NEON 被设计为一种附加的加载/存储体系结构,以从 C、C++ 等语言提供良好的矢量化编译器支持。丰富的 NEON 指令集在宽 64 位和 128 位向量寄存器上运行,支持高水平的并行。NEON 指令简单易懂,也使得手工编码对于需要最高性能的应用程序来说更加容易。
NEON 技术的一个关键优势是,指令构成了正常的 ARM 或 Thumb 代码的一部分,使得编程比外部硬件加速器更简单。可以使用 NEON 指令读写外部内存,在 NEON 寄存器和其他 ARM 寄存器之间移动数据,并执行 SIMD 操作。
NEON 架构使用 32×64 位寄存器文件。这些实际上是浮点单元(VFPv3)使用的相同寄存器。浮点寄存器被重新用作 NEON 寄存器并不重要。所有已编译的代码和子例程都将符合 EABI,它指定哪些寄存器可以被破坏,哪些寄存器必须被保留。编译器可以自由地使用代码中的任何位置的 NEON 或 VFPv3 寄存器来实现浮点值或 NEON 数据。
NEON 体系结构允许 64 位或 128 位并行。这个选择是为了使 NEON 单元的大小易于管理(矢量ALU很容易变得相当大),同时仍然可以从向量化中获得良好的性能收益。NEON 体系结构也没有指定指令计时,可能需要不同数量的循环才能在不同的处理器上执行相同的指令。
与在VFP的通用性
ARM 架构可以支持各种不同的 NEON 和 VFP 选项,但实际上您只能看到组合:
- No NEON or VFP.
- VFP only.
- NEON and VFP.
这些是体系结构的供应商实现选项,因此对于基于 ARM 的设计的特定实现是固定的。
NEON 和 VFP 的关键区别在于,NEON 只对向量工作,不支持双精度浮点数(双精度由 VFP 支持),不支持平方根、除法等复杂的运算。NEON 拥有 32 个 64 位的注册库。如果 NEON 和 VFPv3 都实现了,这个注册库就会在硬件中在它们之间共享。这意味着 VFPv3 必须以其具有 32 个双精度浮点寄存器的 VFPv3-D32 形式存在。这使得对上下文切换的支持更加简单。保存和恢复 VFP 上下文的代码还保存和恢复 NEON 上下文。
数据类型
NEON 指令对以下类型的数据类型进行操作:
- 32-bit single precision floating-point
- 8, 16, 32 and 64-bit unsigned and signed integers
- 8 and 16-bit polynomials
NEON 指令中的数据类型说明符包括表示数据类型的字母和表示宽度的数字。它们从指令助记符中分离出来,例如,VMLAL.S8。所以你有以下几种可能:
- Unsigned integer U8 U16 U32 U64.
- Signed integer S8 S16 S32 S64.
- Integer of unspecified type I8 I16 I32 I64.
- Floating-point number F16 F32.
- Polynomial over {0,1} P8.
---------Note---------- 不支持F16用于数据处理操作。只支持将其转换为或从其转换为某种格式。
多项式算法在实现某些加密或数据完整性算法时非常有用。
在{0,1}上加两个多项式就相当于一个位排除法OR。多项式附加结果与传统加法不同。
在{0,1}上乘两个多项式,首先要像常规乘法那样确定部分乘积,然后将部分乘积作 OR,而不是按常规相加。多项式乘法的结果与传统乘法不同,因为它需要对部分乘积进行多项式相加。
NEON 技术兼容 IEEE 754-1985,但只支持圆到最近的舍入模式。这是大多数高级语言(如 C 和 Java)使用的舍入模式。此外,NEON 指令总是把 denormal 看成零。
NEON 寄存器
寄存器 bank 可以被看作是 16 个 128 位寄存器(Q0-Q15)或 32 个 64 位寄存器(D0-D31)。每个 Q0-Q15 寄存器映射到一对 D 寄存器,如 Figure 7-3 所示。

Figure 7-4 中寄存器的视图由使用的指令的形式决定。这样软件就不必显式地改变状态。

单个元素也可以作为标量访问。这种双重观点的优点是,它适用于扩大或缩小结果的数学运算。例如,将两个 D 寄存器相乘得到一个 Q 寄存器结果。双视图使寄存器 bank 得到更有效的使用。
NEON 数据处理指令通常包含 Normal、Long、Wide、Narrow 和 Saturating variants.
- Normal 指令可以对任何向量类型进行操作,并生成与操作数向量大小相同、类型通常相同的结果向量。
- Long 指令作用于双字向量操作数并产生一个四字向量结果。结果元素的宽度通常是操作数的两倍,并且类型相同。长指令是使用附加到指令上的 L 来指定的。Figure 7-5 显示了这一点,在操作之前提升了输入操作数。

