 介绍
介绍
JIRA是Atlassian公司出品的项目与事务跟踪工具,被广泛应用于缺陷跟踪、客户服务、需求收集、流程审批、任务跟踪、项目跟踪和敏捷管理等工作领域。很多企业与互联网公司都在使用Jira作为内部流程管理系统,进行团队协作与问题单管理。
JIRA的后台数据库可以选择使用嵌入式数据库或MySQL/PGSQL等专业数据库。一般来说,大部分企业选择MySQL作为底层的数据存储。但是,随着问题工单的不断积累,对于较大型企业来说MySQL所支撑的数据量可能很快达到瓶颈。用户可以选择使用SequoiaDB分布式数据库替换MySQL默认的InnoDB引擎,在保持对Jira应用程序完整兼容的前提下做到弹性横向扩张。
JIRA 是目前比较流行的基于Java架构的管理系统,由于Atlassian公司对很多开源项目实行免费提供缺陷跟踪服务,因此在开源领域,其认知度比其他的产品要高得多,而且易用性也好一些。同时,开源则是其另一特色,在用户购买其软件的同时,也就将源代码也购置进来,方便做二次开发。JIRA功能全面,界面友好,安装简单,配置灵活,权限管理以及可扩展性方面都十分出色。
通过阅读本文,用户可以了解到如何使用SequoiaDB巨杉数据库的MySQL实例无缝替换标准MySQL数据库。SequoiaDB巨杉数据库允许用户在不更改一行代码的情况下直接对已有应用进行后台MySQL数据库迁移。
通过使用SequoiaDB巨杉数据库,用户可以得到:
l 水平弹性扩张
l MySQL的100%全兼容
l 优秀的交易性能
安装SequoiaDB
本文使用Linux Ubuntu Server 18.10作为服务器,SequoiaDB巨杉数据库版本为3.2.1。
本教程默认使用sudo用户名密码为“sequoiadb:sequoiadb”,默认home路径为/home/sequoiadb。
对于使用CentOS等其他Linux版本的用户,本文所描述的流程可能略有不同,需要根据实际情况自行调整。
下载SequoiaDB标准虚拟机模板的用户可以直接跳过该安装部署步骤。
1)下载并安装SequoiaDB巨杉数据库
|
$ wget http://cdn.sequoiadb.com/images/sequoiadb/x86_64/sequoiadb-3.2.1-linux_x86_64.tar.gz $ tar -zxvf sequoiadb-3.2.1-linux_x86_64.tar.gz $ cd sequoiadb-3.2.1/ $ sudo ./setup.sh |
之后一直回车确认各个默认参数即可。
2) 使用数据库实例用户创建默认实例
|
$ sudo su sdbadmin $ /opt/sequoiadb/tools/deploy/quickDeploy.sh $ exit |
安装JIRA
本教程使用JIRA 8.2.1。
1)用户可以登录JIRA的官网https://www.atlassian.com/software/jira/download下载安装包,或直接通过wget进行下载。
|
$ wget https://www.atlassian.com/software/jira/downloads/binary/atlassian-jira-software-8.2.1-x64.bin |
|
注:JIRA官方安装文档位于 |
2)执行安装包
|
$ chmod 755 atlassian-jira-software-8.2.1-x64.bin $ sudo ./atlassian-jira-software-8.2.1-x64.bin |
3)默认情况下,测试版的JIRA不提供MySQL JDBC驱动,因此需要手工下载驱动包。由于当前JIRA版本不支持MySQL 8的驱动,因此需要下载MySQL 5.1.x的JDBC安装包。

或直接通过wget下载
|
$ wget https://downloads.mysql.com/archives/get/file/mysql-connector-java-5.1.46.tar.gz $ tar -zxvf mysql-connector-java-5.1.46.tar.gz |
4)将JDBC驱动拷贝至JIRA的lib目录下并重启JIRA
|
$ sudo cp mysql-connector-java-5.1.46/mysql-connector-java-5.1.46.jar /opt/atlassian/jira/lib/ $ sudo /opt/atlassian/jira/bin/shutdown.sh $ sudo /opt/atlassian/jira/bin/startup.sh |
5)开启SequoiaDB巨杉数据库事务功能并设置默认隔离级别RC
|
$ sudo su sdbadmin $ /opt/sequoiadb/bin/sdb > db = new Sdb() ; > db.updateConf ( { transactionon: true, transisolation: 1 } ) ; > quit ; $ /opt/sequoiadb/bin/sdbstop $ /opt/sequoiadb/bin/sdbstart |
6)创建数据库
|
$ /opt/sequoiasql/mysql/bin/mysql -S /opt/sequoiasql/mysql/database/3306/mysqld.sock -u root mysql> create user 'sequoiadb'@'localhost' identified by 'sequoiadb'; mysql> create database jira; mysql> grant all on jira.* to 'sequoiadb'@'localhost'; mysql> grant all privileges on *.* to 'sequoiadb'@'%' identified by 'sequoiadb' with grant option; mysql> exit $ exit |
配置JIRA
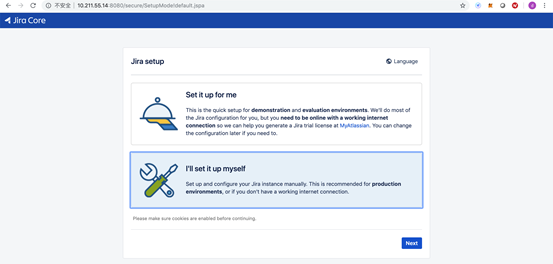
1)使用浏览器登录服务器IP地址的8080端口,选择“I’ll set it up myself”
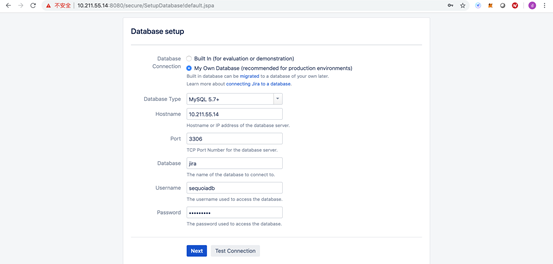
2)数据库设置页面选择“My Own Database”,填入服务器IP地址、jira数据库名、以及sequoiadb:sequoiadb作为用户名密码
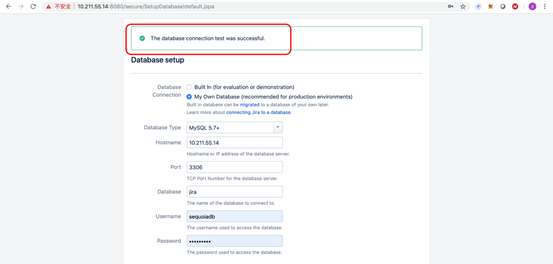
3)点击Test Connection确认数据库连接正确
4)点击Next创建数据库,并跟随导航进入注册页面

