什么是FastDFS
很多以文件为载体的在线服务,如相册网站、视频网站等,都需要对文件进行管理,包括文件的存储、同步、访问(文件上传、文件下载)等,同时肯定会伴随着大容量存储和负载均衡的问题。
在日常的一些项目中,比如做用户的KYC认证等,也需要存储文件、图片、视频等。此时可以选择使用OSS云服务,也可以自己构建相对专业的文件管理系统。
FastDFS是一个开源的轻量级分布式文件系统,用于解决大数据量存储和负载均衡等问题,并需要通过专有API进行访问。满足大容量文件存储问题,并保证高性能和高扩展性。它能够很好的解决上述提到的业务场景。
FastDFS的特性
FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。
优点:
- 文件不分块存储,文件和系统中的文件一一对应。
- 对文件内容做hash处理,避免出现重复文件,节约磁盘空间。
- 下载文件支持HTTP协议,可基于内置Web Server或外部Web Server。
- 支持在线扩容,动态添加卷。
- 支持文件冗余备份和负载均衡。
- 存储服务器上可以保存文件属性(meta-data)V2.0 网络通信采用libevent,支持大并发访问,整体性能更好。
缺点:
- 直接按文件存储,可直接查看文件内容,缺乏文件安全性。
- 数据同步无校验,存在静默IO问题,降低系统可用性。
- 单线程数据同步,仅适合存储小文件(4KB到500MB之间)。
- 备份数根据存储分卷(分组)决定,缺乏文件备份数设置灵活性。
- 单个挂载点异常会导致整个存储节点下线。
- 缺乏多机房容灾支持。
- 静态的负载均衡机制。
优点与缺点并存,但针对中小型系统已经完全足够使用了。
FastDFS的角色
初次接触或部署FastDFS的朋友往往会有些疑惑,为什么要部署那么多服务才能使用FastDFS。这是由FastDFS的角色构成决定的。
FastDFS系统有三个角色:跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)。
如果通过Http访问,通常情况下,还需要部署Nginx服务。
