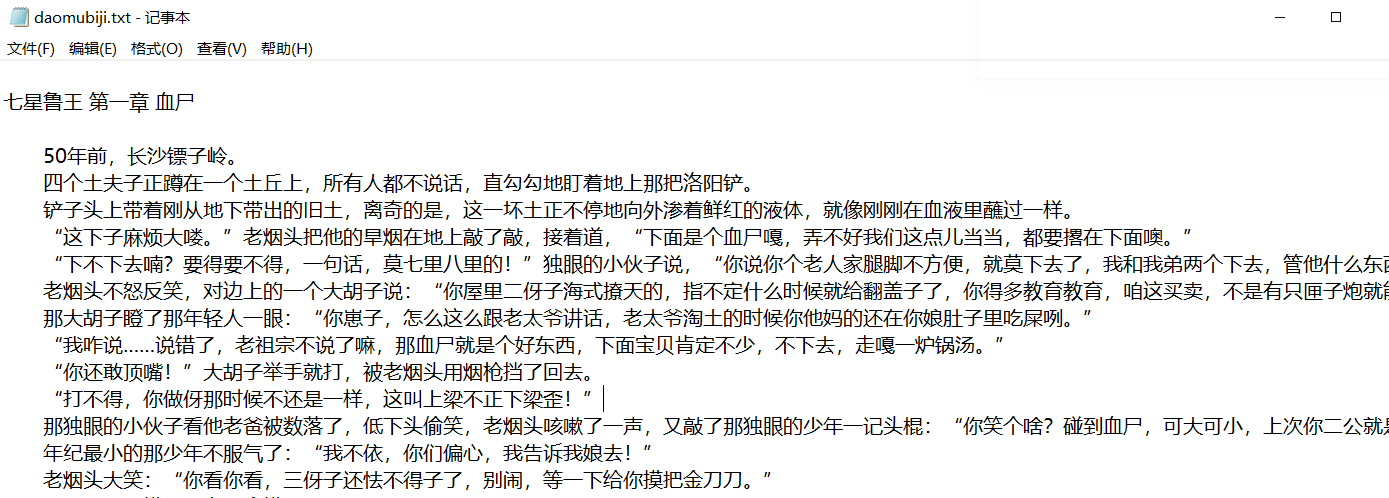
一、前言
《盗墓笔记》是一本经典的盗墓题材小说,故事情节引人入胜。本文将使用python2.7通过小说网站http://www.daomubiji.com/来爬取整本盗墓笔记并保存,在这一过程中演示了使用python网络库requests实现简单的python爬虫以及使用html文档分析库BeautifulSoup分析网页。
二、准备
在进行下一步之前先要安装两个库:requests以及BeautifulSoup。
pip install requests
pip install beautifulsoup4
# BeautifulSoup的解析器
pip install lxml
pip install html5lib
我们通常都是使用浏览器来访问网页,浏览器发送请求给服务器,服务器根据请求将请求的数据返回给浏览器,浏览器再将这些数据显示出来。而使用爬虫则不再使用浏览器发送请求,而是使用程序发送,并且使用爬虫程序接受服务器返回的数据,requests就是一个能帮助我们发送请求给服务器并得到返回数据的库。