前言
爬虫的基本知识已经告一段落,这次就找个网站实战一波。但是为什么选择了基金?这还要从我的故事讲起。
我是一名韭零后,小白一枚,随大流入基市一载,佛系持有,盈亏持平。看到年前白酒红胜火,遂小投一笔,未曾想开市之后绿如蓝,赚的本韭菜空喜欢,一周梦回解放前。
还记得那天的天台的风很凉,低头往下看车来车往,有点恐高。想点一支烟烘托一下气氛,才想起我不会抽烟。悲伤之际,突然想起一位名人曾说过:"只要你不跑,你就不是韭菜"。于是转身回家,坐在电脑前写下了这篇文章。

准备
- 明确爬取目标
爬取各个板块基金数据 - 寻找数据网站:天天基金网(fund.eastmoney.com)

- 确定网站入口:在首页上点击 投资工具 -> 主题基金 进入主题页面,选择 主题索引,如下图:
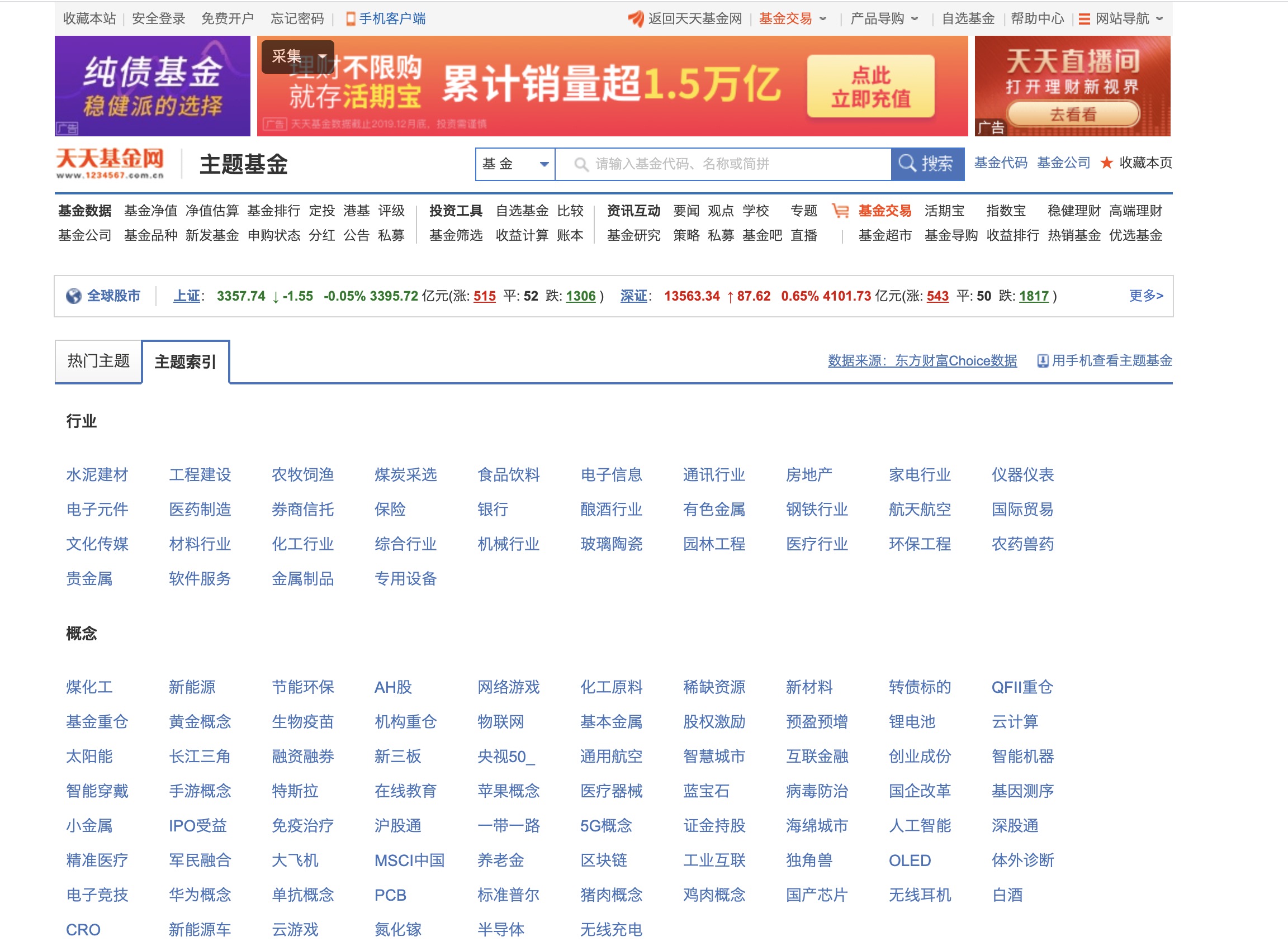