Tracker Server:跟踪服务器,主要做调度工作,起到均衡的作用;负责管理所有的storage server和group,每个storage在启动后会连接 Tracker,同步自己所属group等信息,并保持周期性心跳。它是客户端和数据服务器交互的枢纽。
Storage Server:存储服务器,主要提供容量和备份服务;以group为单位,每个group内可以有多台storage server,数据互为备份。文件及属性(Meta Data)都保存在该服务器上。
Client:客户端,上传下载数据请求的发起方,通过专有接口,使用TCP/IP协议与跟踪器服务器或存储节点进行数据交互。
下面通过一张图来看看FastDFS的不同角色在整个流转过程中的作用。
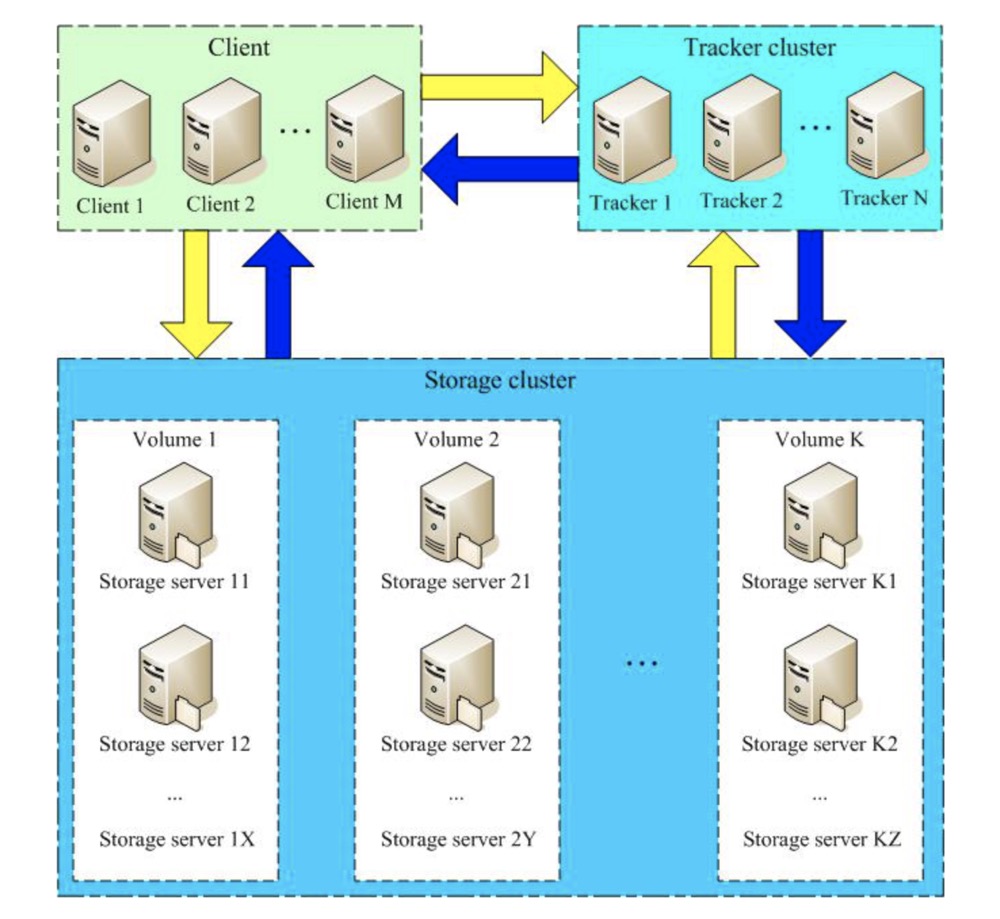
上图中Tracker相当于一个调度中心,上传和下载都通过它来进行分配指定。
上面我们提到Nginx,客户端通常会使用Ngnix等静态服务器来调用或者做一部分的缓存。后面搭建环境时便是基于Nginx。
Storage cluster部分,由Volume1、Volume2……VolumeK组成,它们称为卷(或者叫做组),卷与卷之间是平行的关系,可以根据资源的使用情况随时增加,卷内服务器文件相互同步备份,以达到容灾的目的。
