[版权申明:本文系作者原创,转载请注明出处]
文章出处:http://www.cnblogs.com/sdksdk0/p/5585355.html
作者: 朱培 ID:sdksdk0
--------------------------------------------------
在我之前的一篇博客中,已经分享了关于hadoop的基本配置,地址:http://blog.csdn.net/sdksdk0/article/details/51498775,但是那个是使用与初学者学习和测试的,今天用分享的这个比上次那个要复杂一些,主要是加了zookeeper和两台namenode的配置,同时使用这种方式,可以解决服务器的脑裂问题。
一、hdfs的HA机制
NameNode服务器一台是ACTIVE和一台是STANDBY。通过Qjournal(日志管理系统) 使用zkfc(基于zookeeper失败切换控制)
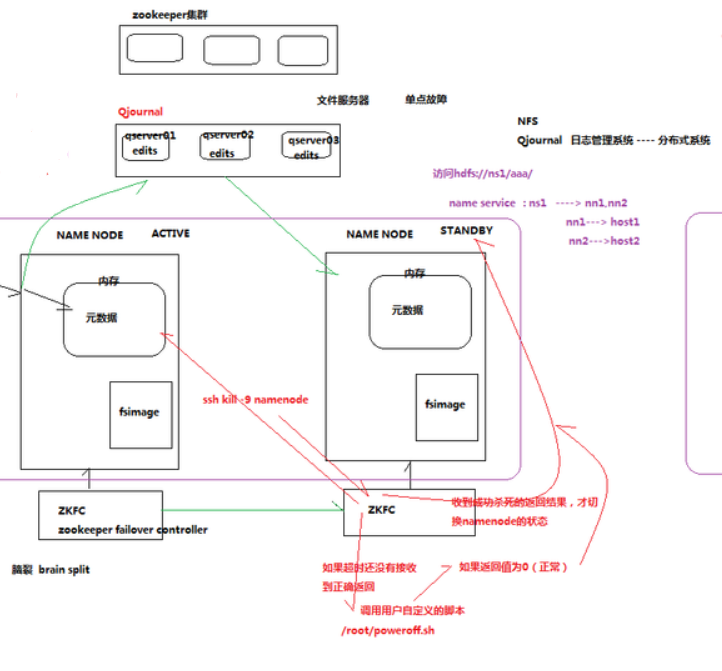
如何防止脑裂现象: 当ACTIVE假死的时候,STANDBY的zkfc会发出指令 ssh kill-9 namenode 返回0(成功杀死,返回1则杀死失败)的时候再去通知第二台namenode去切换状态。 若无返回码的时候(超时未响应),则启动proweroff.sh(用户自定义的脚本)给第一台namenode断电,返回0则执行正常,然后去切换。
当第一台机器断电的时候(指活跃状态的namenode和zkfc都断电了),则第2台的zkfc会执行proweroff.sh。
关键词: 1、有两个namenode,分别是active和standby.
