20145218 《信息安全系统设计基础》第4周学习总结
教材学习内容总结
3.1历史观点
- X86 寻址方式经历三代:
- DOS时代的平坦模式,不区分用户空间和内核空间,很不安全
- 8086的分段模式
- IA32的带保护模式的平坦模式
- Linux使用平坦寻址方式,使程序员将整个存储空间看做一个大的字节数组。
3.2程序编码
- ISA:指令集体系结构,机器级程序的格式和行为,它定义了处理器状态、指令的格式以及每条指令对状态的影响。
- 程序计数器(通常称为PC,用%eip表示),指示将要执行的下一条指令在存储器中的地址。
- 整数寄存器文件:存储地(对应于C语言的指针)或整数数据。
- 条件码寄存器:保存着最近执行的算数或逻辑指令的状态信息,用来实现控制或者数据流中的条件变化。
- 浮点寄存器:用来存放浮点数据。
编译过程:
- C预处理器插入宏和头文件:gcc -E xxx.c -o xxx.i
- 编译器产生源代码的汇编代码:gcc -S xxx.i -o xxx.s
- 汇编器化成二进制目标代码:gcc -c xxx.s -o xxx.o
- 链接器生成最终可执行文件:gcc xxx. -o xxx
- 用objdump -d xxx.o -o xxx.s 反汇编
- 建立函数调用栈帧的汇编代码:
pushl %ebp 将寄存器%ebp中的内容压入程序栈
movl %esp,%ebp 将%ebp中的内容放入寄存器%esp
......
popl %ebp 寄存器%ebp中内容出栈
ret 返回结果
注意
- 64位机器上想要得到32代码:gcc -m32 -S xxx.c
- MAC OS中没有objdump, 有个基本等价的命令otool
- Ubuntu中 gcc -S code.c (不带-O1) 产生的代码更接近教材中代码(删除"."开头的语句)
- 找到程序的字节表示:
(gdb) x/17xb sum - 二进制文件可以用od命令查看,也可以用gdb的x命令查看。有些输出内容过多,我们可以使用 more或less命令结合管道查看,也可以使用输出重定向来查看
od code.o | more od code.o > code.txt
格式注解
- 开头的行都是指导汇编器和链接器的命令,gcc -S 产生的汇编中可以把 以‘.’开始的语句都删除了再阅读
- Linux和Windows的汇编格式的区别:
- ATT格式(Linux下的汇编格式)&Intel格式(Windows的汇编格式);
- Intel代码省略了指示大小的后缀。我们看到指令mov而不是movl;
- ntel代码省略了寄存器名字前的%,使用的是esp而不是%esp;
- Intel代码用不同方式来描述存储器中的位置:例如,是
DWORD PTR [ebp+8]’而不是'8(%ebp)
3.3数据格式
- 大多数GCC生成的汇编代码指令都有一个字符后缀,表明操作数的大小。
3.4访问信息
寄存器
一个IA32中央处理单元(CPU)包含一组8个存储32位值的寄存器。用来存储整数数据和指针。
%eax %ax (%ah %al) 通用寄存器
%ecx %cx (%ch %cl) 通用寄存器
%edx %dx (%dh %dl) 通用寄存器
%ebx %bx (%bh %bl) 通用寄存器
%esi %si 用来操纵数组
%edi %di 用来操纵数组
%esp %sp 操纵栈帧
%ebp %bp 操纵栈帧
注意
对于32位的eax,16位的ax,8位的ah,al都是独立的,我们通过下面例子说明:
假定当前是32位x86机器,eax寄存器的值为0x8226,执行完addw $0x8266
,%ax指令后eax的值是多少?
解析:0x8226+0x826=0x1044c, ax是16位寄存器,出现溢出,最高位的1会
丢掉,剩下0x44c,不要以为eax是32位的不会发生溢出.
