selenium 是Web应用测试工具,可以利用selenium和python,以及chromedriver等工具实现一些动态加密网站的抓取。本文利用这些工具抓取淘宝内衣评价买家秀图片。
准备工作
下面先安装selenium,在命令行输入python,然后输入安装命令
1
|
pip install selenium
|
安装chromedriver和chrome,二者版本需要对应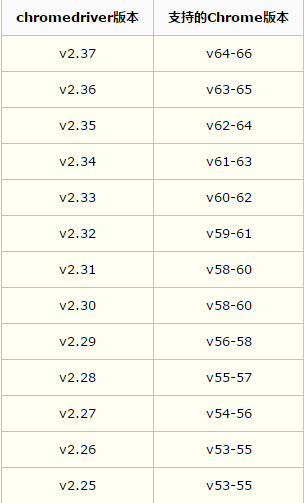
各版本下载地址
下载完成后解压,将exe放到你的python安装目录下的scripts目录下即可。
接下来分析网站,并且模拟登陆爬取数据,登陆淘宝,F12检测浏览器请求,F5刷新下,在network栏找到可以分析的几个网络请求,找到cookie
分析和编码
先根据cookie登陆淘宝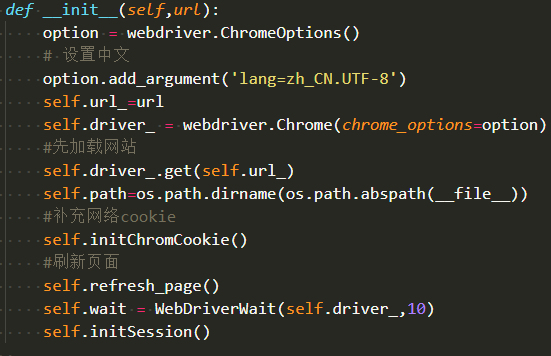
这段代码初始化了ChromeDriver的参数,然后根据cookie设置chrome选项,成功后刷新下页面,并且初始化reuests session,用于维持会话
初始化cookie代码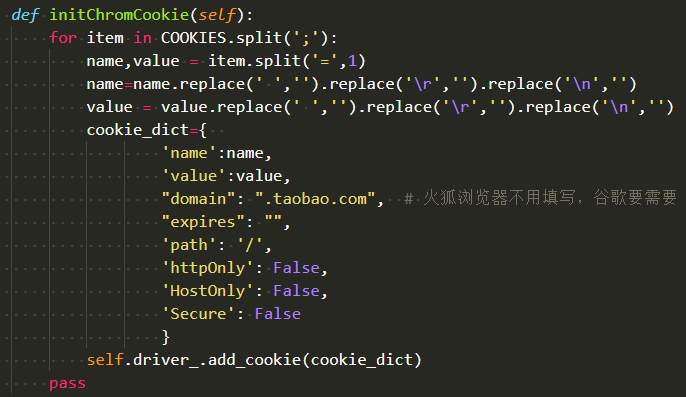
初始化session代码
这样利用cookie就能成功登陆淘宝了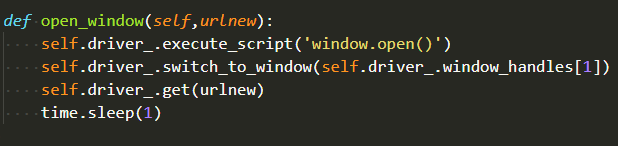
利用chromedriver打开了一个新窗口,然后访问指定的商品页面,接下来要做的都是点击累计评价,然后点击图片评价选择框。
累计评价的标签元素xpath在network中找到,可以通过find_element_by_xpath函数访问该标签,然后调用click函数就完成了点击,当然也可以通过presence_of_element_located超时等待查询,查不到指定标签就返回超时异常。相关接口调用比较简单,可以看看selenium基础查询和操作
python selenium api
代码功能是先点击评论,然后滚动1000像素位置,抓取找到评论区元素,根据评论区的图片元素找到资源地址,同时代码实现了自动点击下一页和判断末页功能。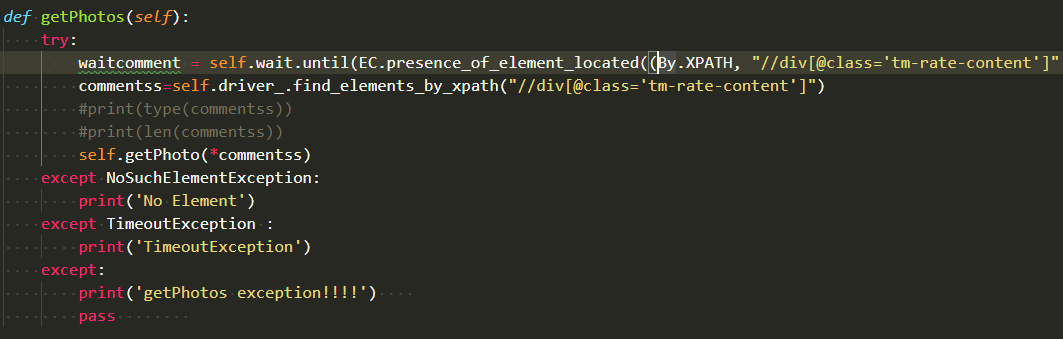
代码找到了评论列表,然后将评论列表传给getPhoto函数,抓取每个评论图片,下面是抓取图片的核心代码。
def getPhoto(self,*comentlist): try: for comments in comentlist: #print(len(comentlist)) #print(type(comments)) desc=comments.find_element_by_class_name('tm-rate-fulltxt').text if len(desc) == 0: desc='abcdef' dirfix=desc[0:6] dirname=os.path.join(self.path,dirfix) if os.path.exists(dirname) == False: os.makedirs(dirname) txtname=os.path.join(dirname,desc[0:6]+'.txt') if os.path.exists(txtname) == False: with open (txtname,'w',encoding='utf-8') as file: file.write(desc) photos=comments.find_element_by_class_name('tm-m-photos') photos=photos.find_element_by_class_name('tm-m-photos-thumb') photos=photos.find_elements_by_tag_name('li') for ph in photos: phaddr=ph.get_attribute('data-src') print(phaddr) bigph=phaddr.split('_4')[0] print(bigph) imgname= os.path.join(dirname ,bigph.split('/')[-1]) if os.path.exists(imgname) : continue img=self.session_.get('http:'+bigph,headers=self.headers_,cookies=self.cookiejar_).content print('正在爬取%s' %(bigph)) with open (imgname,'wb') as imgfile: imgfile.write(img) print('爬取成功%s' %(bigph)) time.sleep(2) except NoSuchElementException: print('No Element') except TimeoutException : print('TimeoutException') except: print('getPhoto exception') pass
效果展示



源码下载地址
https://github.com/secondtonone1/python-
我的公众号