2、有两个zkfc来监控和管理两个namenode的状态
3、元数据日志edits由一个专门的日志系统负责管理--qjoournal
4、zkfc及qjournal的功能都要依赖于zookeeper的服务来实现
5、zkfc做状态切换时有两个防止脑裂的机制--ssh和shell脚本。
二、Hadoop集群的配置
打开hadoop的安装目录,如果还不会下载或者基础都不会使用的请看文章开头我提供的链接,请先学习基础配置。 我这里主要使用了5台虚拟机来模拟搭建这整个集群环境。
主机名 IP地址 主要功能
- ubuntu1 192.168.44.128 namenode zkfc ResourceManager
- ubuntu2 192.168.44.131 namenode zkfc ResourceManager
- ubuntu3 192.168.44.132 DataNode、NodeManager、JournalNode、QuorumPeerMain
- ubuntu4 192.168.44.133 DataNode、NodeManager、JournalNode、QuorumPeerMain
- ubuntu5 192.168.44.134 DataNode、NodeManager、JournalNode、QuorumPeerMain
我们可以先来配置ubuntu1,然后剩下的就scp到其他机器上就可以了 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/admin1/hadoop/HAhadoop/tmp/hadoop</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>ubuntu3:2181,ubuntu4:2181,ubuntu5:2181</value>
</property>
</configuration>
hdfs-site.xml
1 <configuration> 2 <!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 --> 3 <property> 4 <name>dfs.nameservices</name> 5 <value>ns1</value> 6 </property> 7 <!-- ns1下面有两个NameNode,分别是nn1,nn2 --> 8 <property> 9 <name>dfs.ha.namenodes.ns1</name> 10 <value>nn1,nn2</value> 11 </property> 12 <!-- nn1的RPC通信地址 --> 13 <property> 14 <name>dfs.namenode.rpc-address.ns1.nn1</name> 15 <value>ubuntu1:9000</value> 16 </property> 17 <!