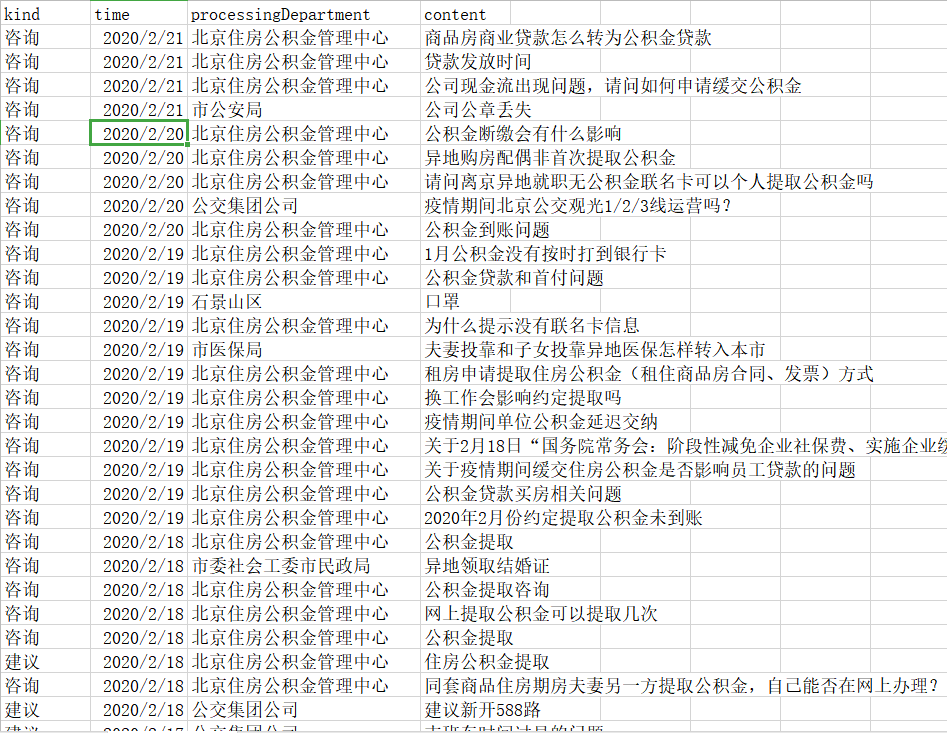
问题:
换页url不边,Ajax加载,于是进行抓包:
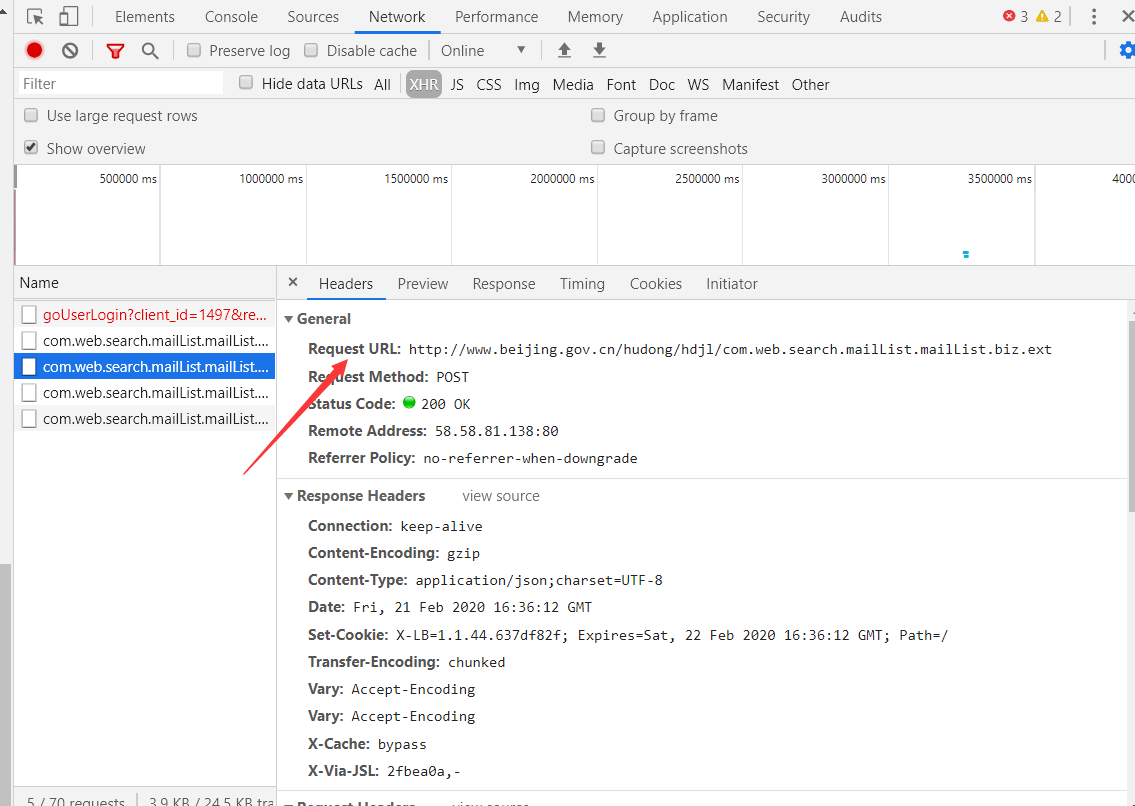
可是发现换页的时候Request URL也不变(看很多类似教程都是找url变化规律)
这时候我选择使用selenium和Chrome配合,模拟浏览器输入页数获得网页:
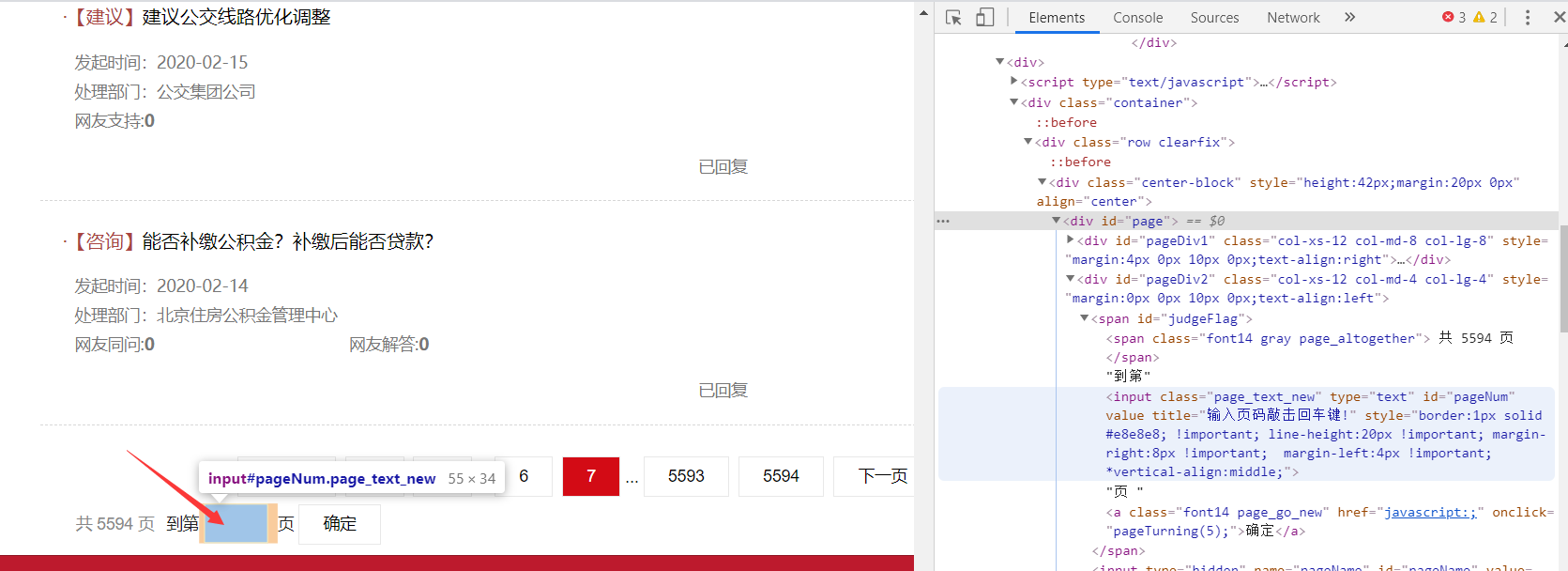
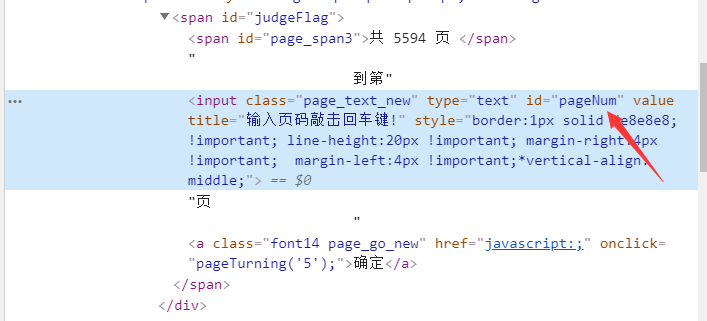
源代码:
from lxml import etree
import requests
import csv
from selenium import webdriver
import time
import os
from selenium.webdriver.chrome.webdriver import WebDriver
#创建csv
outPath = 'D://xinfang_data.csv'
if (os.path.exists(outPath)):
os.remove(outPath)
fp = open(outPath, 'wt', newline='', encoding='utf-8') # 创建csv
writer = csv.writer(fp)
writer.writerow(('kind', 'time', 'processingDepartment', 'content'))
#请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