得到返回数据后(如HTML),可以使用另一个库BeautifulSoup来对HTML进行解析,提取出我们想要的标签的内容。
requests文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
BeautifulSoup文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
三、网页分析
爬虫的基本思想是从网页中找到我们感兴趣的标签或链接,然后使用相关工具(如request和BeautifulSoup)来得到网页和标签的内容。下面对该网站的网页进行分析。
首先打开网站的主页http://www.daomubiji.com/来分析一下网页。我们知道盗墓笔记有很多部,打开后可以看到主页上列出了每一部的入口。
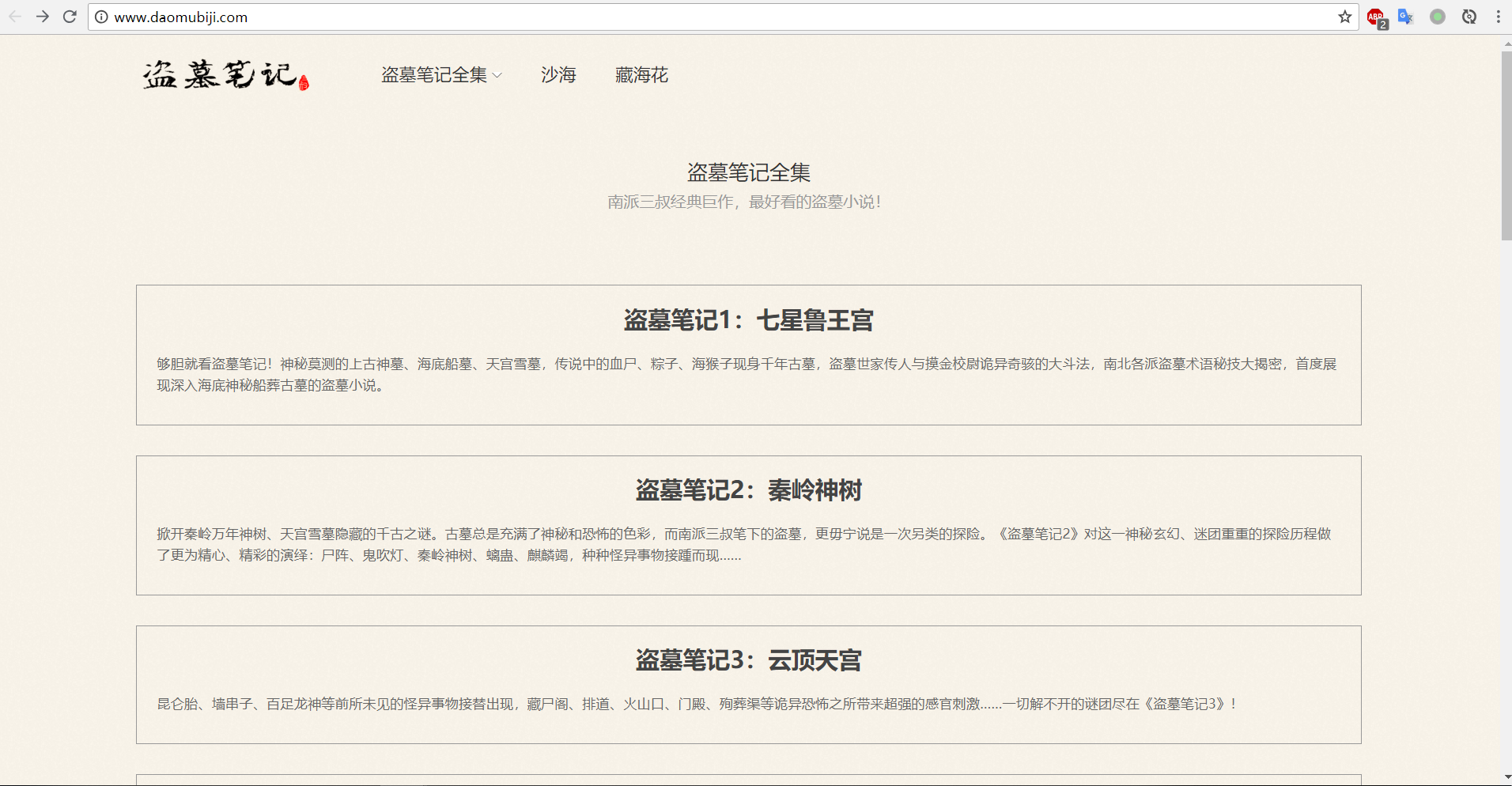
点进去其中的一部:《盗墓笔记1:七星鲁王宫》,我们可以看到该页显示了《盗墓笔记1》的每个章节。

再点进某一章节,就可以看到这一章的内容了。

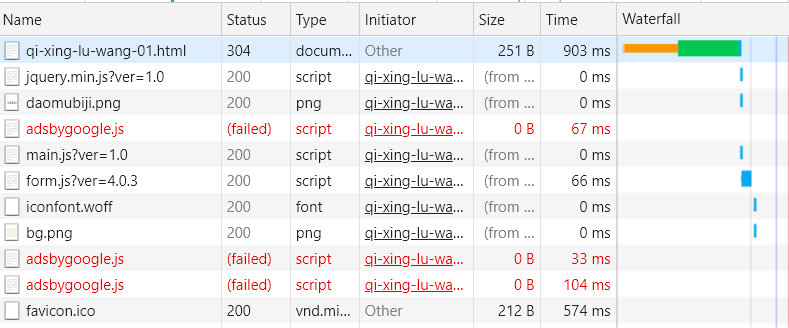
在来分析一下各章的链接,在《盗墓笔记1:七星鲁王宫》中,第一章的链接为http://www.daomubiji.com/qi-xing-lu-wang-01.html,第二章的链接为http://www.daomubiji.com/qi-xing-lu-wang-02.html,以此类推。在浏览器按下F12,选择NetWork后刷新网页,我们可以看到网页请求的文件:
点击第一行,可以看到:
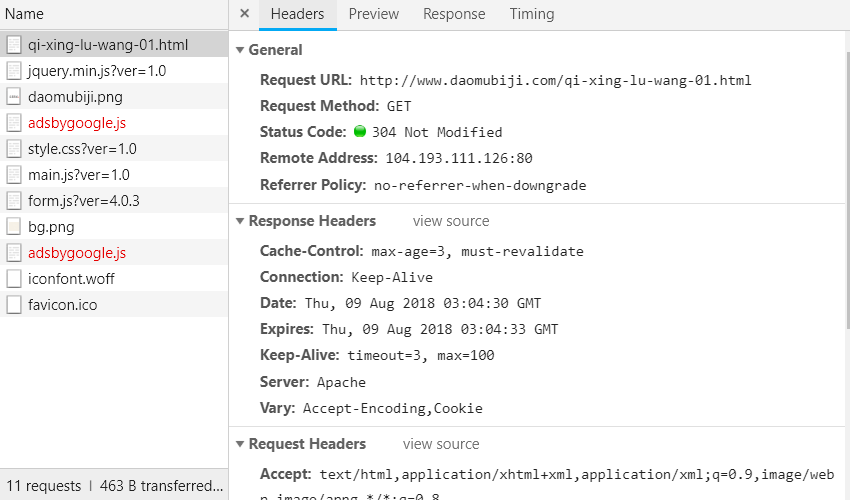
由Headers的内容可以看出该请求为一个简单的GET请求,没有任何参数,翻页是通过链接中的最后一个数字来实现的,比如01代表第一页、02代表第二页,所以只要我们得到所有章节的链接,然后从各章节对应的HTML文档中使用BeautifulSoup提取文章内容即可。总的步骤如下:
- 通过主页获取每本盗墓笔记的链接;
- 通过每本的链接获取每章的链接;
- 通过每章的链接获取每章标题与内容;
- 汇总每章的内容,保存进文件。
以下为各步骤的实现。
四、通过主页获取每本盗墓笔记的链接
打开主页http://www.daomubiji.com/并按下F12,点击左上角的鼠标(或者ctrl+shift+c)来选择元素,然后选择标题《盗墓笔记1:七星鲁王宫》,可以看到下图:
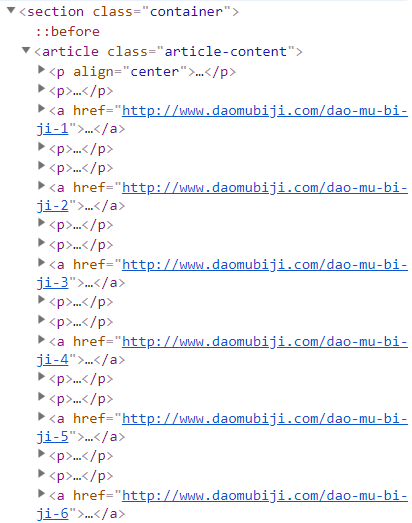
我们发现,每部书的链接都在一个名为article的标签下,由标签a中的href属性指定,所以我们可以使用BeautifulSoup提取出标签a的href属性。我们发现主页还包含两部其他小说:《沙海》和《藏海花》的链接:
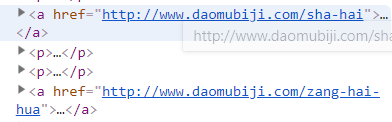
而我们只想获得小说《盗墓笔记》,解决方法是使用BeautifulSoup来将这两个链接排除在外,该小节的代码如下:
from bs4 import BeautifulSoup
import requests
import re
def get_book_urls(url):
book_urls = []
#获取主页
index = requests.get(url)
soup = BeautifulSoup(index.content.decode("utf8"), 'lxml')
#从主页中找到所有的article标签
articles = soup.find_all("article", class_='article-content')
for article in articles:
#找到各本盗墓笔记的链接,并排除沙海和藏海花的链接
links = article.find_all('a', href=re.compile("dao-mu-bi-ji"))
for link in links:
book_urls.append(link["href"])
return book_urls
book_urls = get_book_urls("http://www.daomubiji.com")
print book_urls
输出:

这样我们就得到了每本的链接。
五、通过每本的链接获取每章的链接
点进第一本《七星鲁王宫》http://www.daomubiji.com/dao-mu-bi-ji-1后按F12并选择元素,选择每章的标题:
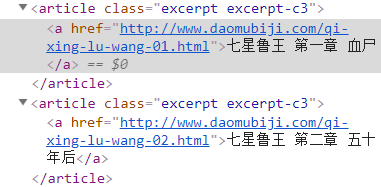
可以看到,每章的链接在article标签(该标签的class为"excerpt excerpt-c3")下,由标签a的href属性指定,使用以下代码获取各章的链接:
def get_chapter_urls(url):
chapter_urls = []
#获取每本书对应的页面
page = requests.get(url)
soup = BeautifulSoup(page.content.decode("utf8"), "lxml")
#找到所有类为excerpt excerpt-c3的article标签
articles = soup.find_all("article", class_="excerpt excerpt-c3")
#提取article标签下a标签的href属性
for article in articles:
chapter_urls.append(article.a["href"])
return chapter_urls
chapter_urls = get_chapter_urls("http://www.daomubiji.com/dao-mu-bi-ji-1")
print chapter_urls
输出(一部分):

六、通过每章的链接获取每章标题与内容
和前面一样,通过对文章内容进行“选择元素”,可以发现标题的标签如下:

内容的标签如下:

使用BeautifulSoup提取标签内容:
def get_content(url):
content = ""
page = requests.get(url)
soup = BeautifulSoup(page.content.decode("utf8"), "lxml")
#提取标题
title = soup.find_all("h1", class_="article-title")[0].string
content += ("
"+title+"
")
#找到包含文章内容的article标签
articles = soup.find_all("article", class_="article-content")
for article in articles:
ps = article.find_all('p') #找到包含文章每一段的标签p
for p in ps:
#print p.string
for string in p.strings:
content = content + unicode(string) + "
" #获取标签p中的所有内容
return content
content = get_content("http://www.daomubiji.com/qi-xing-lu-wang-01.html")
print content
输出(一部分):

这样我们对每一章的链接都执行以上操作就可以获得每一章的内容,再把每一章的内容汇总保存即可。
七、完整代码
完整代码如下:
from bs4 import BeautifulSoup
import requests
import re
# 获取每本书的链接
def get_book_urls(url):
book_urls = []
index = requests.get("http://www.daomubiji.com/")
soup = BeautifulSoup(index.content.decode("utf8"), 'lxml')
articles = soup.find_all("article", class_='article-content')
for article in articles:
links = article.find_all('a', href=re.compile("dao-mu-bi-ji"))
for link in links:
book_urls.append(link["href"])
return book_urls
# 获取每章的链接
def get_chapter_urls(url):
chapter_urls = []
page = requests.get(url)
soup = BeautifulSoup(page.content.decode("utf8"), "lxml")
articles = soup.find_all("article", class_="excerpt excerpt-c3")
for article in articles:
chapter_urls.append(article.a["href"])
return chapter_urls
# 获取每章的内容
def get_content(url):
content = ""
page = requests.get(url)
soup = BeautifulSoup(page.content.decode("utf8"), "lxml")
title = soup.find_all("h1", class_="article-title")[0].string
content += ("
"+title+"
")
articles = soup.find_all("article", class_="article-content")
for article in articles:
ps = article.find_all('p')
for p in ps:
for string in p.strings:
content = content + unicode(string) + "
"
return content
# 获取全本《盗墓笔记》并保存到文件
def get_article(url):
book_urls = get_book_urls(url)
chapter_urls = []
for url in book_urls:
#url = "http://www.daomubiji.com/dao-mu-bi-ji-2"
chapter_urls.extend(get_chapter_urls(url))
print chapter_urls
result = ""
for chapter_url in chapter_urls:
content = get_content(chapter_url)
result += content
print content
with open("I:daomubijidaomubiji.txt", "a") as f:
f.write(result.encode("utf8"))
get_article("http://www.daomubiji.com/")
结果: