1、感知机定义
如果输入是一个n维向量(x∈mathbb{R}^n),输出为样本的类别{+1,-1}。由输入到输出有以下函数:$$f(x)=sign(omega·x+b)$$ 则称该函数为感知机。其中(omega)和(b)为感知机参数,(omega)被称为权值(weight)或者权值向量(weight vector),(b)被称为偏置(bias),(omega · x)为点乘(对应元素相乘后相加,结果为一个标量),sign为符号函数,定义为:

感知机的几何解释如下:线性方程$$omega·x+b=0$$ 对应特征空间$mathbb{R}^n$中的一个超平面$S$,其中$omega$为该超平面的法向量,$b$是超平面的截距。这个超平面将空间划分成两个部分,位于两个部分的点分别对应着正、负两类。因此,$S$被称为**分离超平面**。如下图:
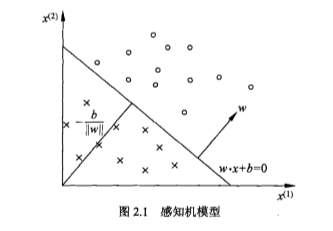
感知机学习,也就是通过训练数据集(样本的特征向量和类别):$$T={(x_1,y_1),(x_2,y_2),...,(x_n,y_n)}$$其中$x_i$为n维向量,$y_i∈{+1,-1}$,来求得模型$f(x)=sign(omega·x+b)$,也就是确定$omega,b$的值,然后根据求得的模型,预测新输入向量对应的类别。
### 2、感知机学习策略
如果对于训练数据集:$$T={(x_1,y_1),(x_2,y_2),...,(x_n,y_n)}$$其中$x_i$为n维向量,$y_i∈{+1,-1}$,存在某个超平面$S$,使得$$omega·x+b=0$$ 能够将数据集的正实例点和负实例点正确地划分到平面两侧,也就是说对于所有$y_i=1$的实例i,有$omega·x_i+b>0$,对于所有$y_j=-1$的实例j,有$omega·x+b<0$,那么我们称数据集T为**线性可分数据集**,否则称数据集T不可分。
假设训练数据集是线性可分的,那么感知机学习的目标就是找出一个超平面(确定$omega,b$的值)将正实例点和负实例点完全正确分开。为了找出这样的超平面,我们需要一个学习策略来定义损失函数并将损失函数最小化。
损失函数的一个自然选择是误分类点的个数,但这样的损失函数不是$omega,b$的连续可导函数,不易优化。损失函数的另一个选择是**误分类点到超平面S的距离之和**,这是感知机采用的。首先输入空间任一点$x∈mathbb{R}^n$到超平面$S$的距离为:
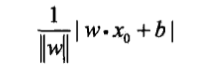
其中,$||omega||$是$omega$的$L_2$范数。
其次,对于误分类的数据来讲,有:
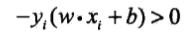
因为假如一个实例向量$x$属于正实例点(y=1),有$omega·x+b>0$,所以$y(omega·x+b)>0$。如果将$x$误分类为负实例点(也就是$omega·x=b<0$),所以有$-y(omega·x+b)>0$成立。所以误分类点$x_i$到超平面$S$的距离为:
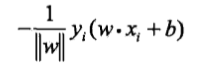
这样,假设超平面$S$误分类点的集合为$M$,则所有误分类点到超平面$S$的总距离为:
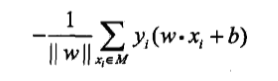
不考虑$frac{1}{||omega||}$,我们就得到了感知机学习的损失函数。
下面是损失函数的定义:
给定数据集$$T={(x_1,y_1),(x_2,y_2),...,(x_n,y_n)}$$其中$x_i$为n维向量,$y_i∈{+1,-1}$ ,感知机$f(x)=sign(omega·x+b)$学习的损失函数定义为:
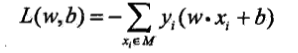