-- nn1的http通信地址 --> 18 <property> 19 <name>dfs.namenode.http-address.ns1.nn1</name> 20 <value>ubuntu1:50070</value> 21 </property> 22 <!-- nn2的RPC通信地址 --> 23 <property> 24 <name>dfs.namenode.rpc-address.ns1.nn2</name> 25 <value>ubuntu2:9000</value> 26 </property> 27 <!-- nn2的http通信地址 --> 28 <property> 29 <name>dfs.namenode.http-address.ns1.nn2</name> 30 <value>ubuntu2:50070</value> 31 </property> 32 <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> 33 <property> 34 <name>dfs.namenode.shared.edits.dir</name> 35 <value>qjournal://ubuntu3:8485;ubuntu4:8485;ubuntu5:8485/ns1</value> 36 </property> 37 <!-- 指定JournalNode在本地磁盘存放数据的位置 --> 38 <property> 39 <name>dfs.journalnode.edits.dir</name> 40 <value>/home/admin1/hadoop/HAhadoop/journaldata</value> 41 </property> 42 <!-- 开启NameNode失败自动切换 --> 43 <property> 44 <name>dfs.ha.automatic-failover.enabled</name> 45 <value>true</value> 46 </property> 47 <!-- 配置失败自动切换实现方式 --> 48 <property> 49 <name>dfs.client.failover.proxy.provider.ns1</name> 50 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 51 </property> 52 <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行--> 53 <property> 54 <name>dfs.ha.fencing.methods</name> 55 <value> 56 sshfence 57 shell(/bin/true) 58 </value> 59 </property> 60 <!-- 使用sshfence隔离机制时需要ssh免登陆 --> 61 <property> 62 <name>dfs.ha.fencing.ssh.private-key-files</name> 63 <value>/home/admin1/.ssh/id_rsa</value> 64 </property> 65 <!-- 配置sshfence隔离机制超时时间 --> 66 <property> 67 <name>dfs.ha.fencing.ssh.connect-timeout</name> 68 <value>30000</value> 69 </property> 70 </configuration>