上传过程
当服务启动之后,Storage Server会定期的向Tracker Server发送存储信息。如果Tracker Server是集群形式,则每个Tracker之间的关系是对等的,客户端上传时选择任意一个Tracker即可。
整体流程:当客户端请求Tracker进行上传操作时,会获取存储服务器相关信息,主要包括IP和端口。根据返回信息上传文件,通过存储服务器写入磁盘,并返回给客户端file_id、路径信息、文件名等信息。
对应流程图如下:
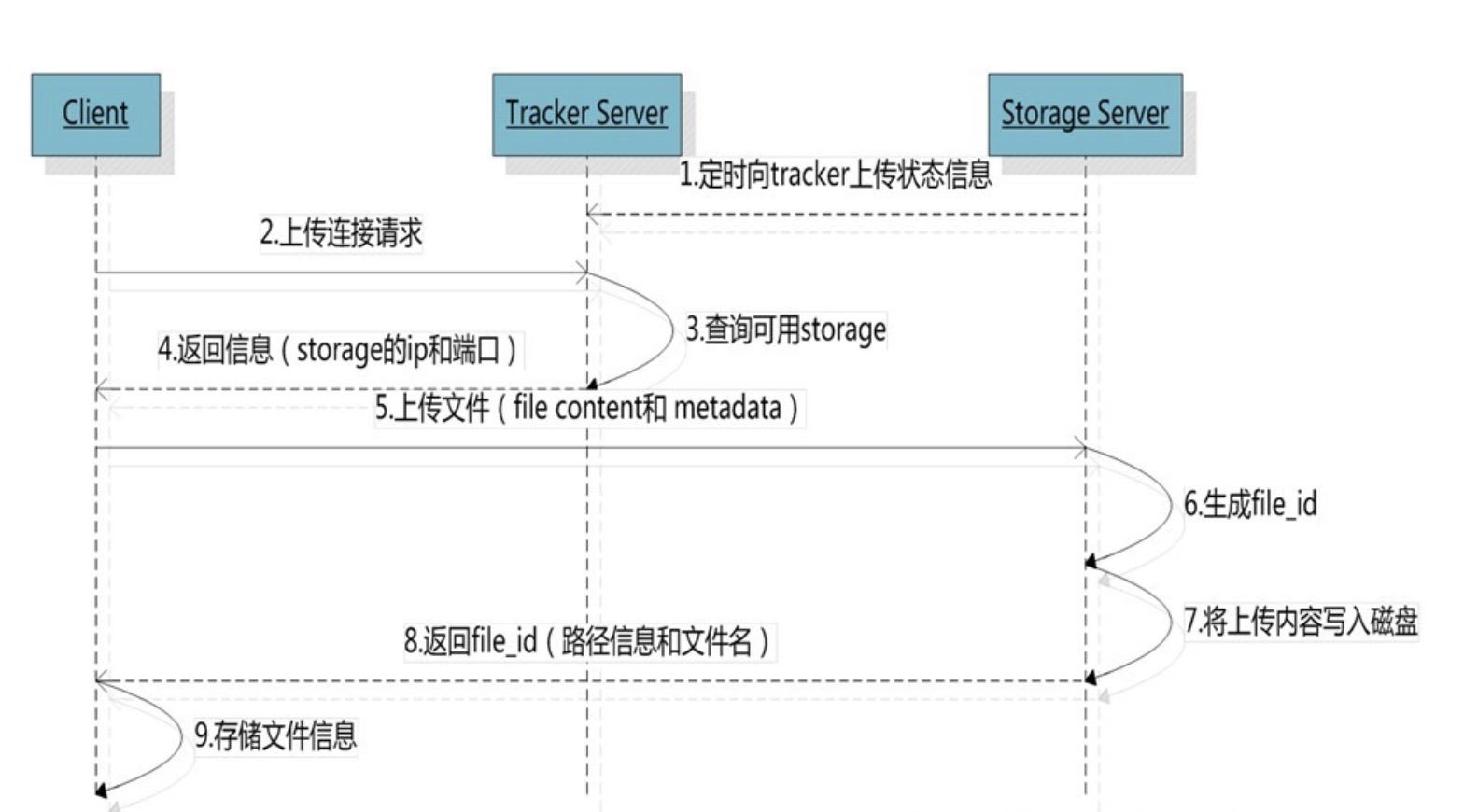
其中,当Tracker收到客户端上传文件的请求时,会为该文件分配一个可以存储文件的group,当选定了group后就要决定给客户端分配group中的哪一个storage server。
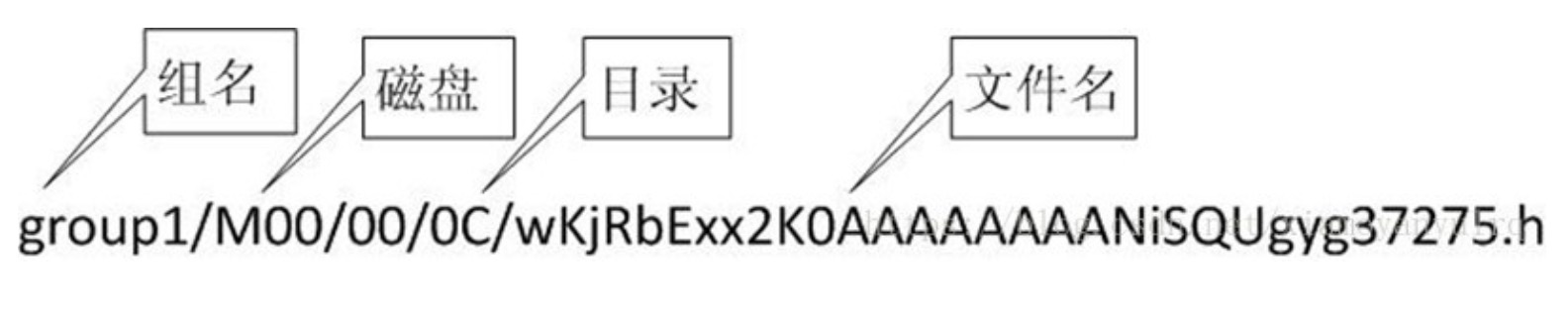
