5 The Raft consensus algorithm
Raft实现一致性:首先选举一个leader,leader完全管理log的同步。leader从client接收log entries,复制给其他servers,并通知servers状态机何时执行log entries是安全的。一个leader的好处:简化了同步日志的管理,leader不用咨询其他servers就能决定新的entries放在log的哪里,从leader到其他servers的数据流向简单。一个leader失效或者和其他servers失联,则新的leader会被选举。
Raft将一致性问题分解为三个相对独立的自问题:
- Leader election: 当一个存在的leader失效后,一个新的leader必须被选出。
- Log replication: leader必须从clients接收log entries,并复制到集群,强制其他servers的logs保持一致。
- Safety: 关键是状态机的安全。如果任何server的状态机执行了一个log entry,那么其他server不可能在相同的log index处执行不同的命令。
Raft一致性算法总结(不包含membership changes和log compaction)
- State
- 所有servers的持久化state(响应RPCs前持久化更新)
- currentTerm: server的最新term(初始化为0,单调递增)
- votedFor: 在当前term收到vote的candidateId(没有vote为null)
- log[]: log entries;每个entry包含状态机执行的命令,leader收到这个entry的term
- 所有servers的易失state
- commitIndex: 已知被committed的最高log entry的index(初始化为0,单调递增)
- lastApplied: 状态机执行的最高的log entry的index
- leaders的易失state(election后重新初始化)
- nextIndex[]: 对于每个server,下一条发给server[i]的log entry的index。(初始化为leader最后一个log的index+1)
- matchIndex[]: 对于每个server,已知被复制到server[i]上的最高log entry的index。
- 所有servers的持久化state(响应RPCs前持久化更新)
- RequestVote RPC(candidate调用收集votes)
- Arguments
- term: candidate的term
- candidate Id: 请求vote的candidate
- lastLogIndex: candidate的最后一个log entry的index
- lastLogTerm: candidate的最后一个log entry的term
- Results
- term: currentTerm,candidate自我更新
- voteGranted: true代表candidate收到vote
- Receiver implementation
- 如果
term < currentTerm,响应false - 如果votedFor是null或者candidateId,candidate的log至少和被请求者一样新,则vote。
- 如果
- Arguments
- AppendEntries RPC(leader调用复制log entries或者心跳机制)
- Arguments
- term: leader的term
- leaderId: follower可以重定向到clients
- prevLogIndex: 新entry之前的log entry
- prevLogTerm: preLogIndex entry的term
- entries[]: 存储的log entries。(空代表心跳,为了效率可能发送多个)
- leaderCommit: leader的commitIndex
- Results
- term: currentTerm,leader自我更新
- success: 如果follower含有匹配prevLog的entry则为true
- Receiver implementation
- 如果
term < currentTerm则响应true - 如果log不包含匹配prevLog这样的entry,响应false
- 如果存在的entry和新的entry冲突,删除存在的entry及之后的entry
- 追加log中没有的新entries。
- 如果
leaderCommit > commitIndex,commitIndex = min{leaderCommit, index of last new entry}
- 如果
- Arguments
- Rules for Servers
- All Servers
- 如果
commitIndex > lastApplied:增加lastApplied,状态机执行log[lastApplied]。 - 如果RPC请求或者响应中有
T > currentTerm,设置currentTerm = T,转为follower
- 如果
- Followers
- 响应candidates和leaders发送的RPCs请求
- 如果election timeout没有从当前leader收到AppendEntries RPC或者candidate的请求vote,转为candidate
- Candidates
