首先,给出官方文档的链接:
https://pytorch.org/docs/stable/generated/torch.gather.html?highlight=gather#torch.gather
然后,我用白话翻译一下官方文档。
gather,顾名思义,聚集、集合。有点像军训的时候,排队一样,把队伍按照教官想要的顺序进行排列。
还有一个更恰当的比喻:gather的作用是根据索引查找,然后讲查找结果以张量矩阵的形式返回。
1. 拿到一个张量:
-
import torch
-
a = torch.arange(15).view(3, 5)
a = tensor([
[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
2. 生成一个查找规则:
(张量b的元素都是对应张量a的索引)
-
b = torch.zeros_like(a)
-
b[1][2] = 1
-
b[0][0] = 1
b = tensor(
[[1, 0, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 0, 0]])
3. 根据维度dim开始查找:
-
c = a.gather(0, b) # dim=0
-
d = a.gather(1, b) # dim=1
c= tensor([
[5, 1, 2, 3, 4],
[0, 1, 7, 3, 4],
[0, 1, 2, 3, 4]])
d=tensor([
[ 1, 0, 0, 0, 0],
[ 5, 5, 6, 5, 5],
[10, 10, 10, 10, 10]])
ok, 看到这儿应该有点费劲儿了。
如果dim=0,则b相对于a,它存放的都是第0维度的索引;
如果dim=1,则b相对于a,它存放的都是第1维度的索引;
我举个栗子,当dim=0时,b[0][0]的元素是1,那么它想要查找a[0][1]中的元素;
当dim=1时,b[0][0]的元素是1,那么它想查找的a[1][0]中的元素;
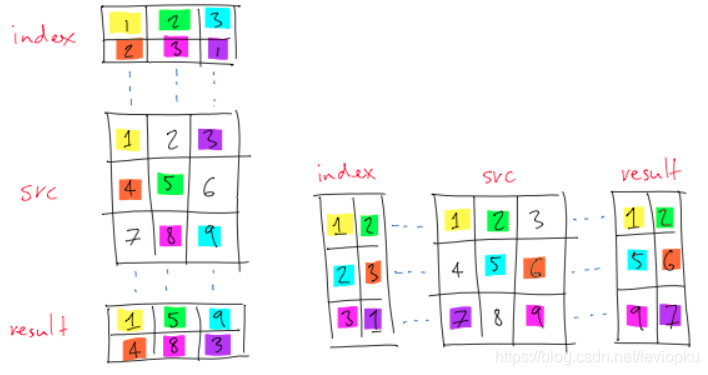
最后的输出都可以看作是对a的查询,即元素都是a中的元素,查询索引都存在b中。输出大小与b一致。
找一张网图来描述,这里的index对应b,src对应a,格子里的数值都减1,左图对应dim=0,右图对应dim=1。
原文链接:https://blog.csdn.net/leviopku/article/details/108735704

