本次实验结合Socket API编程接口、系统调用机制及内核中系统调用相关源代码、socket相关系统调用的内核处理函数结合起来分析,并在x86_64环境下对Linux5.0以上的内核进行跟踪验证。
1.Linux系统调用
在Linux中系统调用是由Linux内核提供的各种功能服务,为了便于调用Linux提供了一个底层C语言库libc(glibc是GNU版本的libc,其他类似库还有uclivc,klibc),目前glibc是linux标准函数库,这些系统都打包成了标准C函数,这些函数一般就成为了系统调用。系统调用可以通过syscall()函数发起,或者调用每一个对应的C函数,这些函数定义在<syscall.h>或者<unistd.h>头文件中。Linux系统中通过软中断0x80待用实现控制权转移给内核,内容执行完成后返回结果。所有系统调用在linux内核队员文件目录“arch/x86/kernel”中的各种文件中定义。

Linux部分系统调用表(https://github.com/mengning/linux/blob/master/arch/x86/entry/syscalls/syscall_32.tbl)
系统调用与API的区别:
API就是应用程序接口,是一些预定义的函数,跟内核没有必然的联系,提供应用程序与开发人员基于某软件或硬件的以访问一组例程的能力,而又无需访问源码或理解内部工作机制的细节。
系统调用就是一种特殊的接口,通过这个接口,用户可以访问内核空间。系统调用规定了用户进程进入内核的具体位置,具体步骤:用户进程-->系统调用-->内核-->返回用户空间。系统调用规定了用户进程进入内核空间的具体位置,下图表示了两者的区别:
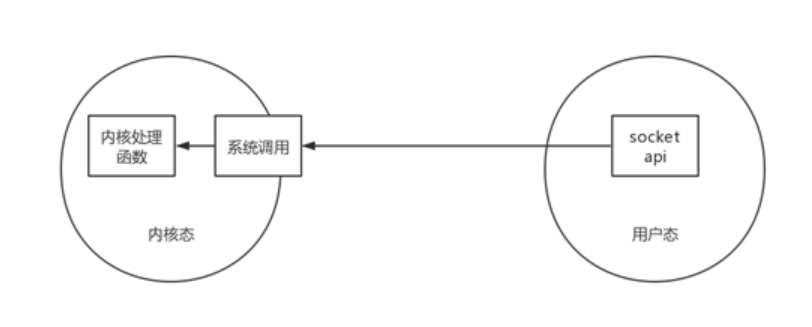
我们知道操作系统通过系统调用为运行于其上的进程提供服务,那么系统调用是怎么工作的呢?我们以一个系统调用xyz()为例,下图展示了一次系统调用的过程:

如上图所示,系统调用执行流程如下:
1)应用程序代码调用xyz(),该函数是一个包装系统调用的库函数;
2)库函数xyz()负责准备向内核传递的参数,并触发软中断以切换内核态;
3)CPU被软中断打断后,执行中断处理函数,即系统调用处理函数(system_call);
4)系统调用处理函数调用系统调用服务例程(sys_xyz),真正开始处理该系统调用。
系统调用的实现来自Glibc,几乎所有C程序都要调用Glibc的动态链接库libc.so中的库函数。这些库函数的源码是不可见的,可通过objdump或gdb工具对代码进行汇编反编译,摸清大体的过程,对此不必太过纠结,知道原理就好。
2. 分析函数调用
针对上次实验中的hello/hi程序(),我们跟踪main函数中的StartReplyhi的调用过程,在syswrapper.h中找到:
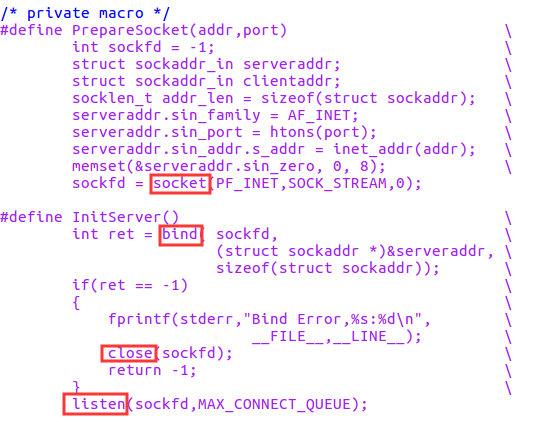