# 创建浏览器对象
driver = webdriver.Chrome()
# 得到网页信息
def get_info(num):
driver.get(url)
driver.implicitly_wait(10) # 隐式等待n秒,解释JavaScript是需要时间的,如果短了就无法正常获取数据,如果长了浪费时间;implicitly_wait()给定时间智能等待
#driver.find_element_by_xpath('//*[@id="pageNum"]').clear()
driver.find_element_by_id('pageNum').clear()#清除输入框
#driver.find_element_by_id('pageNum').send_keys(num)
driver.find_element_by_xpath('//*[@id="pageNum"]').send_keys(num)#输入页数
driver.find_element_by_xpath('//*[@id="judgeFlag"]/a').click()#单击确认框
time.sleep(1)#一定要停一下,否则加载不出来一直输出第一页
#print(driver.current_window_handle)#当前页面句柄
html = driver.page_source
#print(driver.page_source)
return html
#解析HTML文件,获取数据
def get_data(html):
selector = etree.HTML(html)
infos=selector.xpath('//*[@id="mailul"]/div')
for info in infos:
kind=info.xpath('div[1]/a/font/text()')[0]
time=info.xpath('div[2]/div[1]/div[1]/text()')[0]
processingDepartment = info.xpath('div[2]/div[1]/div[2]/span/text()')[0]
content = info.xpath('div[1]/a/span/text()')[0]
#处理得到的字符串
parsekind=kind.strip().strip('·【').strip('】')
#print(parsekind)
parsetime=time.strip().strip('发起时间:').replace("-", "/")
#print(parsetime)
parsepd = processingDepartment.strip().strip('处理部门:')
#print(parsepd)
parsecontent = content.strip()
#print(parsecontent)
#写入csv
writer.writerow((parsekind,parsetime,parsepd,parsecontent))
if __name__ == '__main__':
url = 'http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.flow'
for i in range(1,1000):
html=get_info(i)
get_data(html)
time.sleep(1)
爬取数据: