字符编码的种类和进化流程
在哪里需要字符编码的转换?
输入保存至计算机流程
解释器读写python文件流程
python默认的编码
两种python的数据类型以及对应的存入数据
小结:
python 中的unicode的正确用法
python编码中最常见的两个错误
encode和decode
unicode error实验
encode error实验
decode error实验
实践中的注意事项:
字符编码:
字符编码(英语:Character encoding)、字集码是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。
字符编码的种类和进化流程
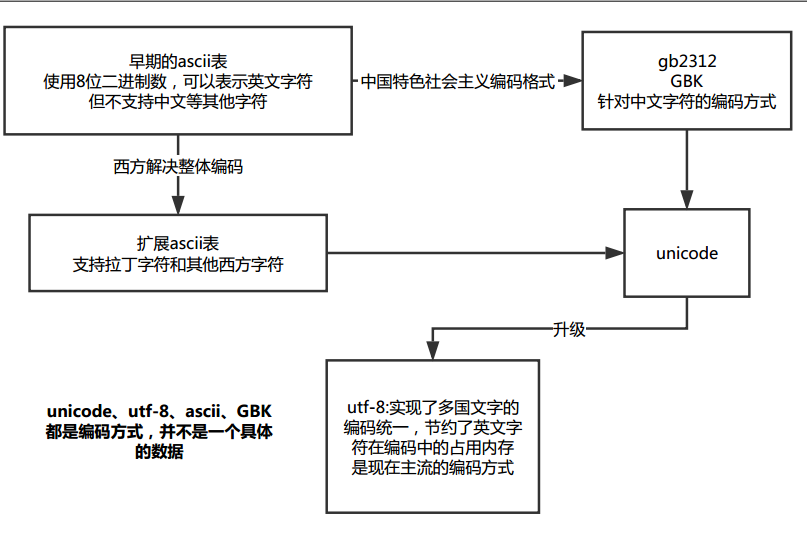
注意:上图中的扩展ascii表和gb3212等编码方式到unicode编码方式中间的箭头,仅仅表示编码的历史进化,而不是unicode来自gbk等编码方式
常用转换关系:
gbk<=======>unicode
utf-8<=======>unicode
就是通过以上的转换,将GBK编码方式的文件,转换成UTF-8格式的
在哪里需要字符编码的转换?
了解了字符编码的种类之后,我们需要了解,在什么地方,使用什么样的编码,以及为什么要使用这些编码方式。
输入保存至计算机流程
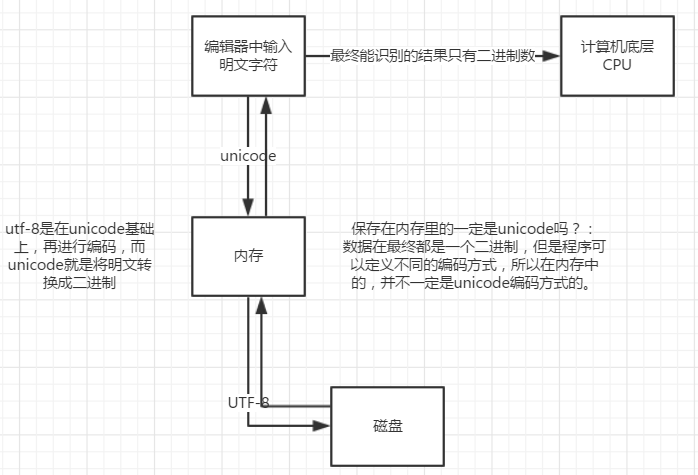
上图表示了计算机解读和存储我们在编辑器中输入字符的过程。可能中间部分的表述并不是很准确(也可以是gbk,主要取决于编辑器的编码方式),但是能大致的说明“明文————>高低电平”的转换过程。
