty使用案例 -发送队列积压导致内存泄漏(二)
Netty详解之六:Channel
Netty源码分析系列之writeAndFlush()下
3. Netty源码阅读之Channel
Netty-11-channelHandler的生命周期
Netty学习笔记之ChannelHandler
ChannelHandler生命周期
Netty中ChannelHandler的生命周期
类AbstractChannelHandlerContext
netty 通道处理器上下文
Netty pipeline分析(一)
Netty源码解析之pipeline传播事件机制
Netty学习笔记(番外篇) - ChannelHandler、ChannelPipeline和ChannelHandlerContext的联系