mapred-site.xml
1 <configuration> 2 <!-- 指定mr框架为yarn方式 --> 3 <property> 4 <name>mapreduce.framework.name</name> 5 <value>yarn</value> 6 </property> 7 </configuration>
yarn-site.xml
1 <configuration> 2 3 <!-- 开启RM高可用 --> 4 <property> 5 <name>yarn.resourcemanager.ha.enabled</name> 6 <value>true</value> 7 </property> 8 <!-- 指定RM的cluster id --> 9 <property> 10 <name>yarn.resourcemanager.cluster-id</name> 11 <value>yrc</value> 12 </property> 13 <!-- 指定RM的名字 --> 14 <property> 15 <name>yarn.resourcemanager.ha.rm-ids</name> 16 <value>rm1,rm2</value> 17 </property> 18 <!-- 分别指定RM的地址 --> 19 <property> 20 <name>yarn.resourcemanager.hostname.rm1</name> 21 <value>ubuntu1</value> 22 </property> 23 <property> 24 <name>yarn.resourcemanager.hostname.rm2</name> 25 <value>ubuntu2</value> 26 </property> 27 <!-- 指定zk集群地址 --> 28 <property> 29 <name>yarn.resourcemanager.zk-address</name> 30 <value>ubuntu3:2181,ubuntu4:2181,ubuntu5:2181</value> 31 </property> 32 <property> 33 <name>yarn.nodemanager.aux-services</name> 34 <value>mapreduce_shuffle</value> 35 </property> 36 </configuration>
slaves
1 ubuntu3 2 ubuntu4 3 ubuntu5
还有就是修改一下主机名。 sudo vi /etc/hostname ubuntu1 以及hosts的内容:
192.168.44.128 ubuntu1 192.168.44.131 ubuntu2 192.168.44.132 ubuntu3 192.168.44.133 ubuntu4 192.168.44.134 ubuntu5
注意:一定要把原来的那两天127.0.1.1 这一条给删除掉,一个hosts文件中,不能出现主机名相同和ip地址不同的情况,我开始就是因为这个因为,折腾了很久,datanode就是搭建不起来。
启动过程:
1、启动zookeeper集群 分别在ubuntu3,4,5中输入 开启服务: bin/zkServer.sh start 查看状态: bin/zkServer.sh status
2、启动journalnode 分别在ubuntu3,4,5中输入 sbin/hadoop-daemon.sh start journalnode 运行jps命令检验,多了JournalNode进程
3、格式化HDFS
在ubuntu1上执行命令:
bin/hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/HAhadoop/tmp,然后将/HAhadoop/tmp拷贝到ubuntu2的/HAhadoop/下。
scp -r tmp/ ubuntu2:/home/admin1/hadoop/HAhadoop/
4、格式化ZKFC(在ubuntu1上执行即可) bin/hdfs zkfc -formatZK
5、启动HDFS(在ubuntu1上执行) sbin/start-dfs.sh
6、启动YARN(在ubuntu1上执行) sbin/start-yarn.sh
如果是在ubuntu1中启动的话,那么默认的浏览窗口会是这样: ubuntu2是Active的,ubuntu1是一个Standby状态,
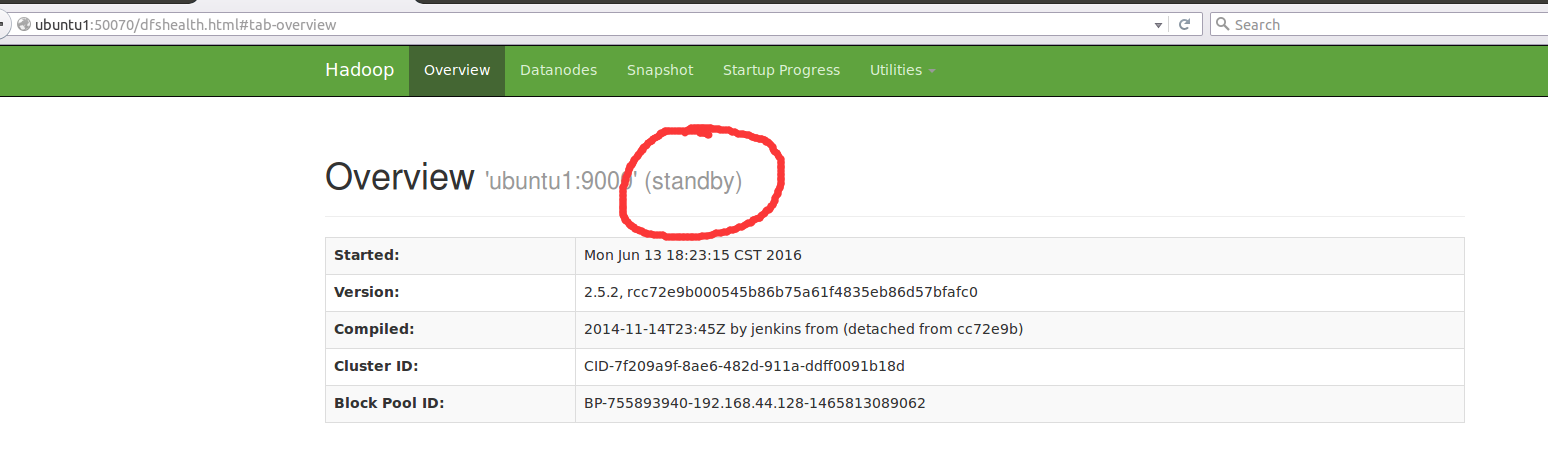
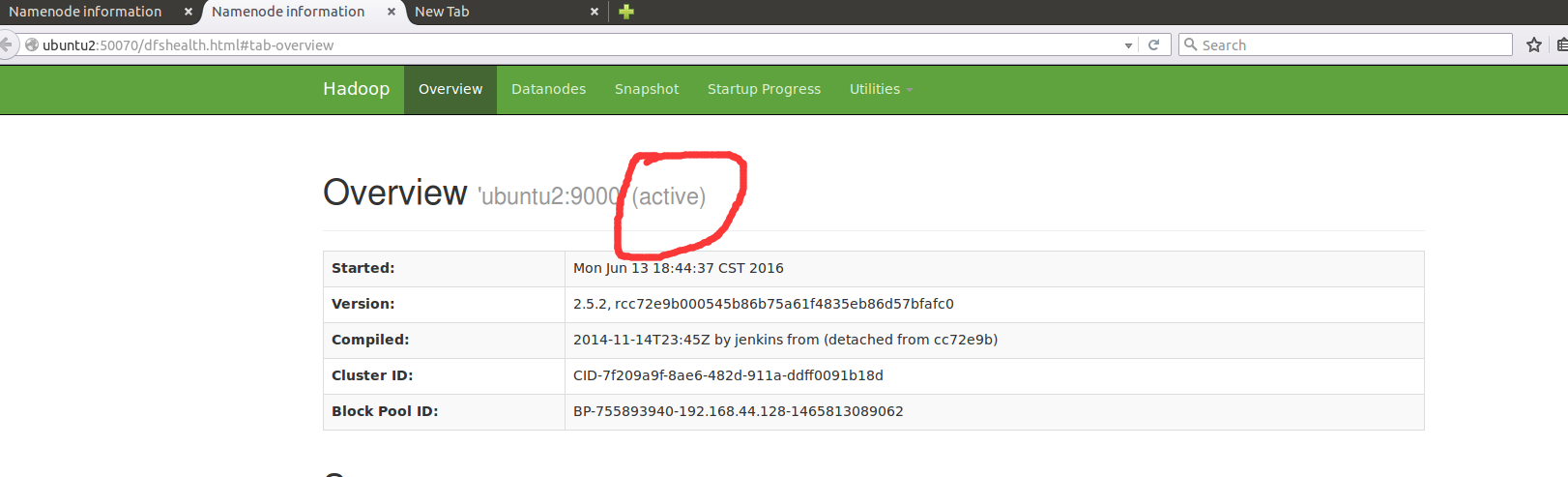
这个时候如果你去ubuntu2里面把这个namenode进程杀死的话,ubuntu1会自动切换为Active,ubuntu2会变成无法连接。
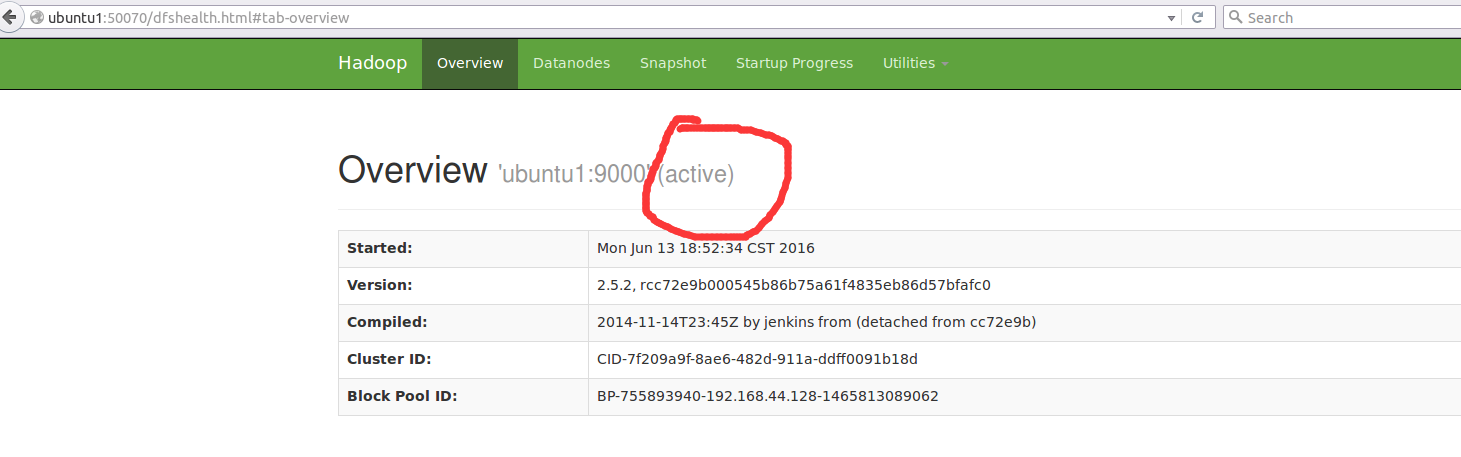
这样就实现了服务器的动态切换,这样万一有一个namenode宕机了,剩下了一台会自动切换。这种使用了zookeeper切换的就是前面说到的HA机制了。
当整个集群搭建完毕的效果就会是这样,如果用jps去查看一下:
在两个namenode节点上面会这样显示:

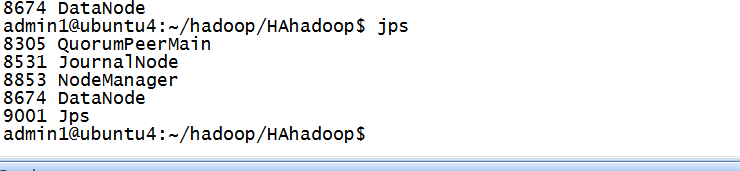
在剩下的3个datanode上面会这样:
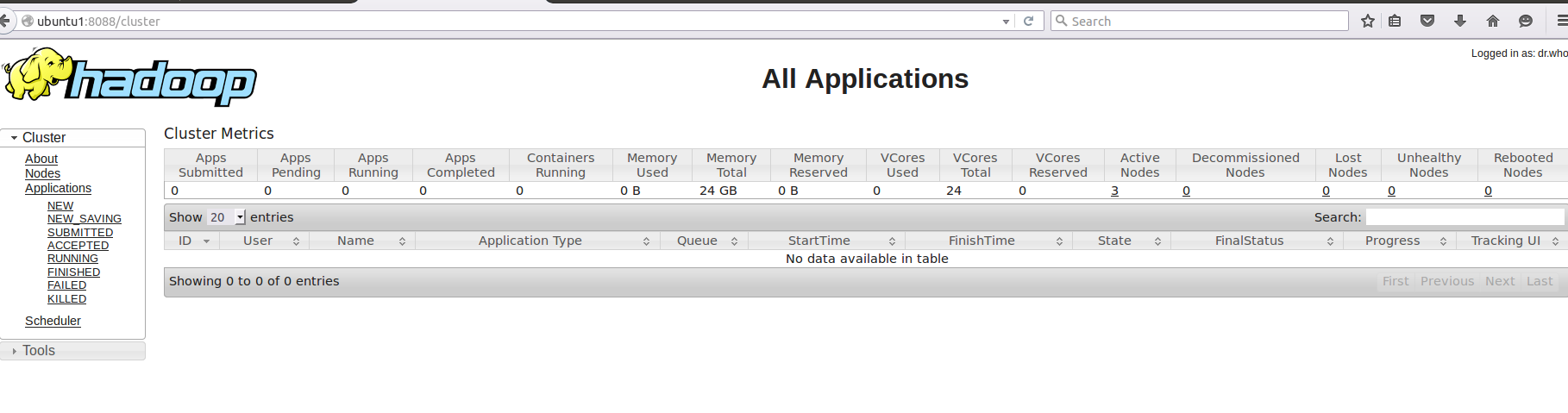
可以通过访问ubuntu2:8088/Cluster来查看:活跃节点是3个
到这里整个集群环境就搭建完毕了,当然如果你电脑配置不是很高的话,可以选择把datanode直接放在namenode一起配置也可以。