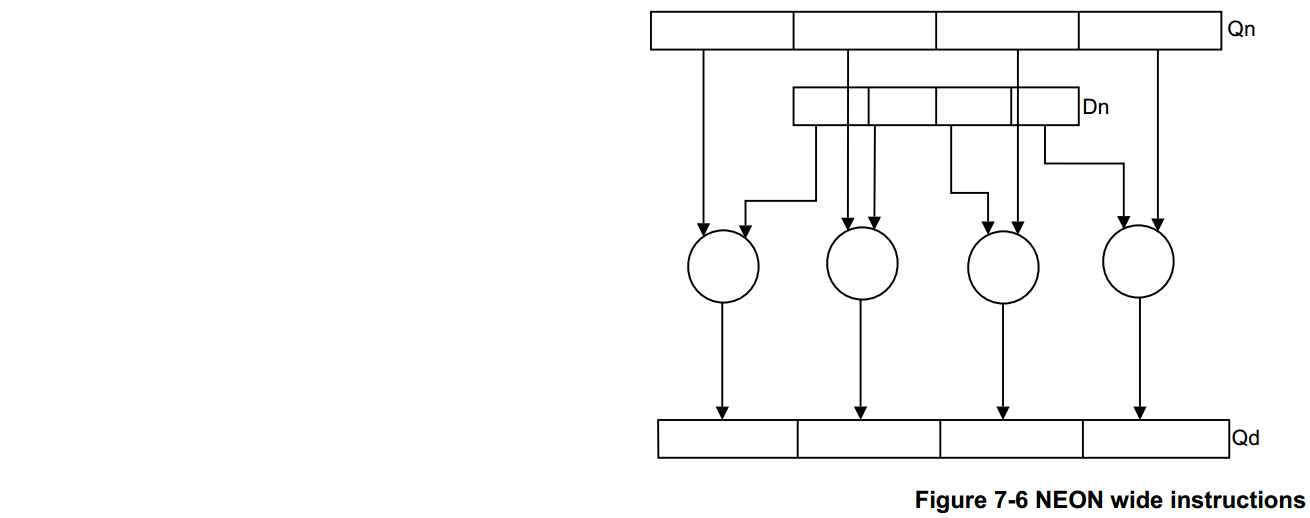
- Wide 指令操作一个双字向量操作数和一个四字向量操作数,产生一个四字向量结果。结果元素和第一个操作数的宽度是第二个操作数元素宽度的两倍。宽指令有一个 W 附加到指令。Figure 7-6 显示了这一点,输入双字操作数在操作之前被提升。
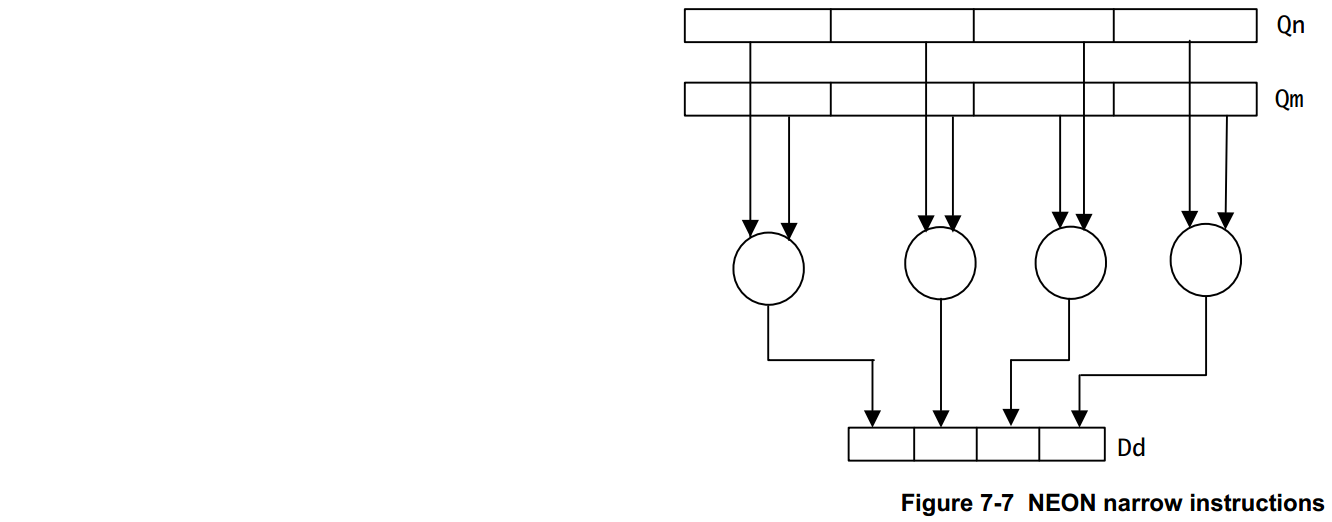
- Narrow 指令作用于四字向量操作数,并产生双字向量结果。结果元素通常是操作数元素宽度的一半。窄指令是使用附加到指令的 N 来指定的。Figure 7-7 显示了这一点,输入操作数在操作之前被降级。
一些 NEON 指令与向量一起作用于标量。标量可以是 8、16、32 或 64 位。使用标量的指令可以访问寄存器组中的任何元素,尽管对于多重指令存在差异。该指令使用双字向量的索引来指定标量值。乘法指令只支持 16 位或 32 位标量,并且只能访问寄存器组中的前 32 位标量(即,16 位标量的 D0-D7 或 32 位标量的 D0-D15)。
NEON 指令集
NEON 指令的所有助记符(与 VFP 一样)都以字母“V”开头。指令通常能够操作不同的数据类型,这是在指令编码中指定的。大小用指令的后缀表示。元素的数量由指定的寄存器大小表示。
例如:看下面这条指令: VADD.I8 D0, D1, D2 其中
- VADD 表明是一条 NEON ADD 指令
- I8 后缀表明是 8 位整数被加
- D0、D1、D2 表明使用的是 64 位寄存器(D1、D2 是操作数,D0 是目的地址)
所以这个指令并行执行 8 个加法。
有些操作对于输入和输出具有不同大小的寄存器。
VMULL.S16 Q2, D8, D9
这条指令执行 D8 和 D9 中打包的 4 个 16 位的数据相乘,并在 Q2 中生成 4 个 32位的结果。
VCVT 指令在单精度浮点数和 32 位整数、定点和(如果实现的话)半精度浮点数之间转换元素。