都兼容 MySQL
-
查看表结构:DESC ${table_name}
-
查看建表语句:SHOW CREATE TABLE ${table_name}
-
表增加列:ALTER TABLE ${table_name} ADD COLUMN ${copumn_name} ${COLUMN_TYPE} NOT NULL;
-
表修改列:ALTER TABLE ${table_name} CHANGE COLUMN ${column_old_name} ${column_new_name} ${COLUMN_TYPE} NOT NULL;
-
删除列:ALTER TABLE ${table_name} DROP COLUMN ${column_name}
-
主键要能唯一标识一条记录
-
创建列值唯一约束:ALTER TABLE ${table_name} ADD CONSTRAINT ${unique_constraint_name} UNIQUE (${column_name});
-
外键会一定程度降低性能
-
创建外键:ALTER TABLE ${table_nane} ADD CONSTRAINT ${foreign_key_name} FOREIGN KEY (${column_name}) REFERENCES ${other_table} (${other_table_column});
-
删除外键:ALTER TABLE ${table_name} DROP FOREIGN KEY ${foreign_key_name};
-
索引对列值预排序所以加快查减慢增删改
-
创建普通索引:ALTER TABLE ${table_name} ADD INDEX ${index_name} (${column_name1}, ${column_name2});
-
创建唯一索引(索引列值有唯一性):ALTER TABLE ${table_name} ADD UNIQUE INDEX ${unique_index_name} (${column_name});
-
SELECT 语句:SELECT ${TRANSACTION_FUNCTION} ${transaction_result_alias}, ${column_name1} ${column_alias}, ${column_name2} FROM ${table_name} WHERE ${</=/>/<>/<=/>=/ LIKE/()/NOT/AND/OR_column} ORDER BY ${column_name3} DESC ${column_name4} ASC LIMIT ${result_count} OFFSET ${start_number} GROUP BY ${column_name}; LIKE 语句中 % 匹配任意数量的字符
-
SELECT 聚合函数:COUNT(*),返回的总行数,COUNT(${column_name}),返回了指定列的行数(与前面的等价),SUM(${column_name},计算该数值列的和,AVG(${column_name}),计算该数值列的平均值,MAX (${column_name}),计算某一列的最大值,字符类返回排序最后的,MIN(${column_name}),计算某一列的最小值,字符类返回排序最前的,当未返回数据时,COUNT 返回 0,其他的返回 NULL
-
分组查询:执行过程是先把 GROUP BY 指定的列值相同的合并为一组,生成一个中间表,再进行其他操作,分组有多少组返回结果就是多少行,按 GROUP BY 合并的行中不能进行其值合并的列其值将为 NULL(部分数据库会报错,如 MySQL),GROUP BY 后可以使用逗号分隔指定多个列进行分组查询,执行过程是先按 GROUP BY 指定的第一列合并,生成一个中间表,再对中间表的 GRUOP BY 指定的第二列进行合并,再生成一个中间表,依次类推,理解困难看下图
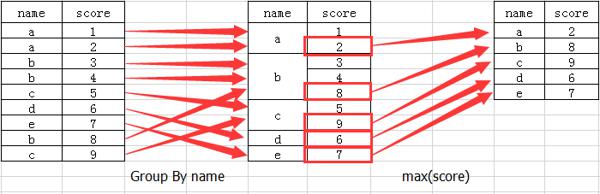
-
多表查询(笛卡尔乘积):SELECT ${table_name1}.${column_name1} ${alias1}, ${table_name2}.${column_name2} ${alias2} FROM ${table_name1}, ${table_name2}; 多表查询时返回的列名只会有个表的列名而不含表名,如果两个表中有命名冲突则需要取别名
-