- 确定爬取内容点击主题下的主题索引下的 白酒 进入白酒列表。
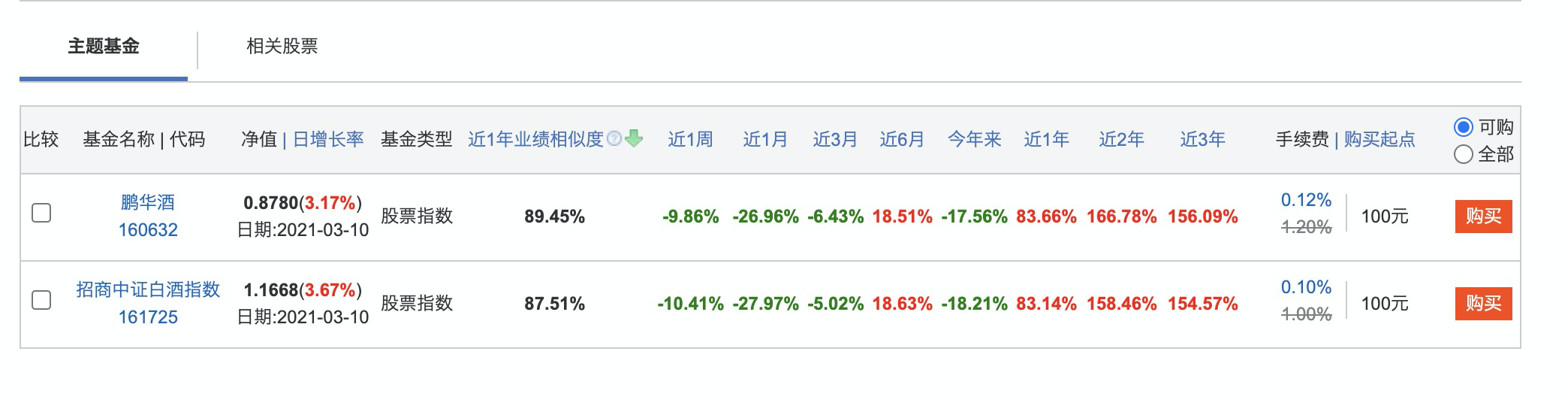
点击招商中证白酒,进入详情页面。
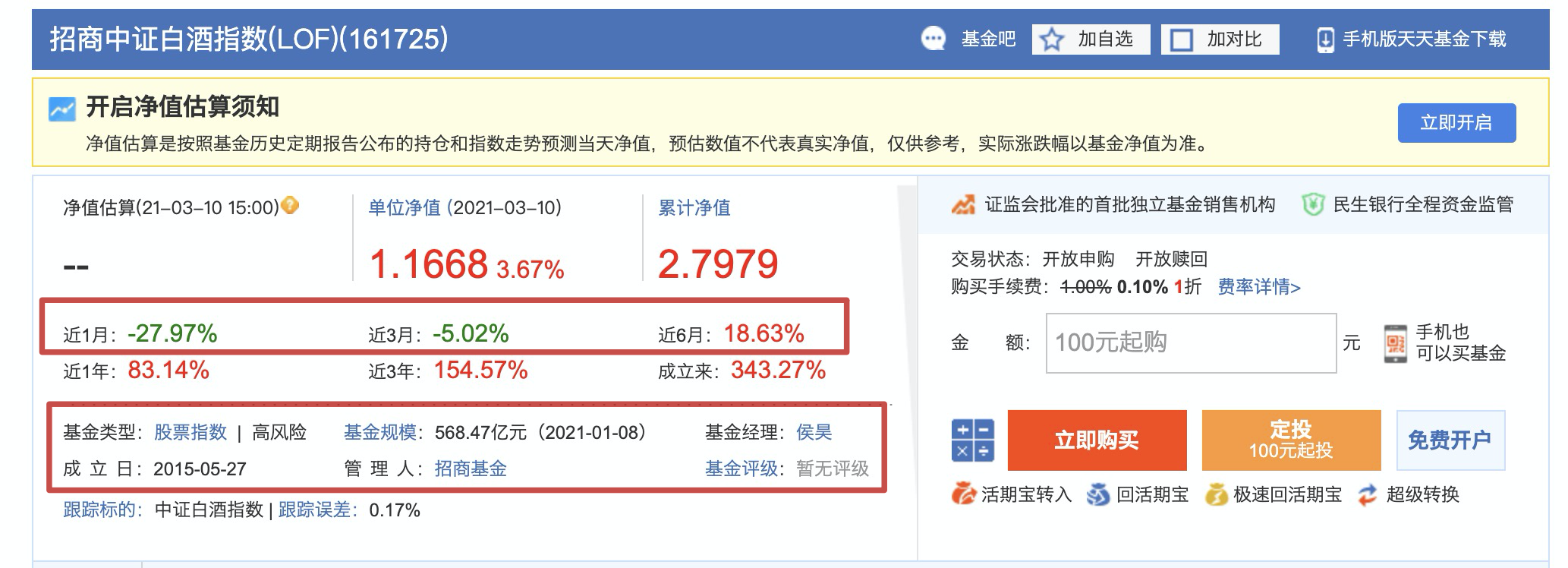
根据自己的需求,从页面上的内容确定要爬取的字段。这里要爬取的字段除了图中红框部分,还有基金名称、基金编码、所属主题字段。
- 明确页面跳转关系:主题页面 -> 列表 -> 详情页,一共三层
网站分析
第一层:请求网站入口
F12或者右键选择检查,使用开发者工具找到基金分类的html元素。
右键html元素,复制xpath,当然你可以自己写。
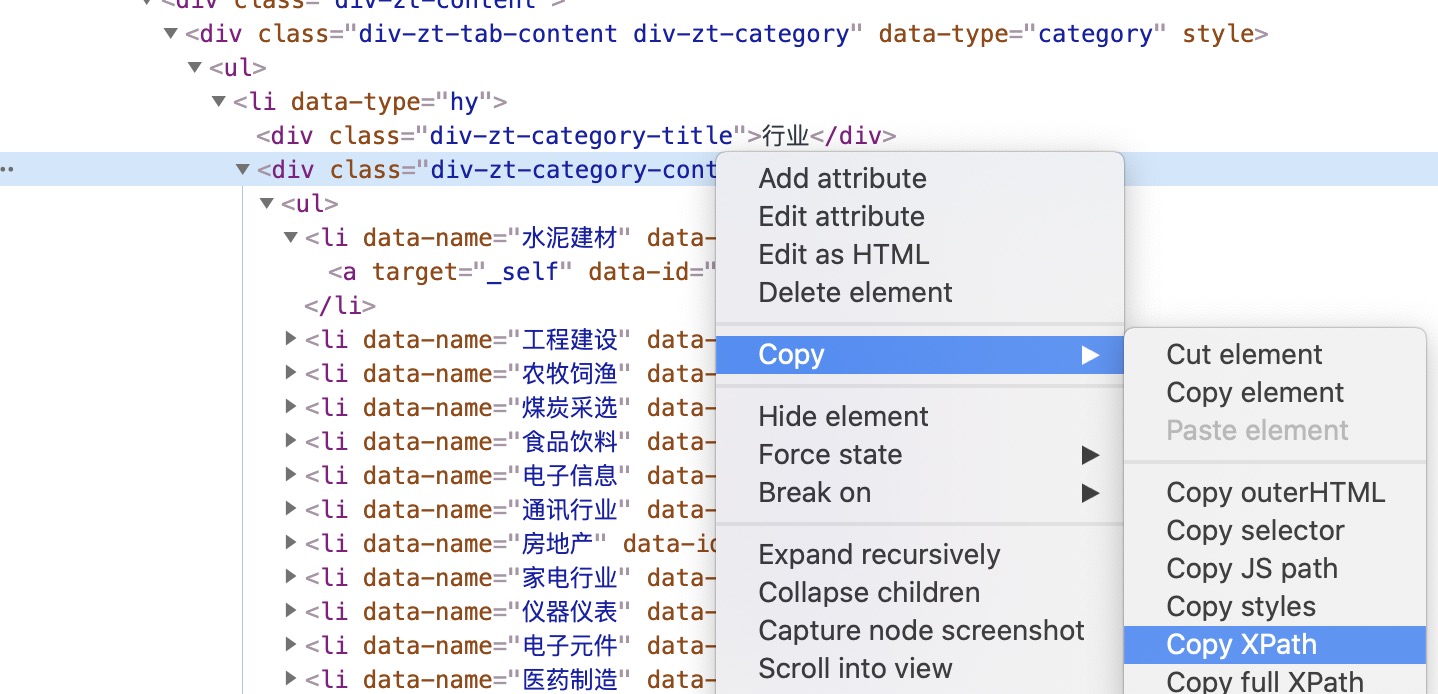
开发代码获取分类列表:
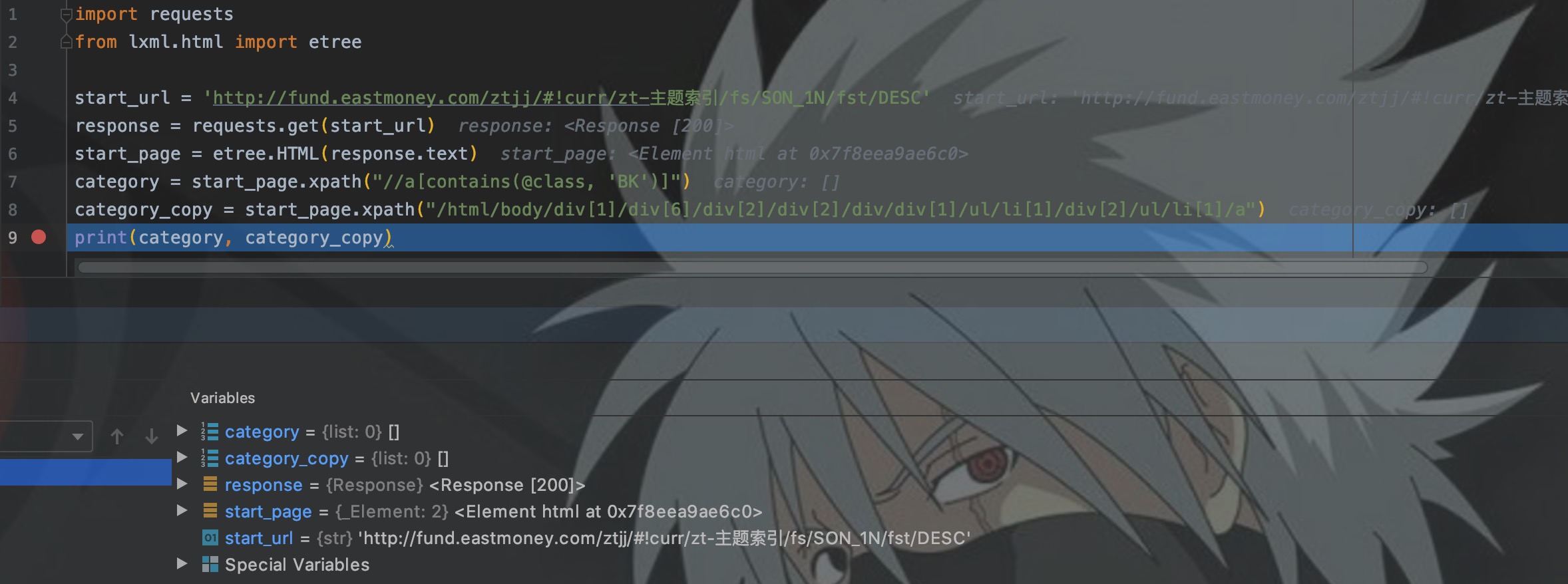