在这里我们需要特别注意的是文本编辑器存储到内存过程中,是不是内存中只能存在unicode方式的编码。
解释器读写python文件流程
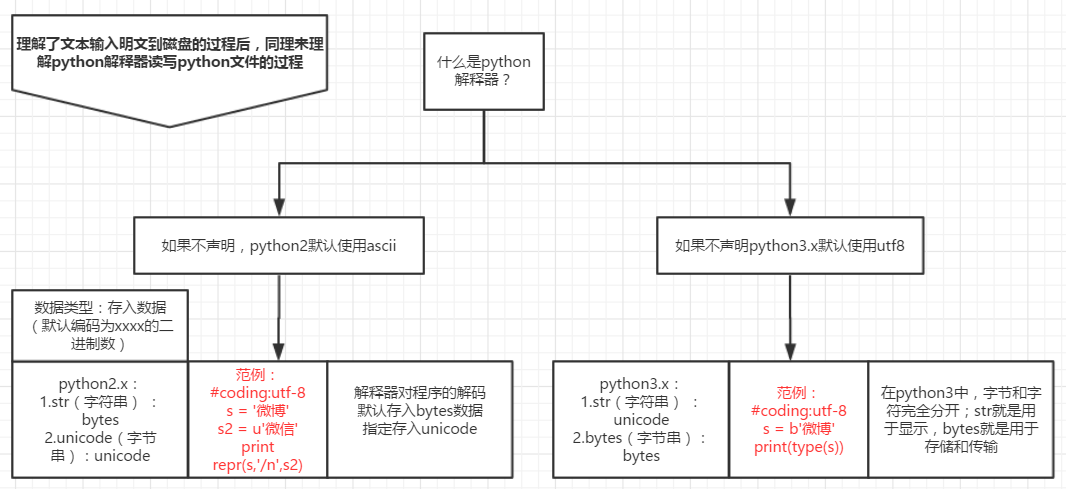
python默认的编码
-
python2 默认使用ascii
-
python3 默认使用utf-8
两种python的数据类型以及对应的存入数据
数据类型:存入数据(默认编码为xxxx的二进制数)
-
python2.x:
1.str(字符串):bytes
2.unicode(字节串):unicode -
python3.x:
1.str(字符串):unicode
2.bytes(字节串):bytes
首先解决一下“什么是字节串?”这个问题:
python2.x中str的类型存入数据为bytes(这也是为什么在出现python2的unicode错误时,在原定义的字符串前添加一个‘u’,就有可能解决问题)。bytes代表的是(二进制数的序列),通过ascii编码后才是我们看到的字符形式,如果我们单独取出一个字节,可以发现它的切片是一个数字
print(b'12ffse'[0])
由此也可以推出,字节类型只能允许ascii字符?
简单来说就是把人类通用的语言符号翻译成计算机通用的对象,而反向的翻译过程自然就是解码了。Python 中的字符串类型代表人类通用的语言符号,因此字符串类型有encode()方法;而字节类型代表计算机通用的对象(二进制数据),因此字节类型有decode()方法
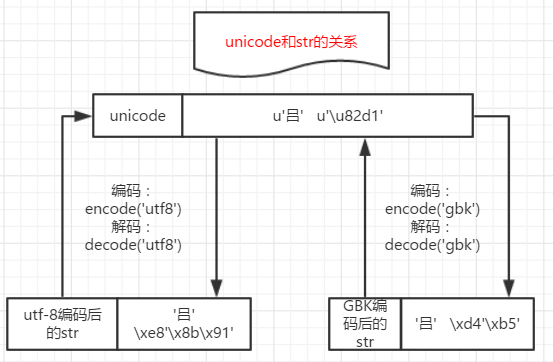
为什么说python3规范了默认str的字符编码是unicode使编码更加规范方便了呢?