5)作为测试账户,用户可以点击“generate a Jira trial license”并在官网注册申请测试授权账号

6)将授权码黏贴到安装界面下并点击Next,用户名密码设置为默认sequoiadb:sequoiadb
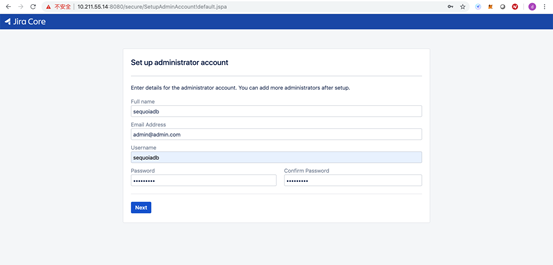
7)完成安装设置并创建一个默认sequoiadb的项目
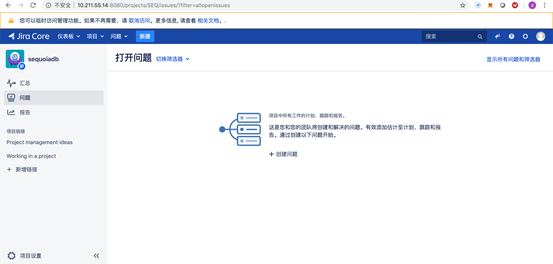
切换数据库至SequoiaDB
在JIRA的安装部署程序中,默认指定了InnoDB作为所有表的存储引擎。因此接下来用户可以通过mydumper与myloader将InnoDB的表切换至SequoiaDB。
1)停止JIRA
|
$ sudo /opt/atlassian/jira/bin/shutdown.sh |
2)下载mydumper
|
$ wget https://github.com/maxbube/mydumper/releases/download/v0.9.5/mydumper_0.9.5-2.xenial_amd64.deb $ sudo dpkg -i mydumper_0.9.5-2.xenial_amd64.deb |
3)导出jira数据库所有表
|
$ sudo su – sdbadmin $ mkdir temp $ mydumper -h 10.211.55.14 -P 3306 -u sequoiadb -p sequoiadb -t 16 -F 64 -B jira -o ./temp |
4)将所有InnoDB表替换为SequoiaDB引擎
|
$ sed -i "s/InnoDB/SequoiaDB/g" `grep -R "InnoDB" -rl ./temp` |
5)重新创建jira库并使用myloader导入数据
|
$ /opt/sequoiasql/mysql/bin/mysql -S /opt/sequoiasql/mysql/database/3306/mysqld.sock -u root mysql> drop database jira; mysql> create database jira; mysql> grant all on jira.* to 'sequoiadb'@'localhost'; mysql> exit $ myloader -h 10.211.55.14 -u sequoiadb -p sequoiadb -P 3306 -t 32 -d ./temp $ exit |
6)重新启动JIRA服务
|
$ sudo /opt/atlassian/jira/bin/startup.sh |
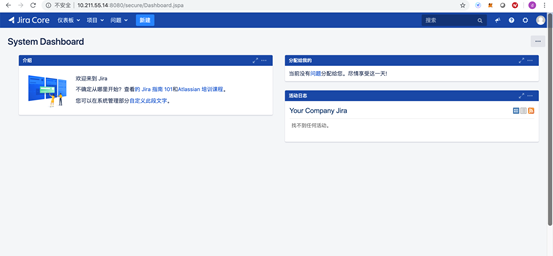
7)重新登录浏览器,如今JIRA后台所有的数据已经由MySQL迁移至SequoiaDB
结论
SequoiaDB巨杉数据库作为一款分布式数据库,提供包括结构化SQL、与非结构化文件系统和对象存储的机制。
通过SequoiaDB创建的MySQL实例,能够提供与标准MySQL全兼容的SQL与DDL能力,用户无需调整DDL或SQL即可实现无缝透明地访问分布式表结构。
本文向读者展示了如何通过SequoiaDB的MySQL实例,实现与标准MySQL的无缝迁移。通过使用SequoiaDB巨杉数据库,用户可以在满足标准ACID与MySQL协议的基础上,实现近无限的弹性扩展能力。