如图,按理说使用我自己写的xpath和拷贝的xpath,都可以获取到分类的html元素,但结果结果却为空。带着疑问,去查看返回的网页内容。
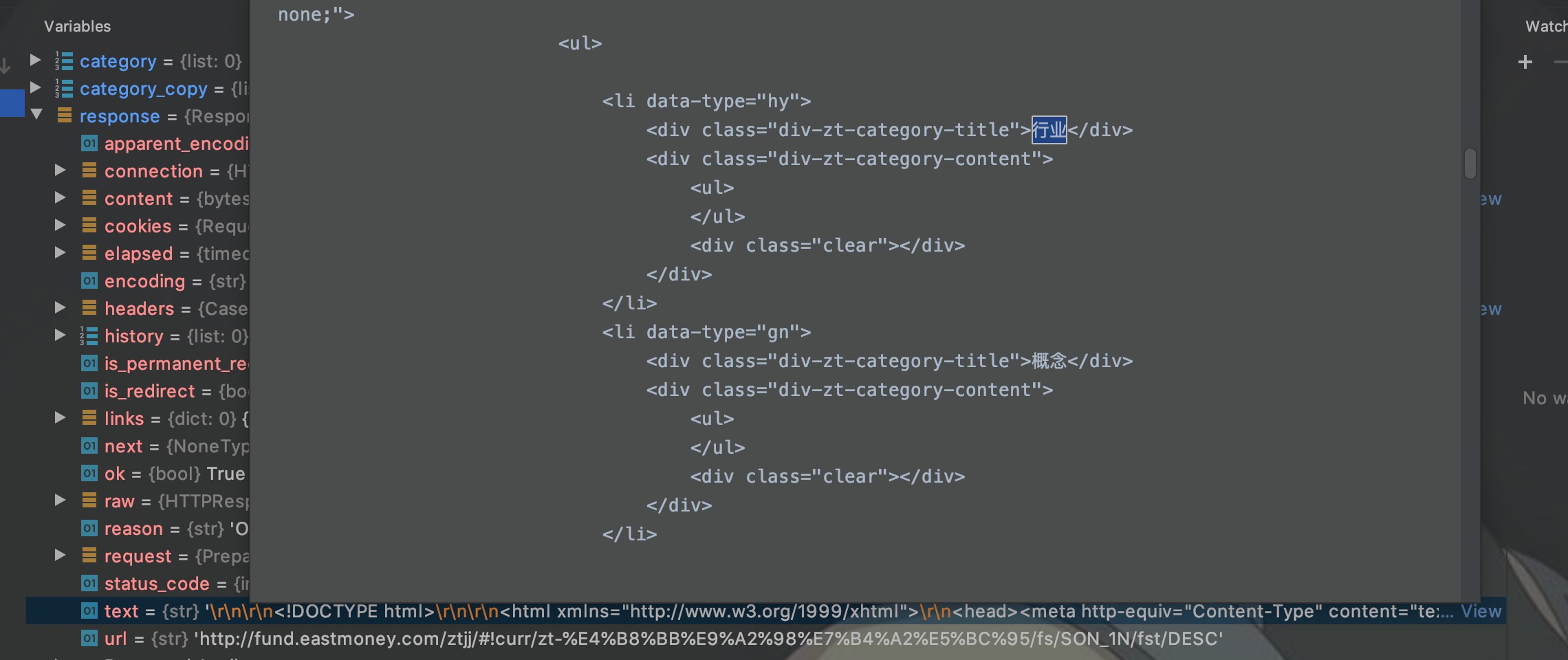
如图,爬虫请求返回的网页和从浏览器上看到的网页元素不一样,行业分类内容没了!!刚接触爬虫的可能还在疑问为什么,开发过爬虫的已经开始抢答了:

嗯,什么是动态加载? 这里我就用我自己的理解说一下。
动态加载
我们用浏览器访问一个网页的时候,后台返回给浏览器html网页、js、css等文件。浏览器内核(也称渲染引擎)在加载网页的同时,也会执行html中的js渲染网页,然后将渲染后的网页展示在浏览器上,即浏览器上的网页内容是:原始HTML + 浏览器js渲染的结果。
js将数据渲染到网页的过程方式就是动态加载。那么,数据从哪来?