其中$M$是误分类点的集合。
显然,损失函数$L(omega,b)$是非负的(距离相加)。如果没有误分类点,那么损失函数的值为0。而且,误分类点越少,误分类点离超平面$S$越近,损失函数也就越小。一个特定样本的损失函数在误分类时是$omega,b$的线性函数,在正确分类是0。所以,对于给定的数据集T,损失函数$L(omega,b)$是$omega,b$的连续可到函数。
### 3、感知学习算法
在上一节中,我们已经求得了损失函数的形式,感知机的学习问题就转换为了损失函数的最优化问题(找到合适的$omega,b$使得超平面$S$能正确分类),在本节最优化使用的方法是**随机梯度下降法**。感知机学习算法分为两类:**原始形式**和**对偶形式**,两种算法在训练数据集$T$线性可分时均收敛(也就是经过算法的**有限次迭代**可以找到一个将训练数据集完全正确分开的超平面的感知机模型)。
#### 3.1、原始形式
感知学习算法是对损失函数最优化的算法,也就是找出$omega,b$使得**损失函数取最小值**,用公式表示就是:
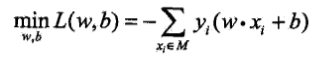
其中$M$为误分类点的集合。
最优化损失函数使用的是随机梯度下降法。首先任意选择两个值作为$omega,b$,然后用梯度下降法不断地极小化损失函数。极小化过程不是一次使所有的误分类点下降,而是一次随机选取一个误分类点使其梯度下降。
假设误分类点集合$M$是固定的,那么损失函数$L(omega,b)$的梯度如下:
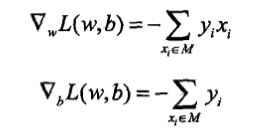
也就是说,如果实例向量$x_i$被误分类了,那么通过以下方法对$omega,b$进行更新(正确分类不更新):
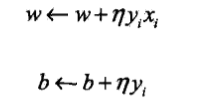
其中,$eta∈(0,1]$为**步长**,又称**学习率**。这样通过迭代可以使损失函数不断减小,直至为0。综上所述,算法步骤如下:
#### 感知机学习算法的原始形式
**输入**:
1、线性可分数据集$T={(x_1,y_1),(x_2,y_2),...,(x_n,y_n)}$其中$x_i$为n维向量,$y_i∈{+1,-1}$
2、学习率$eta$
**输出**:
1、$omega,b$
2、感知机模型$f(x)=sign(omega·x+b)$
**步骤**:
(1)选取初值$omega,b$
(2)在训练集中选取数据$(x_i,y_i)$
(3)如果$y_i(omega·x+b)≤0$(该点被误分类),那么更新$omega,b$的值:
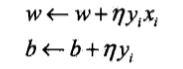
(4)转到(2),直到训练集中没有误分类点(损失函数为0)。
#### 一个例子
假设正实例点有$x_1=(3,3)^T,x_2=(4,3)^T$,负实例点有$x_3=(1,1)^T$,令$eta=1$,则求权值向量$omega=(omega_1,omega_2)^T$和$b$以及感知机学习模型$f(x)=sign(omega·x)+b$。
求解步骤如下:
(1)令初值$omega=b=0$
(2)对于$x_1=(3,3)^T$,$y_1(omega·x_1+b)=0≤0$,$x_1$未能被正确分类,所以更新$omega,b$的值:
$omega=omega+y_1x_1=(3,3)^T,b=b+y_1=1$
(3)继续判断点是否被正确分类。对于$x_1,x_2$,有$y_i(omega·x_i+b)>0$,所以$x_1,x_2$被正确分类。而对于$x_3$来讲,$y_3(omega·x_3+b)=(-1)·(6+1)<0$,所以$x_3$未被正确分类,更新$omega,b$:
$omega=omega+y_3x_3=(2,2)^T,b=b+y_3=0$