寻址方式
- 根据操作数的不同类型,寻址方式可分为以下三种:
- 立即数寻址方式:操作数为常数值,写作$后加一个整数。
- 寄存器寻址方式:操作数为某个寄存器中的内容。
- 存储器寻址方式:根据计算出来的地址访问某个存储器的位置。
- 寻址模式:一个立即数偏移Imm,一个基址寄存器Eb,一个变址寄存器Ei,一个比例因子s(必须为1,2,4,8)有效地址计算为:Imm(Eb,Ei,s) = Imm + R[Eb] + R[Ei]*s
数据传送指令
-
MOV相当于C语言的赋值'='
mov S,D S中的字节传送到D中
注意
- ATT格式中的方向;
- 不能从内存地址直接MOV到另一个内存地址,要用寄存器中转一下;
- 区分MOV,MOVS(符号扩展),MOVZ(零扩展)
- push和pop:
pushl S R[%esp] ← R[%esp]-4
M[R[%esp]] ← S
popl D D ← M[R[%esp]]
R[%esp] ← R[%esp]+4
注意
- 栈顶元素的地址是所有栈中元素地址中最低的,后进先出;
- 指针就是地址;局部变量保存在寄存器中。
3.5算术和逻辑操作
加载有效地址
- leal,从存储器读数据到寄存器,而从存储器引用的过程实际上是将有效地址写入到目的操作数。
- 目的操作数必须是一个寄存器。
一元操作和二元操作
- 一元操作:只有一个操作数,既是源又是目的,可以是一个寄存器或者存储器。
- 二元操作:第二个操作数既是源又是目的,两个操作数不能同时是存储器。
移位
- 先给出位移量,然后是位移的数值,可进行算数和逻辑右移。
- 移位操作移位量可以是立即数或%cl中的数。
3.6控制
条件码
描述最近的算数或者逻辑操作的属性,可以检测这些寄存器来执行条件分支指令。
- CF:进位标志,最近操作使高位产生进位,用来检测无符号操作数的溢出
- ZF:零标志,最近操作得出的结果为0
- SF:符号标志,最近操作得到的结果为负数
- OF:溢出标志,最近操作导致一个补码溢出-正溢出或负溢出。
注意
- leal不改变条件码寄存器
- CMP与SUB的区别:CMP也是根据两个操作数之差设置条件码,但只设置条件码而不更新目标寄存器
- 有条件跳转的条件看状态寄存器(教材上叫条件码寄存器)
访问条件码的读取方式
- 根据条件码的某个组合,将一个字节设置成0或1;
- 跳转到程序某个其他的部分;
- 有条件的传送数据。
- SET指令根据t=a-b的结果设置条件码
跳转指令及其编码
控制中最核心的是跳转语句:
- 有条件跳转(实现if,switch,while,for)
- 无条件跳转jmp(实现goto)
当执行PC相关的寻址时,程序计数器的值是跳转指令后面那条指令的地址,而不是跳转指令本身的地址。
翻译条件分支
- 将条件和表达式从C语言翻译成机器代码,最常用的方式是结合有条件和无条件跳转。
- C语言中if-else语句的通用形式:
if(test-expr)
then-statement
else
else-statement
- 汇编结构:
t=test-expr;
if!(t)
goto false;
then-statement
goto done;
false:
else-statement
done:
循环
do-while循环
- C语言中do-while语句的通用形式:
do
body-statement
while(test-expr);
- 汇编结构:
loop:
body-statement
t=test-expr;
if(t)
goto loop;
while循环
- C语言中while语句的通用形式:
while(test-expr)
body-statement
- 汇编结构:
t=test-expr;
if(!t)
goto done;
loop:
body-statement
t=test-expr;
if(t)
goto loop;
done:
for循环
- C语言中for语句的通用形式:
for(init-expr;test-expr;update-expr)
body-statement
- 汇编结构
init-expr
t=test-expr;
if(!t)
goto done;
loop:
body-statement
update-expr;
t=test-expr;
if(t)
goto loop;
done:
switch语句
- 根据一个整数索引值进行多重分支,执行switch语句的关键步骤是通过跳转表来访问代码位置,使结构更加高效。
3.7过程
数据传递、局部变量的分配和释放通过操纵程序栈来实现。
栈帧结构