- 转为candidate,开始election
- 增加currentTerm
- vote自己
- 重置election timer
- 发送RequestVote RPCs给其他所有servers
- 如果收到多数servers的votes: 转为leader
- 如果收到新leader的AppendEntries RPC: 转为follower
- 如果election timeout: 开始新的election
- 转为candidate,开始election
- Leaders
- election成功:发送空的AppendEntries RPCs(心跳)给每个server;idle期间重复发送防止election timeouts
- 如果从client收到命令:追加entry到本地log,状态机执行之后再响应。
- 如果一个follower
last log index >= nextIndex:发送AppendEntries RPC从nextIndex开始的log entries- 成功:更新nextIndex和matchIndex
- 因为log不一致失败:减少nextIndex并重试
- 如果存在一个N,
N > commitIndex,多数matchIndex[i] >= N,并且log[N].term == currentTerm,设置commitIndex = N。
- All Servers
- Raft保证这些属性
- Election Safety: 在一个term至多选出一个leader
- Leader Append-Only: 一个leader从不覆盖或者删除他的log,它只追加新的entries。
- Log Matching: 如果两个logs有一个entry有相同的index和term,那么这个entry及之前的所有entries都是相同的。
- Leader Completeness: 如果一个log entry在一个term中被committed,那么所有有更大terms的leaders的logs中都含有这个entry。
- State Machine Safety: 如果一个server的状态机在一个index执行了一个log entry,其他server不会在相同的index执行不同的log entry。
Raft basics
在任何时间,server有以下状态之一:leader,follower,candidate。通常,只有一个leader,其他所有servers都是followers。followers自己不发送请求,只响应leaders和candidates的请求。leader处理所有client的请求(client连接follower,那么follower重定向到leader)。candidate被用来选举新的leader。
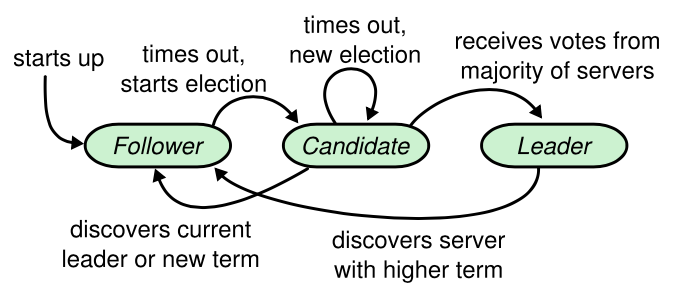
Raft将时间分为任意长度的terms,terms是连续的整数。每个term始于一次election,election期间一个或多个candidates尽力成为leader。如果一个candidate成为leader,剩下的term将它将作为leader,有些情况因为split vote,term期无法选出leader。新的term迅速开启。Raft确保一个term至多一个leader。

不同的servers可能在不同的时间观察terms的转换,有些情况,一个server可能没有看到一个election或者整个terms。(不同servers的terms可能不同)。在Raft中,terms作为一个逻辑时钟,允许servers检测过时的信息包括过期leaders。每个server存储了一个current term数字,随着时间增长。current terms在servers通信时被交换;如果server的current term小于另一个,则更新。如果candidate或者leader发现它的terms过时,则立即转为follower。如果server收到了过期term的请求,则拒绝。
Raft中servers使用RPC通信,基本的一致性算法只需要两种RPCs。RequestVote RPCs被candidate在election时调用,AppendEntries RPCs被leaders复制log entries并提供心跳机制。为了在servers之间传输快照增加第三种RPC。如果没有及时收到响应则重试,为更好的性能会并法RPCs。
Leader election
Raft使用心跳机制触发leader election。当servers启动,它们为followers状态,只要收到leader或者candidate的有效RPCs,则保持follower状态。leaders发送周期心跳给所有的followers为了维持权威。如果一个follower在election timeout内没有受到通信,它会假设没有可用leader并开启一次election选举新的leader。
为了开启一次election,一个follower增加它的current term并且转为candidate状态。然后vote自己,并发RequestVote RPCs给集群中的每个servers。candidate的状态改变条件:candidate赢得选举;其他servers赢得选举;一段时间后没有serves赢得选举。
(candidate赢得选举)一个candidate如果在一个term收到多数servers的votes,则赢得选举。一个term至多vote一票,遵循先来先服务原则。多数(过半)的原则确保一个term至多一个candidate能赢得election。一旦一个candidate赢得election,它转为leader态,发送心跳消息给所有其他serves建立去权威,防止新的elections。
