一。基本原理

贝叶斯公式

二。在文本分类中的情况

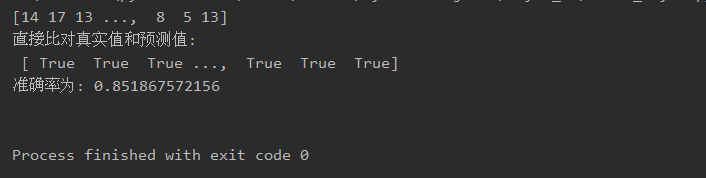
sklearn实现
1 from sklearn.datasets import fetch_20newsgroups 2 from sklearn.model_selection import train_test_split 3 from sklearn.feature_extraction.text import TfidfVectorizer 4 from sklearn.naive_bayes import MultinomialNB 5 6 def news_classification(): 7 """ 8 朴素贝叶斯对新闻进行分类 9 :return: 10 """ 11 #1.获取数据 12 news=fetch_20newsgroups("c:/new",subset="all") 13 #print(news) 14 #2.划分数据集 15 x_train,x_test,y_train,y_test=train_test_split(news.data,news.target) 16 # print(x_train) 17 #3.特征工程:文本特征抽取-tfidf 18 transfer=TfidfVectorizer() 19 x_train=transfer.fit_transform(x_train) 20 x_test=transfer.transform(x_test) 21 #4.朴素贝叶斯预估器' 22 estimator=MultinomialNB() 23 estimator.fit(x_train,y_train) 24 #5.模型评估 25 y_predict=estimator.predict(x_test) 26 print(y_predict) 27 print("直接比对真实值和预测值: ",y_predict==y_test) 28 #方法2:直接计算准确率 29 score=estimator.score(x_test,y_test) 30 print("准确率为:",score) 31 if __name__ == "__main__": 32 news_classification()