当分配好storage server后,客户端向storage发送写文件请求,storage将会为文件分配一个数据存储目录。然后为文件分配一个fileid,最后根据以上的信息生成文件名存储文件。
生成的文件名基本格式如下:
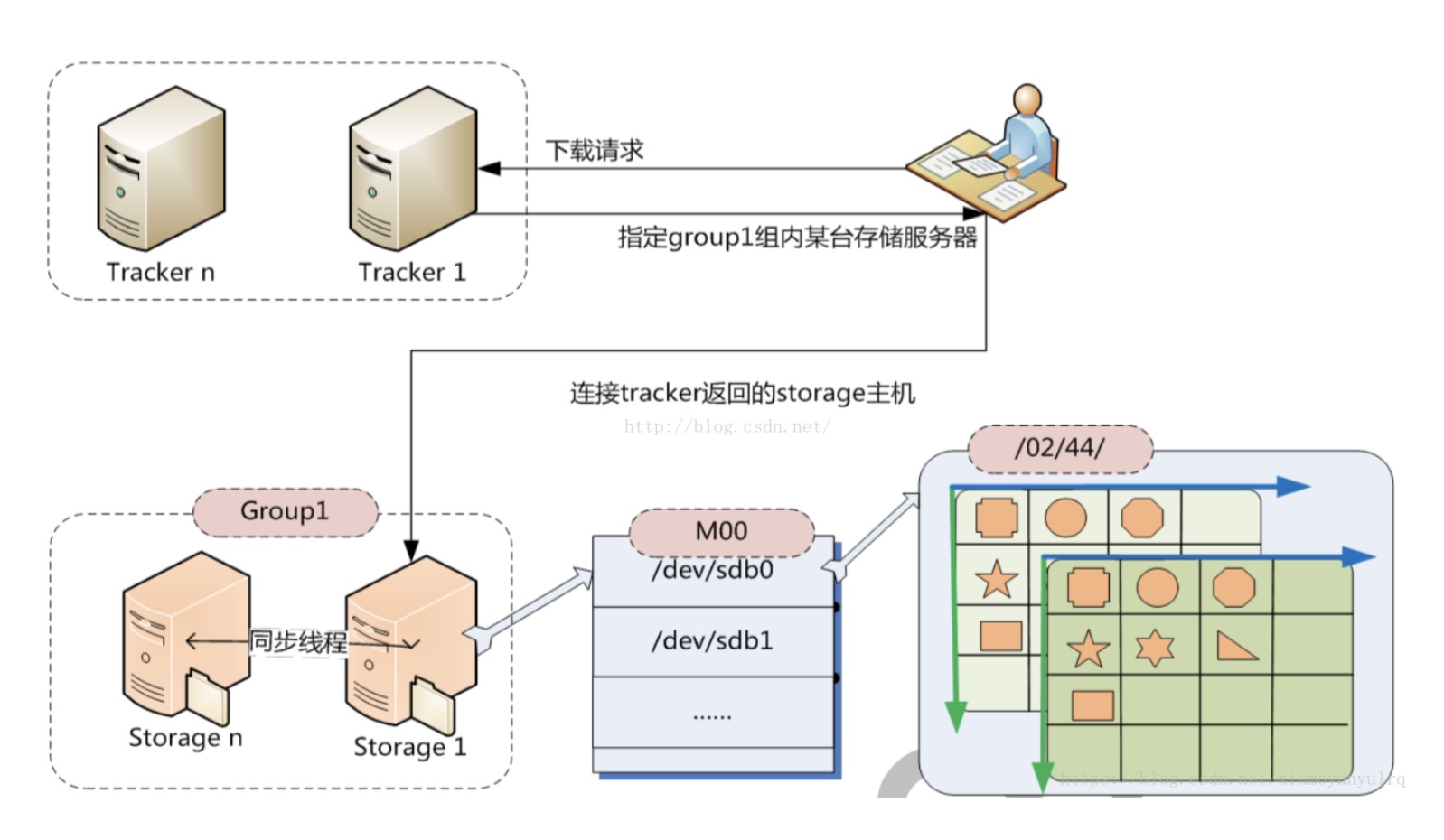
下载过程
跟上传一样,在下载时客户端可以选择任意Tracker server。
客户端带文件名信息请求Tracker,Tracker从文件名中解析出文件的group、大小、创建时间等信息,然后选择一个storage用来服务处理请求,返回对应文件。
对应流程图如下:
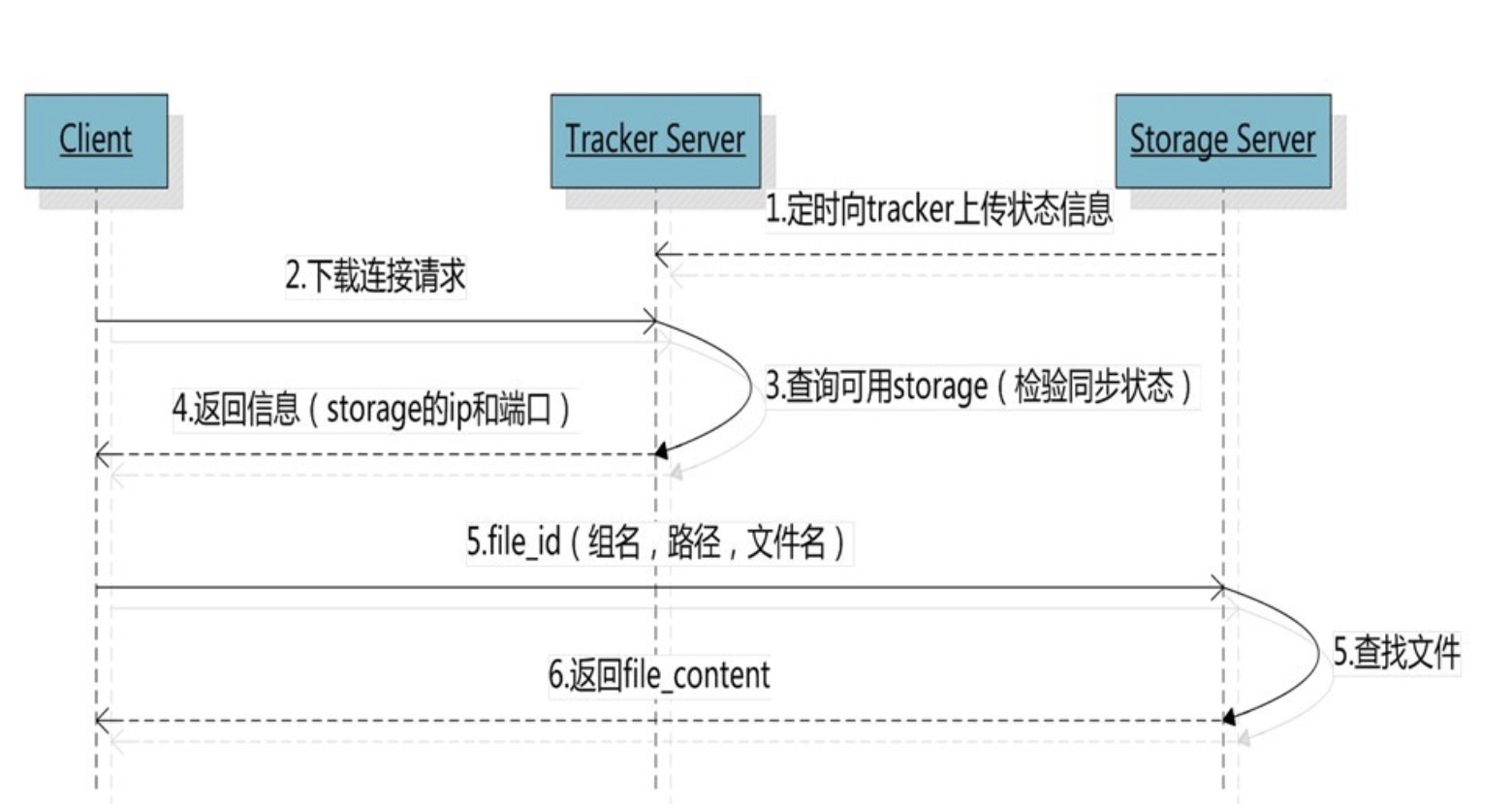
如果是基于Web的http请求,此处的Client可以是Nginx代理服务。下面这张图更加形象的描述了相关的流程。
小结
关于FastDFS的基本特性和原理已经介绍完毕,重点关注三个角色和两个流程,以及将三个角色融入到两个流程中进行分析。明白了这个大的方向之后,至于执行的细节部分就可以逐步了解和掌握。
下一篇文章我们将来介绍基于Docker如何部署FastDFS。关注微信公众号【程序新视界】获得持续更新内容。