(其他servers赢得选举)当等待votes时,一个candidate可能从其他leader态的server处收到一个AppendEntries RPC。如果leader的term大于等于candidate的current term,candidate承认leader的合法性,转为follower状态。反之,candidate拒绝RPC并继续维持candidate状态。
(一段时间后没有serves赢得选举)如果很多candidate同时变为candidates,votes可能分散以至于没有candidate获得多数votes。这时,每个candidate将会timeout,然后增加term,发出另一轮ReuestVote RPCs开启新的election。然而,没有额外措施split votes可能无限重复发生。
Raft使用随机election timeouts确保split votes很少发生。并能被快速解决。为了防止一开始就split votes,election timeouts是在固定区间随机选择。大多数情况下只有一个server超时,它赢得选举在其他server超时之前发送心跳。每个candidate在开始选举时重置它的随机的election timeout,超时后开启下次election,这减少了新的选举split vote的可能。
当前election算法可理解性强。
Log replication
一旦一个leader被选举,它开始处理client请求,每个请求包含可以被复制状态机执行的命令。leader将命令作为新的entry追加到log中,然后并发AppendEntries RPCs给其他每个servers复制entry。当entry被安全复制,leader状态机执行命令,返回结果给client。如果follower挂掉、运行缓慢、网络丢包,leader将一直重试AppendEntries RPCs(在返回client之后也可以一直重试)直到followers存储了所有log entries。

每个log entries存储了一个状态机名命令,leader收到entry时的term number。term在log entries中常被用来检测logs间的不一致。每个log entry有一个index确定它在logs中的位置。
leader决定状态机何时执行命令是安全的,这样的entry称为committed。Raft确保committed entries是持久化的,并最终被所有可用状态机执行。一旦leader将创建的entry复制到多数servers,这个log entry就是committed,它之前的entry都是committed,包括前任leader创建的entry。leader记录已知被committed的最大index,以后的Appendntries RPCs(包含心跳)会包含这个index。一旦一个follower知道一个log entry被committed,它的状态机会执行这个entry。
我们设计Raft log机制维护不同servers上logs的一致。简化了系统的行为,使它更可预测,更重要的是确保了安全性。Raft维护下列特性,保持了Log Matching。
- 不同的logs中的两个entries有相同的index和term,那么它们存储相同的命令。
- 不同的logs中的两个entries有相同的index和term,那么entries之前的entries都是相同的。
第一个特性源于一个leader在一个给定的term期间在一个index上最多创建一个entry,并且不会改变位置。第二个特性源于AppendEntries RPC的一个简单的一致性检查。当发送一个AppendEntries RPC时,leader会带上新entries之前的entry(prevLog)的index和term。如果follower没有发现index和term一致的entry,则拒绝新entries。一致性检查作为一个归纳步骤:初始的空logs满足Log Matching原则,日志追加时一致性检测又满足了Log Matching。因此,AppendEntries返回成功时,leader知道follower的日志和它的日志是一致的。
一般操作期间,leader的logs和followers的保持一致,因此AppendEntries不会失败。然而,leader故障可能使得logs不一致(旧的leader没有复制完所有entries)。这些不一致可能导致一系列leader和follower崩溃。
Raft中,leader通过强制followers的logs复制自己的logs处理不一致,这意味着冲突的follower logs中冲突的entries可能被leader的log中的entries覆盖。
为了follower的log和自己的一致,leader必须找到两个logs认可的最新的log entry,删除那个entry之后follower的entries,并发送leader在那个entry之后的所有entries,所有这些行动发生在响应AppendEntries RPCs的一致性检查之后。leader对每个follower维护一个nextIndex,这是leader将发送给follower的下一个log entry的index。当一个leader开始当权,它初始化所有nextIndex为它log中最新的entry的index + 1,如果一个follower的log和leader的不一致,AppendEntries一致性检查将在下次AppendEntries RPC失败。拒绝之后,leader减少nextIndex,重试AppendEntries RPC,直到nextIndex到达leader和follower匹配的点,这时AppendEntries RPC返回成功,移除了follower的log中冲突的entries,追加leader的log中没有的entries。一旦AppendEntries成功,follower的log会和leader的保持一致,这样的方式会持续到term结束。