你输入url请求网站时,其实js中定义的方法也偷偷地帮你发起了请求。最常见的是网页上有一数据展示的部分,当我们点击下一页时,页面没有进行跳转,只有展示数据部分刷新,这个就是ajax实现的局部刷新功能,也是最常见的动态加载之一。讲讲大致原理。
前端开发者在js中对下一页按钮添加了点击监听事件。点击按钮时,进入相应js函数,在函数中使用ajax对后台url进行请求,返回json或者其他格式的数据,然后选中数据展示区的html元素,清除其中已有的数据,插入新获取的数据,就实现了数据刷新而不需要网页跳转的功能,也称为异步请求、局部刷新。当然很多网站在网页加载时,就使用ajax来获取数据进行渲染。
但是爬虫程序他没有渲染引擎啊,无法执行js,所以只能呆呆地获取后台返回的原始html。我们在浏览器中看到的网页源码,才是没有经过js渲染的网页,也是我们爬虫最终获取的网页内容。
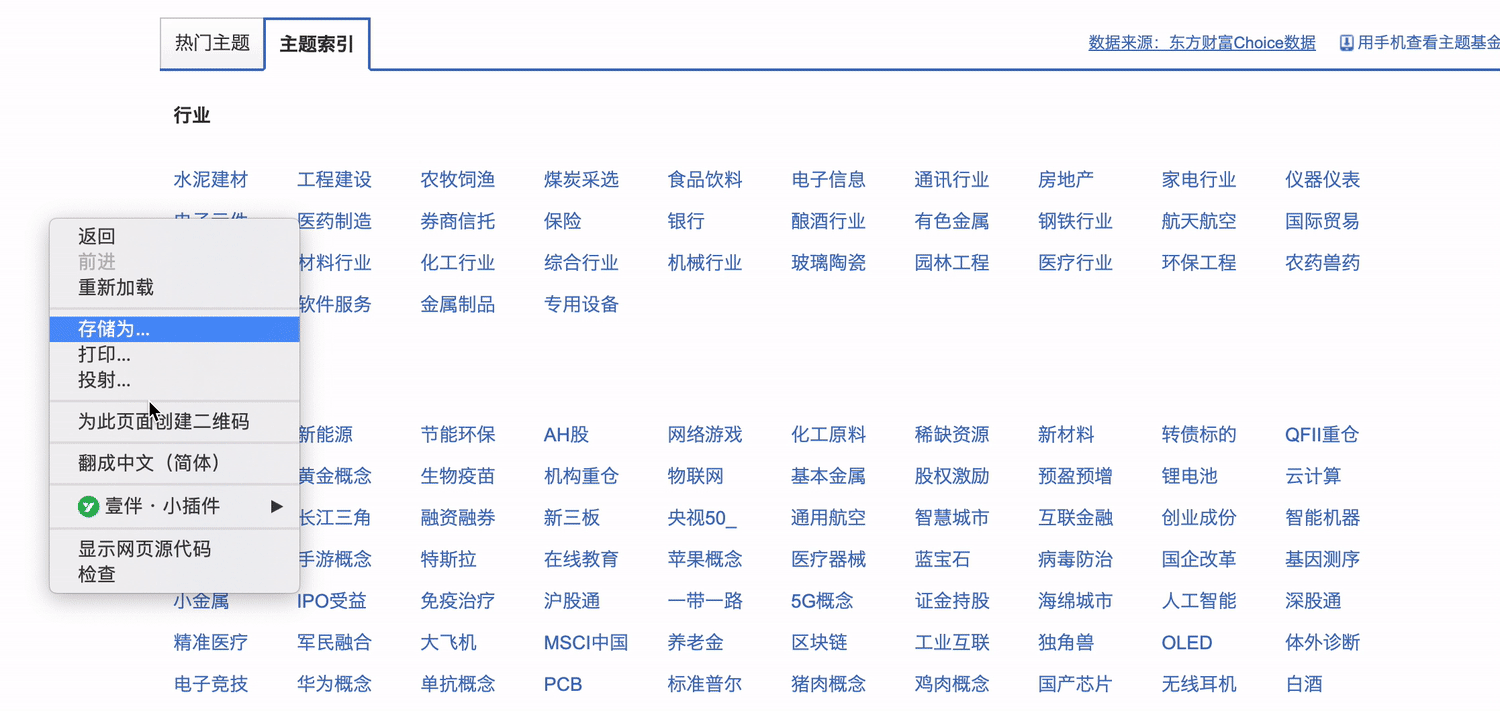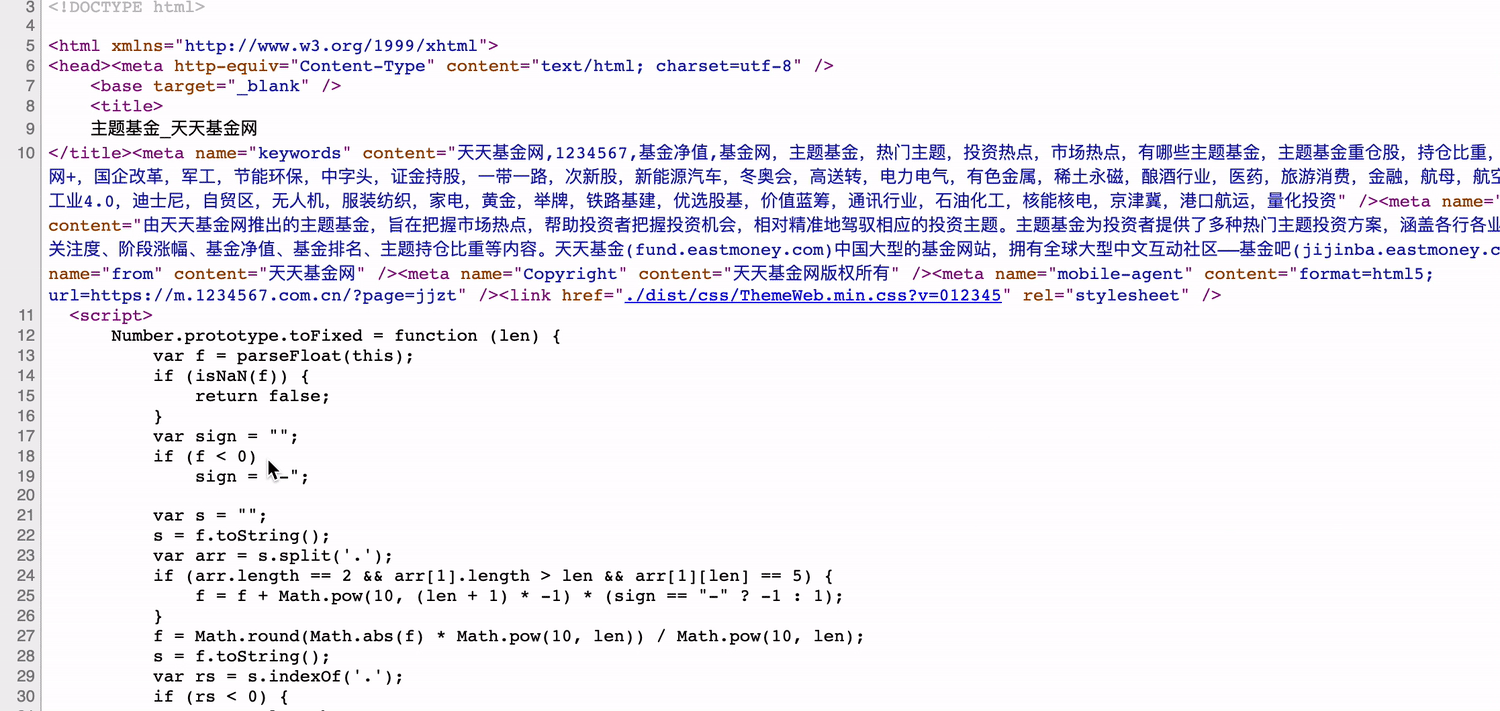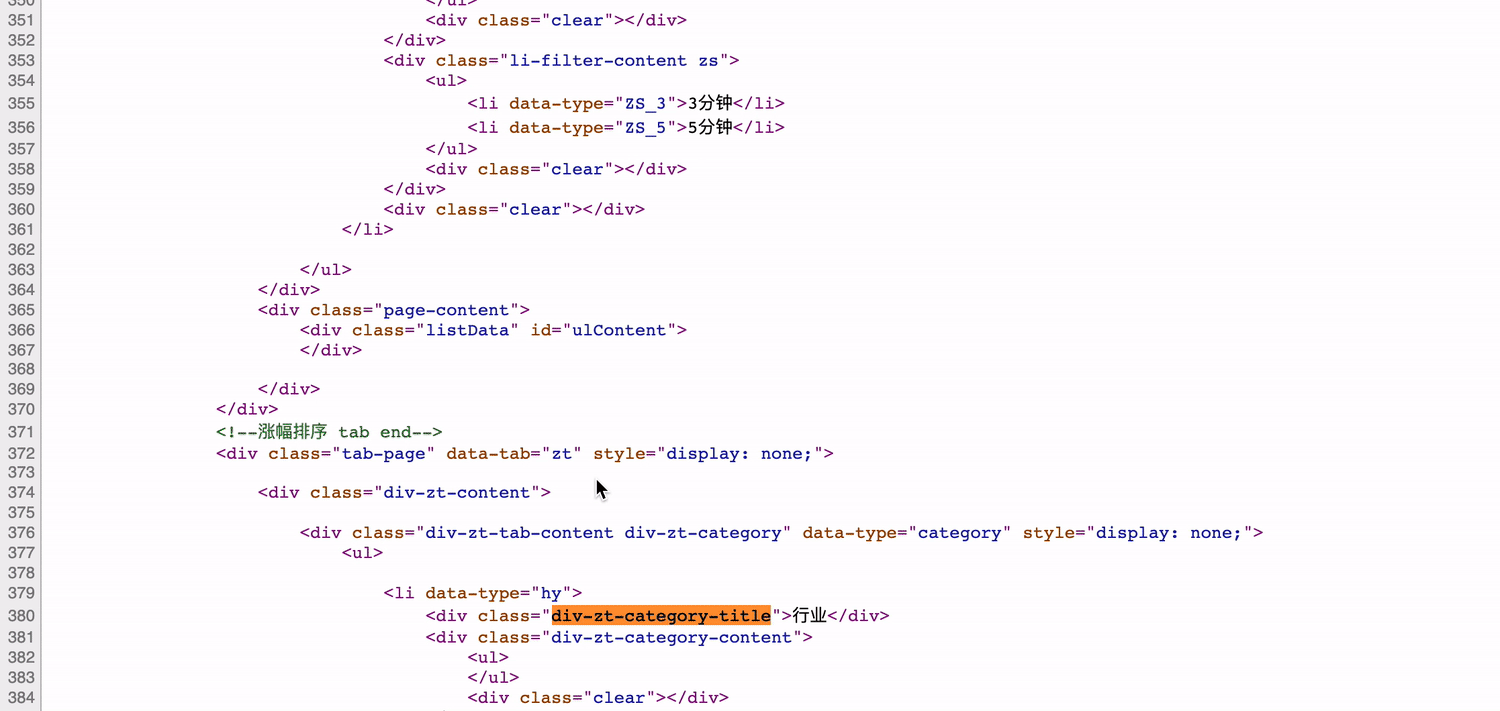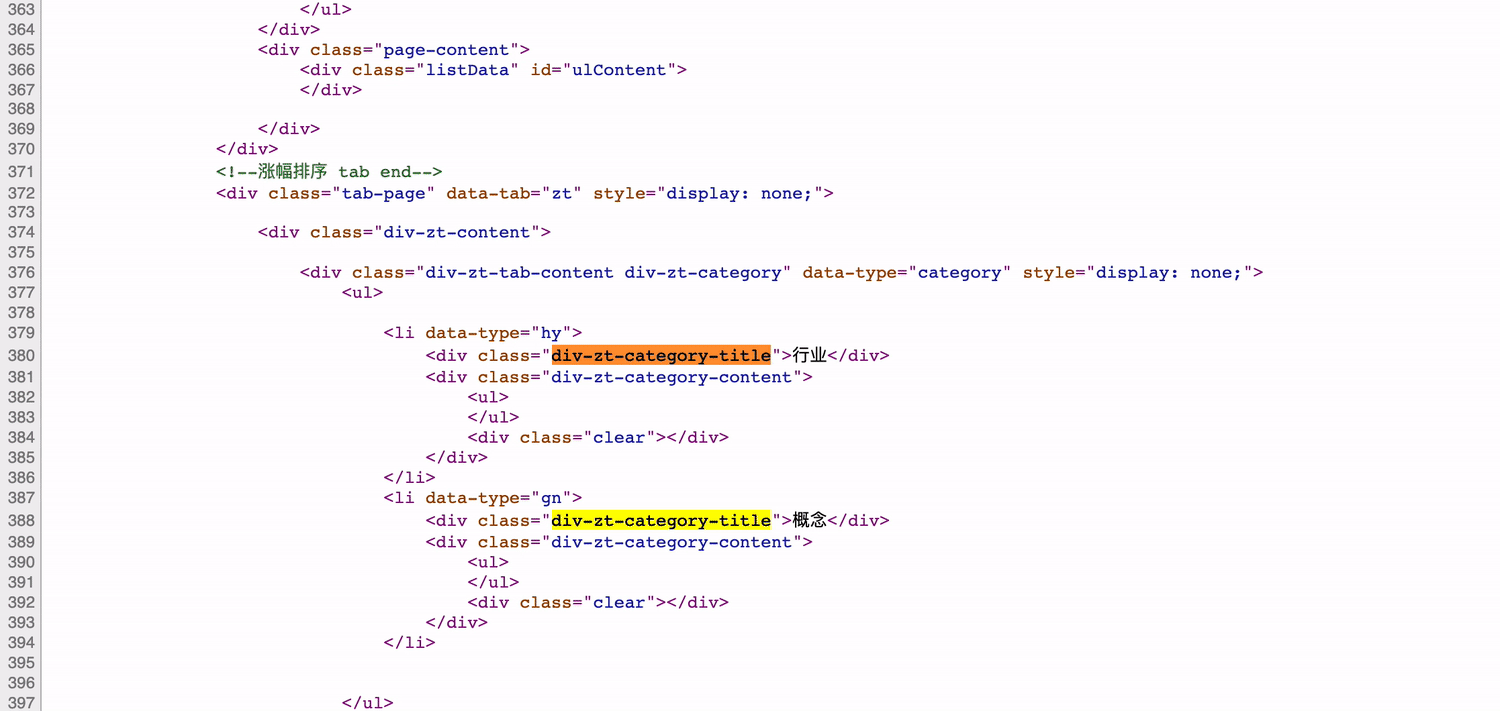
如图,网页源码中也没有分类元素。至此,我们可以得出结论:开发者工具看到的是js渲染后的html,网页源码是原始的html。
