咱们接着上一篇的内容继续。这一篇主要回顾子查询,联合查询,复制表这三类内容。
上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语句,但是实际应用中的业务逻辑往往会非常复杂,所以会用到一些比较复杂的查询,如子查询,联合查询。
1.子查询
当一个查询是另一个查询的条件时,称为子查询。但是说到子查询又不的不说它与嵌套查询两者的区别,下面一张图来说明

下面再用一条sql语句来说明他们的关系。
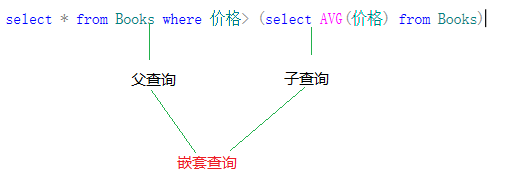
其中在查询中又分为嵌套子查询和相关子查询,他们之间的区别就是查询是否依赖与外部的查询,嵌套子查询的执行不依赖与外部的查询,而相关子查询的执行依赖于外部查询。
select * from Books where 价格 < (select AVG(价格) from Books) --查询所有价格高于平均价格的书信息
上边的一条sql语句便是嵌套子查询,来分析他的执行过程。
①先执行子查询,即查询出Books表中书的平均价格,然后将结果传递给父查询,作为父查询的条件。
②执行父查询,返回结果。
select * from Books as a where 价格 < (select AVG(价格) from Books as b where a.类编号=b.类编号)--查询表中大于该类图书价格平均值的图书信息
上边一条语句便是嵌套子查询,来分析他的执行过程。
①先从父查询中读取一个数据,即类编号,然后将类编号传递给子查询。
②执行子查询,将这个类编号的书的平均价格查询出来,并将其传递给父查询。
③父查询判断这条数据是否满足条件,不满足就排除,满足则保留。
④然后父查询获取下一条数据中的类编号,重复①到③步骤,直到外层所有数据被处理完。
2.表联合查询
SQL最强大的功能之一就是能在数据查询的执行中联结(join)表。联结是利用SQL的SELECT能执行的最重要的操作,在能够有效地使用联结前,先了解一下数据库的三个范式。
1NF(原子性):字段不可再分,否则就不是关系型数据库。例:学生表里,一个列里同时存储【姓名】和【年龄】,这个就不符合原子性。
2NF(唯一性):有主键,非主键字段全部依赖于主键;或者说,一个表中只能说明一个事务。例:学生表里,主键是【学号】,有一列存储【班级总人数】,【班级总人数】和主键【学号】没有依赖,这种情况不符合唯一性。
3NF(无传递依赖):主键字段不能相互依赖,不能传递依赖。例:学生表里主键是【学号】,存储一列为【所属班级】,又存储一列【班级总人数】,【所属班级】依赖【学号】,【班级总人数】依赖【所属班级】,有传递依赖,不符合第三范式。
三范式是解决了数据库的冗余问题,但是在很多业务逻辑下,必须同时查询两个或两个以上的表,这个时候就用到了表的联合(结)查询。
笛卡儿积( 笛卡儿积(cartesian product):由没有联结条件的表关系返回的结果为笛卡儿积。即将是第一个表中的行数乘以第二个表中的行数。
联合查询,就是先求出所查表的笛卡尔积之后,在对笛卡儿积进行筛选。
而连接类型又分为好几种,如下图所示。

- (Inner) Join: 如果表中有至少一个匹配,则返回行
- Left Join: 即使右表中没有匹配,也从左表返回所有的行
- Right Join: 即使左表中没有匹配,也从右表返回所有的行
- Full Join: 只要其中一个表中存在匹配,就返回行
- Cross Join: 就是返回两个关联表的笛卡儿积
内连接(Inner Join)是最常用的连接操作。内连接有两种不同的语法 ,一种是显示连接符号,另一种是隐式链接符号,他们的区别就是用不用Join关键字。

语法:select <要选字段> from <主要资料表> <join方式> <次要资料表> [on <join 规则>] --在内连接中,Join规则不相符的都会被排除:排他性 写法1:select * from A inner join B on A.name=B.name --显示连接符号 写法2:select * from A,B where A.name=B.name --隐式链接符号
--对照上图,内连接查询出a和b两表的公共集c
外连接并不要求连接的两表的每一条记录在对方表中都一条匹配的记录,要保留所有记录的表(即使这条记录没有匹配也要保留)称为保留表,保留表在join关键字左边的连接就称为左连接,在右边就称为右连接,当两表记录都要保存时,称为全外连接。左外连接查询时,如果右表中无匹配记录, 来自于右表的所有列的值设为 NULL,右外连接,全外连接也是这种情况。
语法:select <要选字段> from <left资料表> <left|right>[outer] join <right资料表> [on <join 规则>] --在外连接中:包容性 左外连接:select * from A left (outer)join B on A.name=B.name --对照上图即左外连接查询出表a的所有集合和b中和a公共集合 a1+c 右外连接:select * from A right(outer)join B on A.name=B.name --对照上图即右外连接查询出表a的所有集合和b中和a公共集合 b1+c
全外连接:select * from A full(outer)join B on A.name=B.name --对照上图即全外连接查询出表a的所有集合和b中所有集合 a1+c+b1
3.复制表
有时候需要将一个表的数据直接导入到一个新表中,这时候可以用select...into...from或者insert into...select,不过两者有区别。
select * into NewTable from Books --使用这条语句时,数据库中必须原先不存在表NewTable ,若数据库中原先有此表,则会报错 insert into NewTable select * from Books --这条语句中,数据库中必须原先存在表NewTable, 若不存在,则执行报错
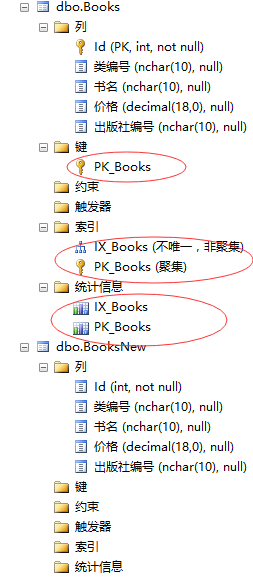
还有一个问题需注意:在使用复制表语句时,只会复制表的数据和结构,但是表中的主键,外键,约束,索引这些信息不会复制过来。
这个就先写这么多吧,下边还有视图,存储过程,事物等等,以后慢慢写吧,也算一个温故而知新的过程。