如果需要,协议能减少AppendEntries RPCs的拒绝次数,当拒绝AppendEntries请求,follower能带上冲突的entry的term和这个term期的第一个index。通过这个信息,leader可以减少nextIndex绕过那个term期的所有冲突的entries。这样每个有冲突的term只需要一次AppendEntries RPC,而不是每个entry一次RPC。优化并非必要,一致性检查失效很少发生,大量entries不一致不太可能。
这个机制,一个leader当权后不需要采取任何特殊措施恢复log一致性。它只采取普通的措施,通过响应AppendEntries一致性检查的失败使日志自动趋于一致。leader不会覆盖或者删除自己的日志(Leader Append-Only)。
只要大多数servers是正常的,Raft就能接收,复制并应用新的entries;通常一个新的entry能在一轮RPCs被复制到集群的多数servers;一个很慢的follower不会影响性能。
Safety
目前为止,描述的机制不能确保每个状态机按照相同的顺序执行相同的命令。例如,当leader提交了几个log entries时,一个follower可能挂掉了,然后它被选为leader并且覆盖了旧的entries,最后,不同的状态机可能执行不同的命令序列。
通过加一个对于选举leader的限制完善Raft算法。限制确保在给定的term,leader包含所有的之前terms期间commit的所有entries(Leader Completeness)。有了这个限制,日志提交规则更加清晰,最终展现了对Leader Completeness的证明,和它如何引导复制状态机的正确行为。
Election restriction
在任何基于leader的一致性算法中,leader一定存储所有的被提交的log entries。在一些一致性算法中,例如Viewstamped Replication,一个leader能被选举尽管它没有包含所有提交的日志,这些算法都有额外的机制确保丢失的entries被传给新的leader,不论是在选举中完成还是在选举后立即完成。不幸的是,这增加了复杂性。Raft使用更简单的方法确保在新的leader当选之时,所有之前terms期间被提交的entries都会出现,不需要给leader传送这些entries。这意味着log entries只能从leaders流向followers,leaders不会覆盖自己logs上存在的entries。
Raft使用投票方式阻止没有包含所有committed entries的candidate赢得选举。一个candidate为了赢得选举必须和多数servers通信,这意味着每条已经提交的entry至少在一个servers中存在。如果candidate的日志至少和多数其他servers一样新,那么它一定包含有全部的committed entries。RequestVote RPC实现了这个限制:RPC含有candidate的日志的信息,如果投票者的log比candidate的新,则拒绝。
Raft决定通过longs中的最新的log entries的index和term比较两个logs谁更新。如果logs最新的log entries有不同的term,term大的最新;如果logs最新的term相同,则长的logs最新。
Committing entries from previous terms
只要一个entry被存储在多数servers,leader就知道当前term的entry被committed(日志被提交的定义)。如果一个leader在提交日志前挂了,未来leader将尽力完成entry复制。leader也不能立即断定之前term的被存储在多数servers上的entry是否被提交(只能判断当前term不能判断之前term)。一个旧的被存储在多数servers上的log entry可能被未来的leader覆盖。
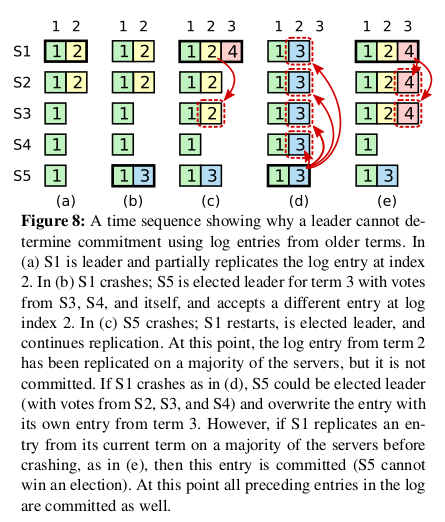
为了消除这样的问题,Raft不会通过计算复制数提交之前terms的log entries。只有leader当前term的log entries才能通过计算复制数进行提交。一旦当前的一条entry被提交,由于Log Matching Property,之前的entries可以认为提交了。有一些leader可以安全判断entry是否提交的方法,如是否存储在所有servers上,但Raft采用了更保守的方法。
leader复制之前term的entries时,entries保留了term number,所以Raft增加了提交规则的复杂性。其他一致性算法,如果一个新的leader复制之前terms的entries,它一定用新的term number。Raft简单的原因是log entries之前维护了相同的term number。而且Raft中新的leader发送更少的之前terms的log entries(其他算法发送冗余entries为了提交之前重排)。