前言
平时用selenium的时候一般都是直接用xpath获取需要点击的元素的位置
但是的项目里用到了一个元素,检查以后发现是个伪元素
网上百度查的方法都不管用,思路也没有说明白,导致摸索了很长时间
感谢博主提供的思路:点击跳转
实现
我们先看下具体的栗子,这里我选用的是【百度疫情实时大数据报告】,后期可能会过期,但具体思路大家明白就好。

打开网址,默认是选中的是【默认确诊】,这里我想点击【累计确诊】。
我们可以看到,当前元素是属于label标签的

使用css选择器时,选择的是“div节点”(父节点)的位置,然后再在div(父节点)的选择后边加上div的子节点“i”(伪元素存在的节点)
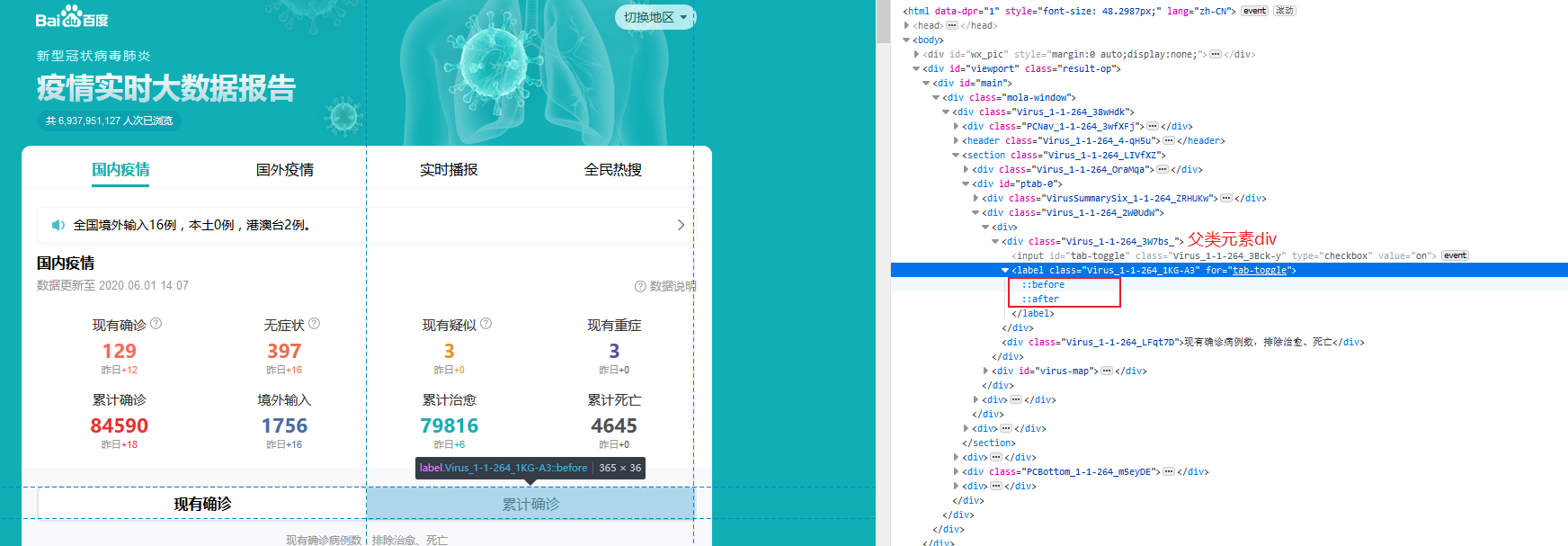
所以我们的css选择器的写法是:div.Virus_1-1-264_3W7bs_>label,这里的意思就是(父类div.父类calss>子元素label)
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://voice.baidu.com/act/newpneumonia/newpneumonia/?qq-pf-to=pcqq.group')
# 如果需要切换回【现有确诊】,只需要重复执行这段代码。
driver.find_element_by_css_selector('div.Virus_1-1-264_3W7bs_>label').click()
time.sleep(3)
driver.close()