我们找到了对应的sokcet(),listen(),bind()以及close()等几个函数,通过查阅资料得知,linux内核为所有与socket有关的操作都提供了一个统一的系统调用入口,但在用户程序界面上则通过C语言程序库c.lib提供了诸多库函数,看起来好像都是独立的系统调用一样。内核中为socket设置的总入口代码在net/socket.c中,实际上调用的是SYSCALL_DEFINE2(),在该函数中我们找到对应入口:

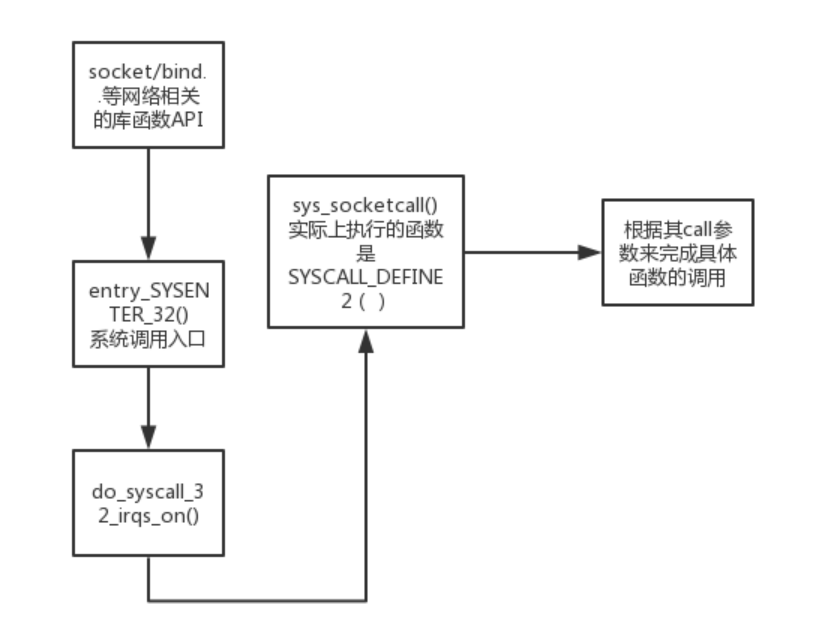
看上去逻辑不是很复杂,核心就是一个switch语句,根据不同的call来进入不同的分支,调用不同的内核处理函数,如__sys_listen,__sys_bind函数等等,结合我们的replyhi的执行过程,socket(),listen(),bind(),close() 分别对应不同的系统调用,比如listen() 库函数最终对应于__sys_listen(),这些不同的系统调用传给SYSCALL_DEFINE2执行不同的内核操作,用图来表示就是:
3. 断点跟踪系统调用
下面来验证我们的想法,试试跟踪一下bind和listen系统调用。
首先启动MenuOS,具体启动方式见上篇博客,在gdb中,对__sys_bind,__sys_listen加断点,
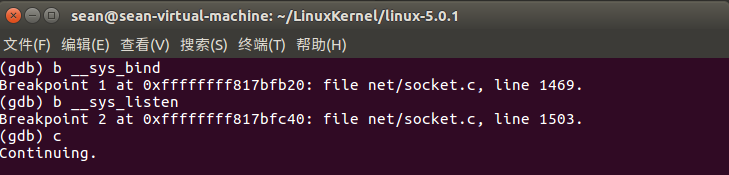
之后继续运行MenuOS,依次执行
输入replyhi-->gdb输入c-->MenuOS输入hello:
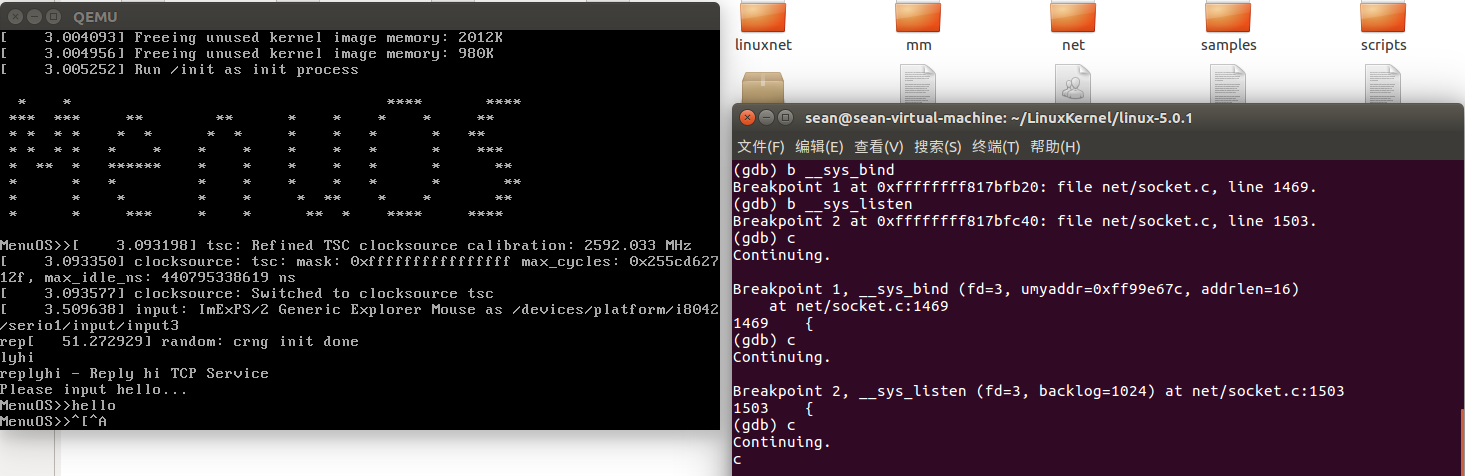
如图,gdb已经成功跟踪到了系统调用,实验结果证明我们的猜想没有错,涉及到socket的系统调用都是用统一的入口sys_socketcall,再通过SYSCALL_DEFINE2进入对应的分支,调用不同的系统调用,如本次实验中的__sys_listen,__sys_bind等。
下面我们介绍这两个系统调用到底干了什么,根据gdb给出的函数信息,在linux-5.0.1/net/socket.c中找到了相应的函数定义,由官方给出的注释,bind()系统调用仅负责将进程的名字与socket绑定,此外,bind()也负责将该socket转入内核处理,至于处理本地地址,这是网络协议需要做的事情,具体解释如下:
int __sys_bind(int fd, struct sockaddr __user *umyaddr, int addrlen) { struct socket *sock; struct sockaddr_storage address; int err, fput_needed; /* *以fd为索引从当前进程的文件描述符表中,找到对应的file实例, *然后从file实例的private_data中,获取socket实例 */ sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock) { /* * 将用户空间的地址拷贝到内核空间的缓冲区中 */ err = move_addr_to_kernel(umyaddr, addrlen, &address); if (!err) { /* * SELinux相关,不需要关心。 */ err = security_socket_bind(sock, (struct sockaddr *)&address, addrlen); /* * 如果是TCP套接字,sock->ops指向的是inet_stream_ops, * sock->ops是在inet_create()函数中初始化,所以bind接口 * 调用的是inet_bind()函数。 */ if (!err) err = sock->ops->bind(sock, (struct sockaddr *) &address, addrlen); } fput_light(sock->file, fput_needed); } return err; } SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen) { return __sys_bind(fd, umyaddr, addrlen); }
int __sys_listen(int fd, int backlog) { struct socket *sock; int err, fput_needed; int somaxconn; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock) { /* * sysctl_somaxconn存储的是服务器监听时,允许每个套接字连接队列长度 * 的最大值,默认值是128 */ somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn; /* * 如果指定的最大连接数超过系统限制,则使用系统当前允许的连接队列 * 中连接的最大数。 */ if ((unsigned int)backlog > somaxconn) backlog = somaxconn; err = security_socket_listen(sock, backlog); if (!err) /* * 从这里开始,socket以后所用的函数将根据TCP/UDP而视协议而定 */ err = sock->ops->listen(sock, backlog); fput_light(sock->file, fput_needed); } return err; } SYSCALL_DEFINE2(listen, int, fd, int, backlog) { return __sys_listen(fd, backlog); }