这时候你应该有所考虑:我们解析网页是为了什么?获取数据!但网页中没有数据,所以我们就不需要请求这个网页的url了。我们只要找到js获取数据的url,直接请求这个url,数据不直接就有了么。
正常情况下,如何应对动态加载?
找接口的url
在我看来,使用动态加载网页获取数据比普通网页简单的多,使用加密参数的除外。我们可以直接从接口获取json或者其他文本格式的数据,而不需要解析网页。我们的爬虫开发也直接从面向网页变成了面向数据。我们首先要做的就是找接口的url。
如何找到接口url?
- 打开开发者工具,刷新页面,搜索关键字
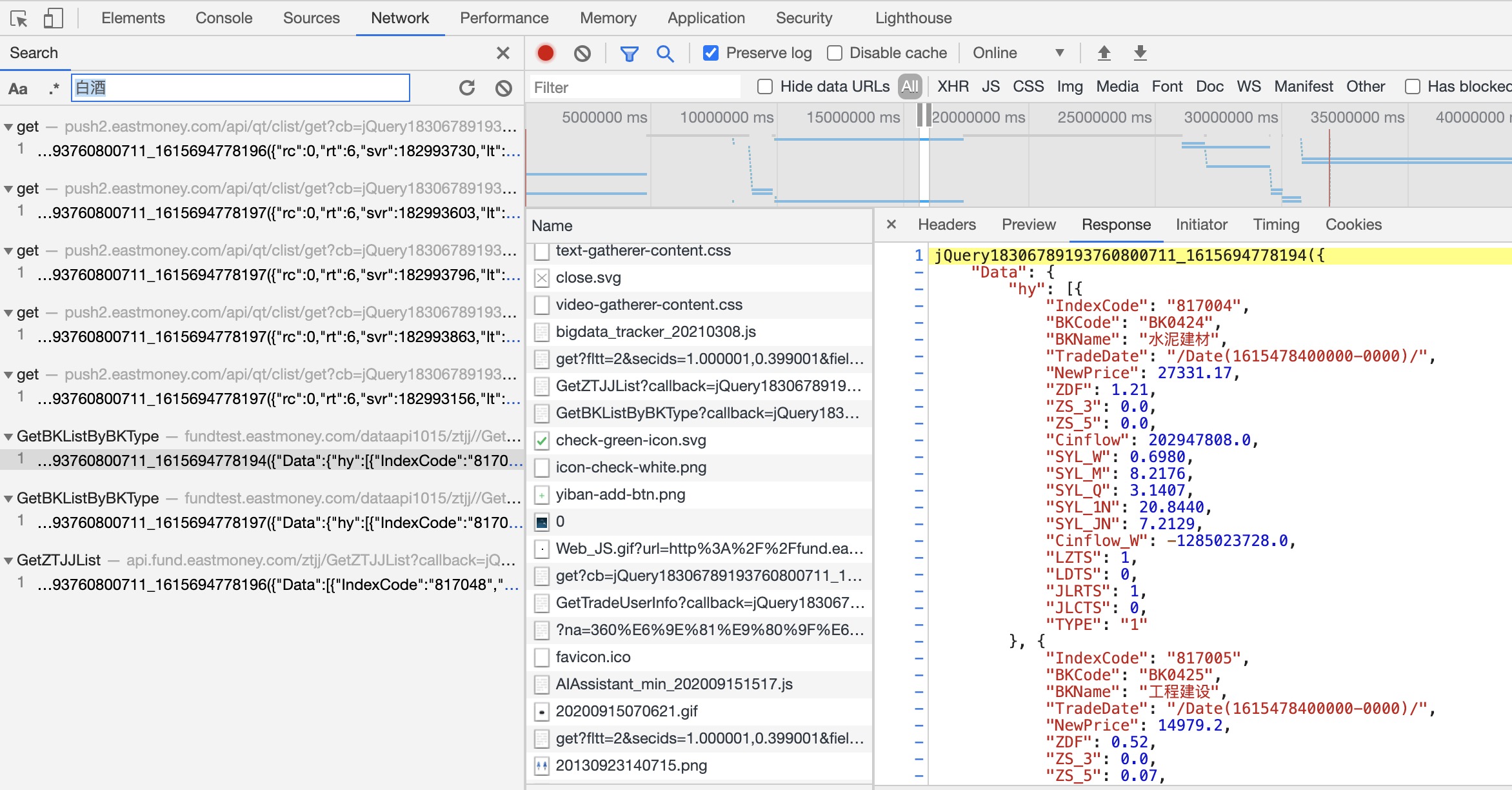