- 为单个过程分配的栈叫做栈帧,寄存器%ebp为帧指针,而寄存器指针%esp为栈指针,程序执行时栈指针移动,大多数信息的访问都是相对于帧指针。
- 栈向低地址方向增长,而栈指针%esp指向栈顶元素。
转移控制
- call:目标是指明被调用过程起始的指令地址,效果是将返回地址入栈,并跳转到被调用过程的起始处。
- ret:从栈中弹出地址,并跳转到这个位置。
- 函数返回值存在%eax中
寄存器使用惯例
- 程序寄存器是唯一能被所有过程共享的资源,调用者保存寄存器 和 被调用者保存寄存器是分开的,对于哪一个寄存器保存函数调用过程中的返回值要有统一的约定。
3.8数组分配和访问
- 对数据类型T和整型常数N的声明5:T A[N];
- 指针运算:单操作数的操作符&和*可以产生指针和间接引用指针。leal指令用来产生地址,movl用来引用存储器
- 嵌套的数组
- 定长数组(程序要用一个常数作为数组的维度或缓冲区大小时最好使用#define声明将这个常数与一个名字联系起来,后面使用该名字代替常数的数值)
- 变长数组(允许数组的维度是表达式)
3.9 异质的数据结构
- 两种结合不同类型的对象来创建数据类型的机制:结构(structure)、联合(union)
- 结构:结构的各个字段的选取是在编译时处理的,机器代码不包含关于字段声明或字段名字的信息
- 联合:允许以多种类型来引用一个对象,是用不同的字段来引用相同的存储器块。一个联合的总的大小等于它最大字段的大小。联合还可以用来访问不同数据类型的位模式。
- 数据对齐:某种类型对象必须是某个K值(通常是2、4或8)的倍数。这种对齐限制简化了形成处理器和存储器系统之间接口的硬件设计
3.10 综合:理解指针
- 每个指针都对应一个类型
- 每个指针都有一个值
- 指针用&运算符创建
- 运算符*用于指针的间接引用
- 数组与指针紧密联系
- 将指针从一种类型强制转换成另一种类型,只改变它的类型而不改变它的值
- 指针也可以指向函数
3.11 关于栈帧的gdb命令
- backtrace/bt:打印当前的函数调用栈的所有信息。后面加n或-n表示打印栈顶上n层(或者下n层)的栈信息。
- frame n:n为栈中的层编号,从0开始,类似C语言中数组的下标。移动到n指定的栈帧中去,并打印选中的栈的信息。如果没有n,则打印当前帧的信息。
- up n:表示向栈的顶移动n层。
- down n:表示向栈底移动n层。
习题3.3
当我们调用汇编器的时候,下面代码的每一行都会产生一个错误信息,解释每一行都是哪里出了错
- movb $0xf,(%bl) ---(%bl)不能做为寄存器地址
- movw (%eax),4(%esp)---目的操作数与源操作数不能都是存储器
- movb %si, 8(%ebp)---指令后缀与寄存器地址不匹配
习题3.5
xp,yp,zp分别存储在相对于寄存器%edp中地址值偏移8、12、16的地方。试写出与以下代码等价的C语言代码
movl 8(%ebp),%edi
movl 12(%ebp),%edx
movl 16(%ebp),%ecx
movl (%edx),%ebx
movl (%ecx),%esi
movl (%edi),%eax
movl %eax,(%edx)
movl %ebx,(%ecx)
movl %esi,(%edi)
代码如下:
void decode1(int *xp,int *yp,int *zp)
{
int x=*xp;
int y =*yp;
int z = *zp;
*yp = x;
*zp = y;
*xp = z;
}
习题3.9
根据汇编代码,补充C语言代码(x,y,z分别存储在相对于寄存器%edp中地址值偏移8、12、16的地方)
movl 12(%ebp),%eax
xorl 8(%ebp),%eax
sarl $3,%eax
notl %eax
subl 16(%ebp),%eax
C语言代码:
int arith(int x,int y,int z)
{
int t1 = `x^y`;
int t2 = `3*t1`;
int t3 = `~t2`;
int t4 = `t3-z`;
return t4;
}
习题3.16
已知下列C语言代码:
void cond(int a,int *p)
{
if(p&&a>0)
*p +=a;
}
按照与汇编代码等价的C语言goto版本,写一个与之等价的C语言代码。
void goto_cond(int a,int *p)
{
if(p == 0)
goto done;
if(a<=0)
goto done;
*p +=a;
done:
return;
}
为什么C语言只有一个if语句;而汇编中有两个分支呢?
