学习任何一门语言的第一步,首先要写个'hello world',这算是程序员的一个传统。但在写之前,还有注意几个问题。
首先,python是一门脚本语言,而脚本语言的特点就是:我们写的代码会先由解释器进行编译以后,再去执行。但是当我们的程序运行在操作系统之上时,系统并没有那么智能,能够自动识别出我们要用哪个解释器去解释我们的代码(windows则通过后缀名关联执行程序,所以不用声明也可以,但是我们的代码更多在linux上运行,所以解释器的声明算是必须的),所以,我们必须要声明我们的解释器是什么。
#! /usr/bin/python
在文件的第一行写上这段代码,当文件被执行的时候,系统会去 /usr/bin/python 中找到解释器,然后用它来解释我们的代码。但是,正如我在第一篇介绍python安装中提到的,系统自带的python和我们源码安装的python的路径是不同的,而我们并不能保证我们程序运行的系统中,python就装在这里。
所以,用下面这种方法兼容性更好:
#! /usr/bin/env python
如果有linux基础的同学会知道 env 是linux中调用环境变量的,这段代码的意思是去系统的环境变量中寻找python,找到了就用它来解释代码。这样做能获得更高的兼容性,无论是什么方法安装的,只有在系统环境变量中,就都能找到。
这时,有些人就有疑问了,不是说#后面的都是注释吗,注释是不被执行的,为什么这句代码有效果?
其实解释器的声明也算是注释的一种,只不过它比较特殊,记住能这样用就好,也不用太去深究,下面的字符集声明也是一样的,反正特殊的就这两个,也没什么记不住的。
有了以上基础,就可以开始写'hello world'了,但作为一名中国的程序员,我还想写‘你好,世界’怎么办?
如果是在3.x中,那就可以直接开始了。但如果是2.x的话,那还需要进行字符集的声明。
关于字符集的概念可以是查看一下其他相关文章,作为一名以懒惰催生生产力的程序员,还是不造重复的轮子的好。下面是一些总结:
1.python2.x默认使用的是acsii码,这个编码是不支持中文的
2.为了支持世界上的所有文字,而诞生了Unicode,而为了压缩Unicode在显示英文时占用的空间,又诞生了utf-8,这也是我们常用的字符集。
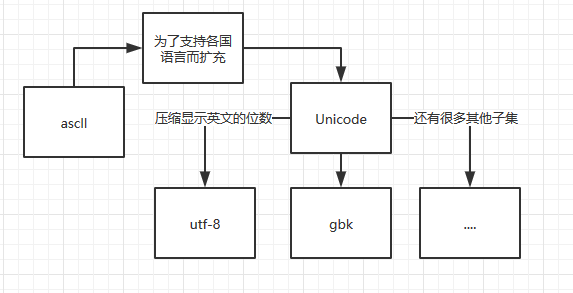
这里的意思并不是说其他字符集都是从Unicode发展而来的,关于字符集的发展历史是个很复杂的东西,个人也不是很清楚。
这个图这样画是为了表达Unicode的桥梁作用。因为当我们要将编码从gbk转到utf-8时,首先要将gbk转换成Unicode,然后再从Unicode转到utf-8,否则是不能直接转换的。
其实使用utf-8就已经总够了,我这里单独列出gbk是因为很多人在windows的cmd里面使用中文时,就算声明了字符集,但还是显示乱码。
此时,要注意一个问题,虽然你是用了utf-8,但cmd的交互窗口却不是以utf-8去显示,详情看图:
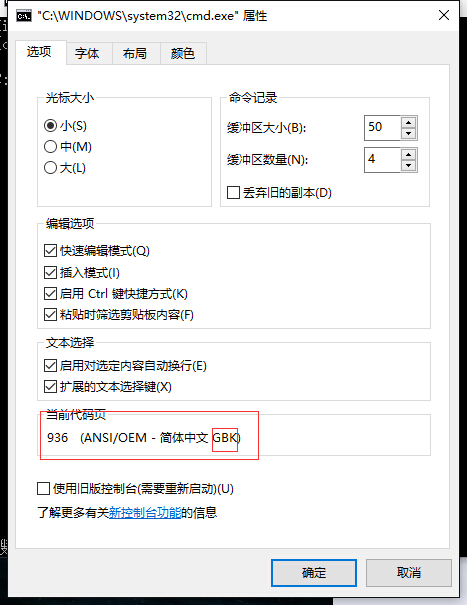
其使用的是gbk,而你输出的字符却用的是utf-8,用gbk去解读utf-8当然会出现乱码。所以很多时候要注意一下显示终端用的是什么编码。
这个时候要显示中文,修改一下显示的字符就好,如果修改不了,那就下载个IDE就好,同样也有注意IDE的显示编码问题,用什么IDE看个人习惯,逐个尝试就好,我用的是pycharm,具体不再多说。
讲完为何要声明字符集,接下来讲如何声明,其实和声明解释器类似,可以在文件的第二行写:
#-*- coding: UTF-8 -*-
下面这种写法也行:
# coding: UTF-8
小写的utf也行,还有一些其他写法,例如把:换成=号的,个人习惯用第一种写法。
讲完了解释器声明和字符集声明以后,我们得出了python的同样起手式:
#! /usr/bin/env pyhton # -*- coding:utf-8 -*-
好,学会了起手式后,就可以开始写‘hello world’了。
#! /usr/bin/env pyhton # -*- coding:utf-8 -*- print "hello world"
print "你好,世界"
解释:print是python的一个关键字,其作用是将其后面的东西显示到终端,专业术语称为“打印”,可以打印各种数据类型,例如字符串,数字,元祖,字典等,具体这些是什么以后会讲。
而我们在第一篇中的3.x新特性中提到,print这个关键字,被print()方法取代了,所以3.x中要这样写:
#! /usr/bin/env pyhton # -*- coding:utf-8 -*- print ("hello world")
print ("你好,世界")
而在2.7中,上面两种方法都是支持的,这也是2.7被称为过度版本的原因之一。
好了,第一个python程序就写完了,就是这么简单!嗯……好吧,还算简单吧。
补充:
既然Unicode被称为万国码,那么是否可以直接将一个字符串用Unicode编码呢?
答案是可以,代码如下:
print u"hello world" print (u"hello world")
直接在字符串前加个 u 就可以了,不过一般情况下使用中文不一定非要这样,但如果某个方法一定要传Unicode对象的时候,那就要这样写了。