可以参考一下上方的unicode和utf8以及gbk之间的转换关系。
同时测可以测试一下以下代码:
print(type('hello'+u'world'))
(在python2环境中运行)
相同的方式,在python3中可以这样实验:
print('hello'+b'world')
这个实验的目的就是:在不同的两个解释器中,拼接两个不同编码类型的字符串。
从而可以看出python2在字符编码上的“宽容”容易造成一些未知错误。而python3在字符编码方面的严格要求,决定了程序运行的规范和稳定性
更多关于字符编码理解的实验:http://python.jobbole.com/84839/
小结:
文本编辑器的编码,由文本编辑器的设置决定
语言解释器的解码方式,有语言解释器的默认设置和打开代码的抬头(python解释器默认设置第一二行能有效定义解码方式;#coding:UTF-8)
如果说,语言解释器的解码方式和文本编辑器的编码不同,就会出现错误。
如果说,文本编辑器打开文件的编码和文件存储定义的解码方式不同,也会出现错误
说到错误,上面链接的作者在git上有一篇关于python中unicode正确使用方法的文章https://github.com/rainyear/pytips/blob/master/Markdowns/2016-03-17-Bytes-decode-Unicode-encode-Bytes.md ,我觉得里面例子很有意义,所以下面就是照着他的方式敲一遍实验代码用于明确python中的编码错误。
python 中的unicode的正确用法
python编码中最常见的两个错误
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 0-1: invalid continuation byte
encode和decode
encode和decode都是翻译的过程,而ascii和unicode在本质上都像是一本将人类语言和就算计语言对应起来的字典。而且这两本本字典有厚有薄,ASCII 只包含了26个基本拉丁字母、阿拉伯数目字和英式标点符号一共128个字符,因此只需要(不占满)一个字节就可以存储,而 Unicode 则涵盖的数据除了视觉上的字形、编码方法、标准的字符编码外,还包含了字符特性,如大小写字母,共可包含 1.1M 个字符,而到现在只填充了其中的 110K 个位置。
unicode error实验
利用一个函数来展现上面的两个错误
encode error实验
def try_encode(s, encoding = 'utf-8'):
try:
print(s.encode(encoding))
except UnicodeEncodeError as err:
print(err)
# 定义一个测试字符串默认编码的函数,传入默认解码方式为utf-8
s = '4b'
try_encode(s)
try_encode(s,'ascii')
# 使用ascii的方式解码
b = '城'
try_encode(b)
try_encode(b,'ascii')
try_encode(b,'GB2312')反馈结果:
b'4b'
b'4b'
b'xe5x9fx8e'
'ascii' codec can't encode character 'u57ce' in position 0: ordinal not in range(128)
b'xb3xc7'结果分析:
由于 UTF-8 对 ASCII 的兼容性,"4b" 可以用 ASCII 进行编码;而 "城"不能使用ascii编码,因为它已经超出了 ASCII 字符集的 128 个字符,所以引发了 UnicodeEncodeError;而 "城" GB2312 中的码位是 b'xd3xea',与 UTF-8 不同,但是仍然可以正确编码。因此如果出现了 UnicodeEncodeError 说明你用错了字典,要翻译的字符没办法正确翻译成码位!
decode error实验
def try_decode(s, decoding = 'utf-8'):
try:
print(s.decode(decoding))
except UnicodeDecodeError as err:
print(err)
s = b'4b'
try_decode(s)
try_decode(s,'ascii')
b = b'xb3xc7'
try_decode(b)
try_decode(b,'ascii')
try_decode(b,'GB2312')
try_decode(b,'GBK')
try_decode(b,'Big5')
try_decode(b.decode('GB2312').encode())
# byte - decode - unicode - encode - byte反馈结果:
4b
4b
'utf-8' codec can't decode byte 0xb3 in position 0: invalid start byte
'ascii' codec can't decode byte 0xb3 in position 0: ordinal not in range(128)
城
城
傑
城一般后续出现的字符集都是对 ASCII 兼容的,可以认为 ASCII 是他们的一个子集,因此可以用 ASCII 进行解码(编码)的,一般也可以用其它方法;对于不是不存在子集关系的编码,强行解码有可能会导致错误或乱码!
实践中的注意事项:
-
记清楚编码和解码的方向
-
在python中尽量采用utf-8,输入或者输出的时候根据需求确定是否需要编码成二进制