- 第一个条件分支是&&表达式实现的一部分;如果对p非空的测试失败,代码会跳过对a的测试
实验练习
C语言代码:

使用gcc –S –o main.s main.c -m32命令编译成汇编代码如下:
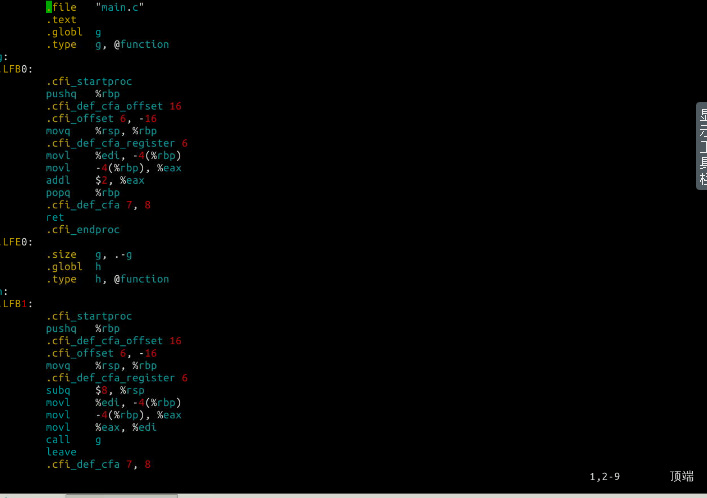
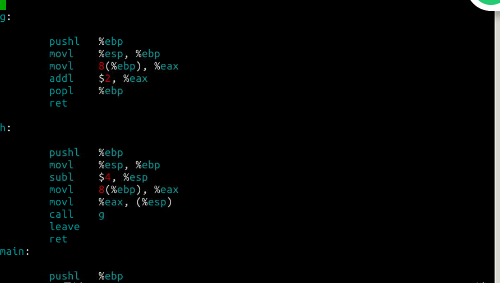
教材学习中的问题和解决过程
- 既然leal是mov的变形,leal与mov有何区别,两者分别如何使用?
- mov是将数据从源操作传到目的操作数中,lea是将源操作数的地址传到目的操作数中。一个是数据,一个是地址
课后作业中的问题和解决过程
1.习题3.23
leal (%eax,%eax),%edx
movl %ebx,%eax
(%eax中存放着val,%ebx中存放x。)
这两行代码如何实现val<<1的效果。
2.习题3.30
call next
next:
popl %eax
是否可以理解为call指令的效果是将返回地址入栈,也就是call后面指令的地址,即popl %eax,而%eax的值又被设置为popl指令的地址,整个过程是顺序执行的而并没有发生跳转,所以无需ret弹出。
本周代码托管截图
代码托管链接:https://git.oschina.net/senlinmilelu/ISdesign20145218/tree/master
其他(感悟、思考等,可选)
在这周的自学中,主要是学习了机器内执行程序的时候所发生的动态变化。要究动态,就必须了解静态的内部“参量”;有前面打下的基础,才有后面学得懂、学得透的可能性。本周学习需要大量的上学期汇编语言的基础,才能保证流畅阅读基础的汇编代码,而不用时时刻刻“查字典”,但实际上在上学期学习中也没有做的很好,所以在一定程度上加大了本周学习的难度。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 3/4 | 18/38 | |
| 第三周 | 500/1000 | 4/7 | 22/60 | |
| 第四周 | 300/1300 | 4/9 | 30/90 | |
| 第五周 | 300/1300 | 5/9 | 30/90 |