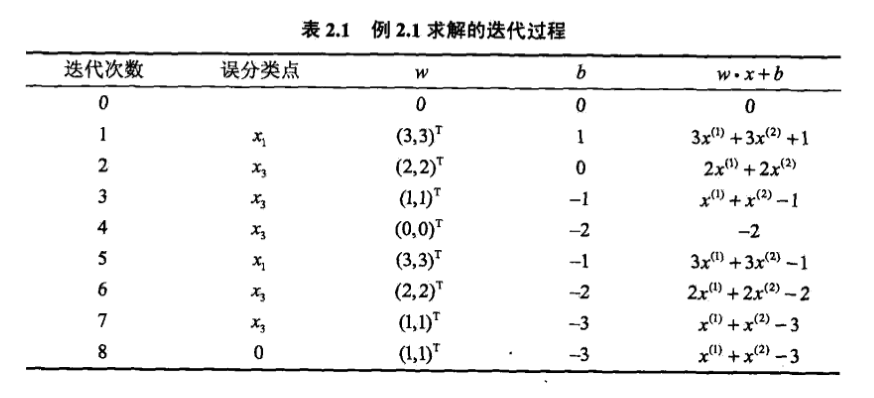
(4)如此进行下去,直到$omega=(1,1)^T, b=-3$时,所有的点都被正确分类。此时,分类超平面为$x^{(1)}+x^{(2)}-3=0$,感知机模型为$f(x)=sign(x^{(1)}+x^{(2)}-3)$。完整迭代过程如下表:
#### python实现
使用python将上面的例子实现,代码如下:
```python
import numpy as np
x = np.array([[3,3], [4,3], [1,1]])
y = [1, 1, -1]
def init():
eta = 1
w = np.array([0, 0])
b = 0
return eta, w, b
def perceptron():
eta, w, b = init()
i = 0
while i<len(x):
if y[i]*(np.dot(w,x[i])+b) <= 0:
w = w + eta * y[i] * x[i]
b = b + eta * y[i]
print u"x{}被误分类,更新后w={},b={}".format(i+1,w,b)
i = 0 #有误分类点,重新遍历
else:
i += 1
perceptron()
输出:
x1被误分类,更新后w=[3 3],b=1
x3被误分类,更新后w=[2 2],b=0
x3被误分类,更新后w=[1 1],b=-1
x3被误分类,更新后w=[0 0],b=-2
x1被误分类,更新后w=[3 3],b=-1
x3被误分类,更新后w=[2 2],b=-2
x3被误分类,更新后w=[1 1],b=-3
当感知学习算法采用不同的初值时,最终的解可以不同(解不止一个)。
#### 3.2、对偶形式
对偶形式与原始形式的区别在于判断点是否被正确分类的方法以及更新$omega,b$的方法。
#### 感知机学习算法的对偶形式
**输入**:
1、线性可分数据集$T={(x_1,y_1),(x_2,y_2),...,(x_n,y_n)}$其中$x_i$为n维向量,$y_i∈{+1,-1}$
2、学习率$eta$
**输出**:
1、$alpha,b$,其中$alpha=(alpha_1,alpha_2,...,alpha_n)^T$,是一个n维向量
2、感知机模型$f(x)=sign(sum_{j=1}^Nalpha_jy_jx_j·x+b)$
**步骤**:
(1)令初值$alpha=b=0$
(2)在训练集选取数据$(x_i, y_i)$
(3)如果$y_i(sum_{j=1}^Nalpha_jy_jx_j·x_i+b)≤0$,则更新$alpha,b$:
<div align=center>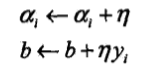
</div>
(4)转到(2)直至没有误分类的数据
我们看到在第(3)步中要频繁计算$x_j·x_i$,所以可以将它们提前算好存储在一个矩阵中,这个矩阵被称为**Gram矩阵**,有$G_{i,j}=x_i·x_j$。
#### 一个例子
数据和上一个例子相同:正实例点有$x_1=(3,3)^T,x_2=(4,3)^T$,负实例点有$x_3=(1,1)^T$,用感知机算法对偶形式求感知机模型。
求解步骤如下:
(1)取$alpha_i=0,i=1,2,3, b=0, eta=1$
(2)计算Gram矩阵:
<div align=center>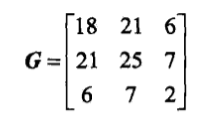
</div>
(3)当满足误分条件时:
<div align=center>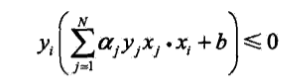
</div>
更新参数:
<div align=center>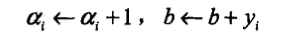