给表设置别名:SELECT ${alias1}.${column_name1} ${alias3}, ${alias2}.${column_name2} ${alias4}, ${column_name3} FROM ${table_name1} ${alias1}, ${table_name2} ${alias2};
-
连接查询:SELECT ${column_name} FROM ${table_name1} ${INNER/RIGHT OUTER/LEFT OUTER/FULL OUTER} JOIN ${table_name2} ON ${table_name1}.${column_name1} ${</=/>/<>/<=/>=} ${table_name2}.${column_name2}; JOIN 左边的表为左表,右边的为右表,连接查询是先对左右表做笛卡尔乘积,再按照 ON 语句进行过滤,INNER JOIN 直接返回过滤后的结果集,RIGHT OUTER JOIN 在结果集中再添加右表中 ON 条件完全未匹配到的行至结果集中,LEFT OUTER JOIN 则是添加左表中的完全未匹配到的行,FULL OUTER JOIN 是两个表中完全未匹配到的行都添加进结果集中,其中,另一个表中不存在的数据值为 NULL
-
INSERT 语句:INSERT INTO ${table_name} (${column_name1}, ${column_name2}) VALUES (${value1}, ${value2}), (${value3}, ${value4});
-
UPDATE 语句:UPDATE ${table_name} SET ${column_name1} = ${value1}, ${column_name2} = ${value2} WHERE ${</=/>/<>/<=/>=/ LIKE/()/NOT/AND/OR_column}; UPDATE 语句中,更新的值可以使用表达式,如 ...SET score = score + 10...
-
DELETE 语句:DELETE FROM ${table_name} WHERE ${</=/>/<>/<=/>=/ LIKE/()/NOT/AND/OR_column};
-
插入或替换:将 INSERT 替换为 REPLACE 其他语法不变,主键值不存在时插入数据,主键值存在的时候删除旧数据再插入新数据
-
插入或更新:在 INSERT 语句后加入 DUPLICATE KEY UPDATE ${column_name1} = ${value1}, ${column_name2} j= ${value2}; 如果主键值不存在,将插入数据,否则将更新数据
表的快照:CREATE TABLE ${new_table_name} SELECT * FROM ${old_table_name}; 也可以指定 WHERE 子句只备份特定数据 -
INSERT 使用 SELECT 返回值:INSERT INTO ${table_name1} (${column_name1}, ${column_name2}) SELECT ${column_name3}, ${column_name4} FROM ${table_name2} WHERE {</=/>/<>/<=/>=/ LIKE/()/NOT/AND/OR_column}; 这要求 SELECT 返回的列及其类型与 INSERT 的对应
-
事物:SQL 脚本中开启一个事物用 BEGIN; 结束一个事务用 COMMIT; 回滚用 ROLLBACK; 设置隔离级别用 SET TRANSACTION ISOLATION LEVEL ${ISOLATION_LEVEL};
-
Read Uncommitted:隔离级别最低,一个事务可能会读到另一个事务更新但未提交的数据,如果此时回滚将发生脏读
-
Read Committed:一个事务读取另一个事务正在更新的数据,导致同一次事物中两次取出的数据不一致,即不可重复读
-
Repeatable Read,:一个事务读取另一个事务正在插入的数据,插入前无法读取到,插入事务提交后仍无法读取到,但是更新时数据又会出现,即幻读,InnoDB 引擎的默认隔离级别
-
Serializable:最严格的隔离级别,以上三种问题都不会出现,以性能作为代价,默认的隔离级别
-
选择不重复的列值:SELECT DISTINCT ${COLUMNS_NAME} FROM ${TABLE_NAME};
-
选择区间内的列值:SELECT ${COLUMNS_NAME} FROM ${TABLE_NAME} WHERE ${COLUMN_NAME} BWTWEEN ${VALUE1} AND ${VALUE2};
-
按多列分别进行结果排序:SELECT * FROM ${TABLE_NAME} ORDER BY ${COLUMN1_NAME}, ${COLUMN2_NAME} DESC, ${COLUMN3_NAME};
-
HAVING 的存在是为了过滤 GROUP BY 后的分组,即 WHERE 进行行过滤 HAVING 进行分组过滤,因为 GROUP BY 不能与 WHERE 连用:SELECT AVG(${COLUMN3_NAME}) ${COLUMEN1_ALIAS}, ${CLOUMN2_NAME} ${COLUMN2_ALIAS} FROM ${TABLE_NAME} WHERE ${COLUMN2_NAME} LIKE '${LIKE_STATEMENT}%' GROUP BY (${COLUMN2_NAME}) HAVING COUNT(${COLUMN1_NAME}) >= ${VALUE};
-
SQL 中执行的顺序为 from - join - on - where - group by(开始使用别名) - 聚集函数 - having - select - distinct - order by - limit ,这个是一个很好的执行顺序的例子,SELECT CLASS FROM STUDENT WHERE SSEX = '男' GROUP BY CLASS HAVING COUNT(SSEX) >= 2; 先执行 FROM 选择所有数据后再 WHERE 进行行过滤,再 GROUP BY 分组最后 HAVING 用来做分组的条件
-
多表连接查询时连接条件使用 ON 而非 WHERE,区别在于 LEFT OUTER JOIN 时会在 ON 匹配完成之后再添加左表的未匹配行,而 WHERE 会在添加了左表的未匹配行之后再进行 WHERE 过滤,在 INNER JOIN 时则可互换,这与 SQL 的执行顺序有关
-
多表连接查询的:SELECT ${TABLE1_ALIAS}.${COLUMN1_NAME}, ${TABLE2_ALIAS}.${COLUMN1_NAME}, ${TABLE3_ALIAS}.${COLUMN1_NAME} FROM ${TABLE1_NAME} ${TABLE1_ALIAS} INNER JOIN ${TABLE2_NAME} ${TABLE2_ALIAS} INNER JOIN ${TABLE3_NAME} ${TABLE3_ALIAS} ON ${TABLE1_ALIAS}.${COLUMN2_NAME} = ${TABLE3_ALIAS}.${COLUMN2_NAME} AND ${TABLE2_ALIAS}.${COLUMN2_NAME} = ${TABLE3_ALIAS}.${COLUMN3_NAME};
-
SQL 中表自身也可与自身进行连接,用于按自身条件进行过滤:SELECT A.* FROM ${TABLE_NAME} A INNER JOIN ${TABLE_NAME} B ON A.${COLUMN1_NAME} = ${VALUE1} AND B.${COLUMN1_NAME} = ${VALUE1} AND B.${COLUMN2_NAME} = ${VALUE3} AND A.${COLUMN3_NAME} > B.${COLUMN3_NAME};
-
SQL 支持直接用 YEAR() 函数取 DATATIME 之类的年值:SELECT ${COLUMN_NAME} FROM ${TABLE_NAME} WHERE YEAR(${DATATIME_COLUMN} = '1997';
-
使用 UNION 联合列出结果并取列别名以及排序:SELECT ${TABLE1_COLUMN1_NAME} AS ${ALIAS1_NAME}, ${TABLE1_COLUMN2_NAME} AS ${ALIAS1_NAME} FROM ${TABLE1_NAME} UNION SELECT ${TABLE2_COLUMN1_NAME} AS ${ALIAS1_NAME}, ${TABLE2_COLUMN2_NAME} AS ${ALIAS2_NAME} FROM ${TABLE2_NAME} ORDER BY ${ALIAS1_NAME}, ${ALIAS2_NAME};
-
SQL SELECT 中可以直接使用函数和运算符,如 SELECT (YEAR(NOW()) - YEAR(${DATETIME_COLUMN_NAME})) FROM ${TABLE_NAME};
-
合并两个 SELECT 出来的列:SELECT (${SELECT_STATEMENT1}) AS ${ALIAS1}, ${${SELECT_STATEMENT2}} AS ${ALIAS2};