</div>
(4)迭代。过程见下表2.2。
(5)最后结果:
<div align=center>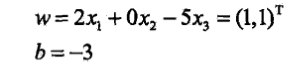
</div>
分离超平面:
<div align=center>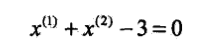
</div>
得出感知机模型:
<div align=center>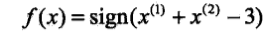
</div>
算法步骤(4)中的迭代过程如下:
<div align=center>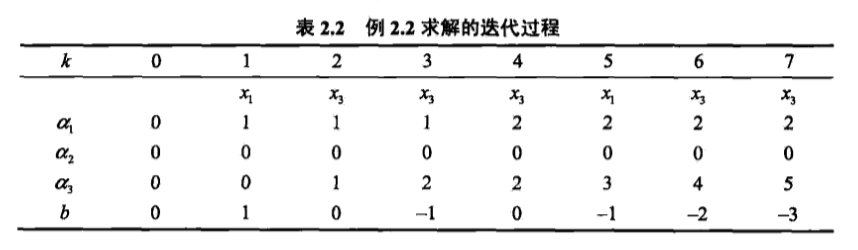
</div>
需要注意的是,当k=4时,$alpha_1,alpha_2,alpha_3,b=1,0,3,-2$,而不是上图的2,0,3,-1。这是原书的一个印刷错误。
可以看到和原始形式的结果一样,并且对偶形式也是收敛的,存在多个解。
#### python实现
将上面的步骤使用python实现,代码如下:
import numpy as np
x = np.array([[3,3], [4,3], [1,1]])
y = [1, 1, -1]
g = np.zeros([3, 3])
计算gram矩阵
def gram():
for i in range(len(x)):
for j in range(len(x)):
g[i,j] = np.dot(x[i], x[j])
def init():
gram()
eta = 1
alpha = np.zeros([1, 3], dtype=int).flatten()
b = 0
return eta, alpha, b
得到损失函数的前半部分求和
def get_sum(alpha, xi):
s = 0
for j in range(3):
s += np.dot(alpha[j]y[j]x[j], xi)
return s
def perceptron():
eta, alpha, b = init()
i = 0
while i<len(x):
if y[i]*(get_sum(alpha, x[i])+b) <= 0:
alpha[i] += 1
b += y[i]
print "x{}被误分类,更新后alpha={},b={}".format(i+1,alpha,b)
i = 0
else:
i += 1
perceptron()
输出:
x1被误分类,更新后alpha=[1 0 0],b=1
x3被误分类,更新后alpha=[1 0 1],b=0
x3被误分类,更新后alpha=[1 0 2],b=-1
x3被误分类,更新后alpha=[1 0 3],b=-2
x1被误分类,更新后alpha=[2 0 3],b=-1
x3被误分类,更新后alpha=[2 0 4],b=-2
x3被误分类,更新后alpha=[2 0 5],b=-3
### 4、总结
1、感知机是根据数据的特征向量对其进行二类分类(+1,-1)的线性分类模型:$$f(x)=omega·x+b$$ 感知机模型在集合上对应输入空间的分离超平面$$omega·x+b=0$$
2、感知机学习的策略是**极小化损失函数**:
<div align=center>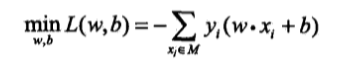
</div>
损失函数对应着误分类点到超平面的距离之和。
3、感知机学习算法是基于随机梯度下降算法的对损失函数的最优化算法,有**原始形式**和**对偶形式**。
4、当训练集**线性可分**时,感知机学习算法是收敛的。当训练集线性可分时,感知机学习算法存在无穷多个解,当所选初值或者迭代顺序不同时,其解也会不同。
### 5、参考
1、李航《统计学习方法》