根据返回数据中的关键字搜索,如图,我们根据"白酒"找到了对应的响应内容。这里先看看返回的内容,这里记住BKCode和Bkname两个字段。
- 查看url,构造参数
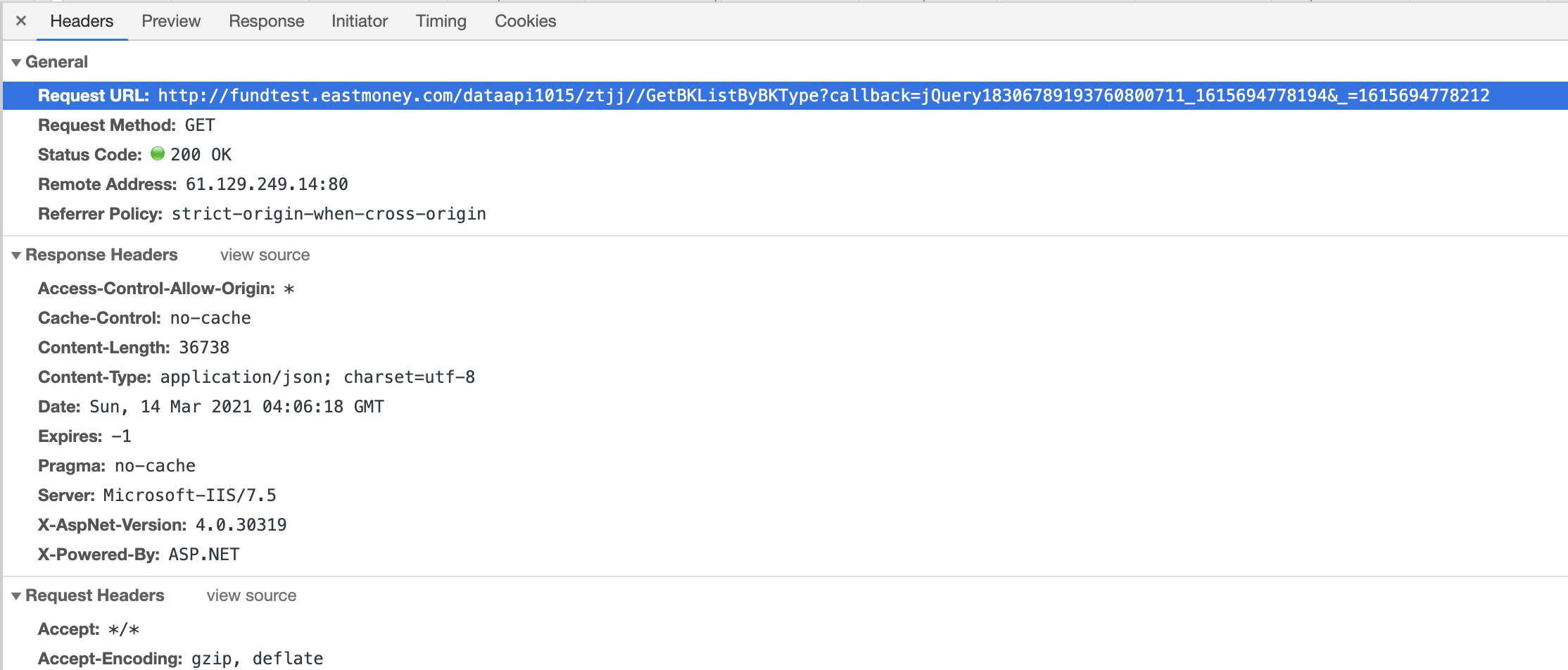
我们来查看此响应的请求。如图,我们找到了url,并且有两个请求参数。
根据请求和响应来看,这个是一个JSONP的请求。这类请求的规律是:url中的callback由一个方法名+时间戳组成,_参数也是一个时间戳;响应内容格式为callback(json)。如果用兴趣可以去了解一下JSONP,如果单纯获取数据只要了解他的规律即可。
第二层:解析列表页
-
我们点击进入"电子信息"的基金列表页,如图
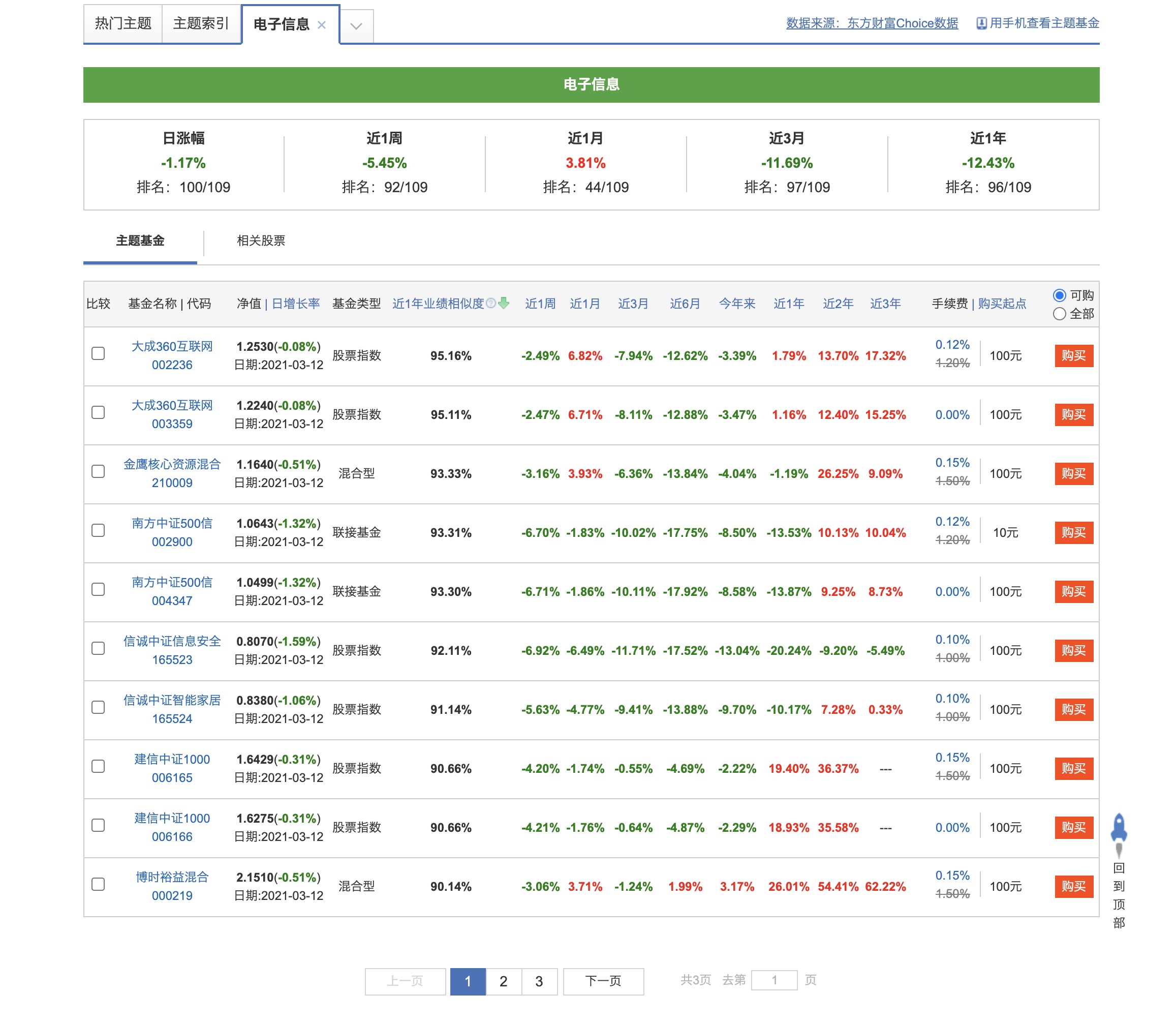
-
按照分类页面请求的方法,你会发现这个也是一个jsonp接口返回的数据,同样,来寻找接口url。
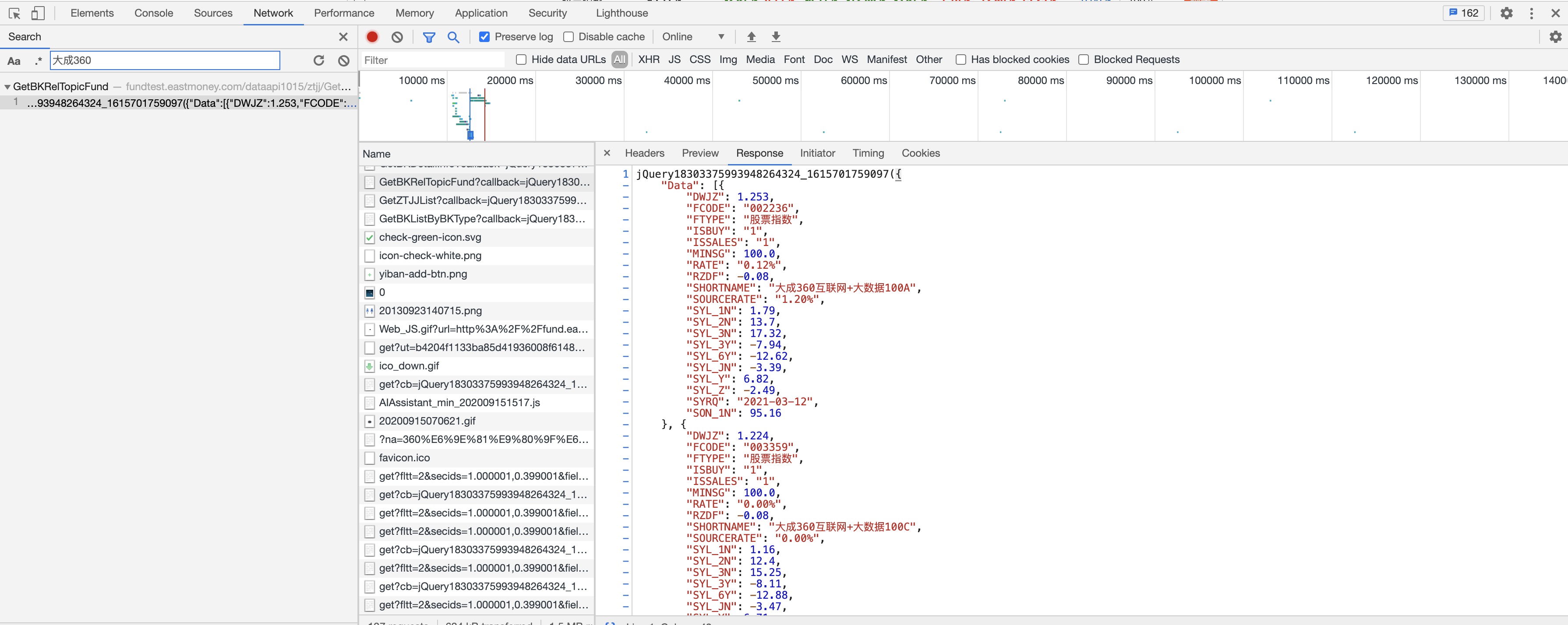
这里主要关注FCODE字段。从列表页发现,一页是十个基金,需要翻页,所以在响应数据中末尾有TotalCount字段,用这个可以来计算一共有多少页。

- 查看请求参数
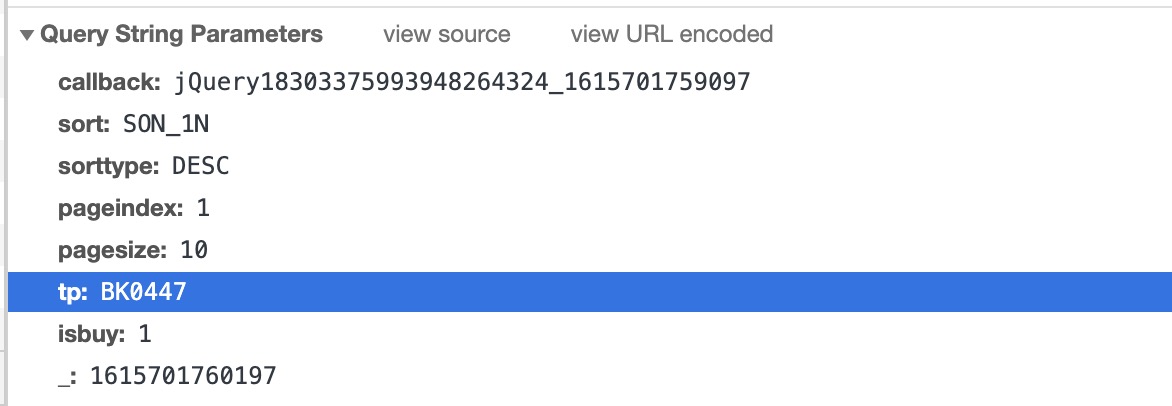
这里的tp字段就是BKCode,pageIndex传入当前请求的页数。
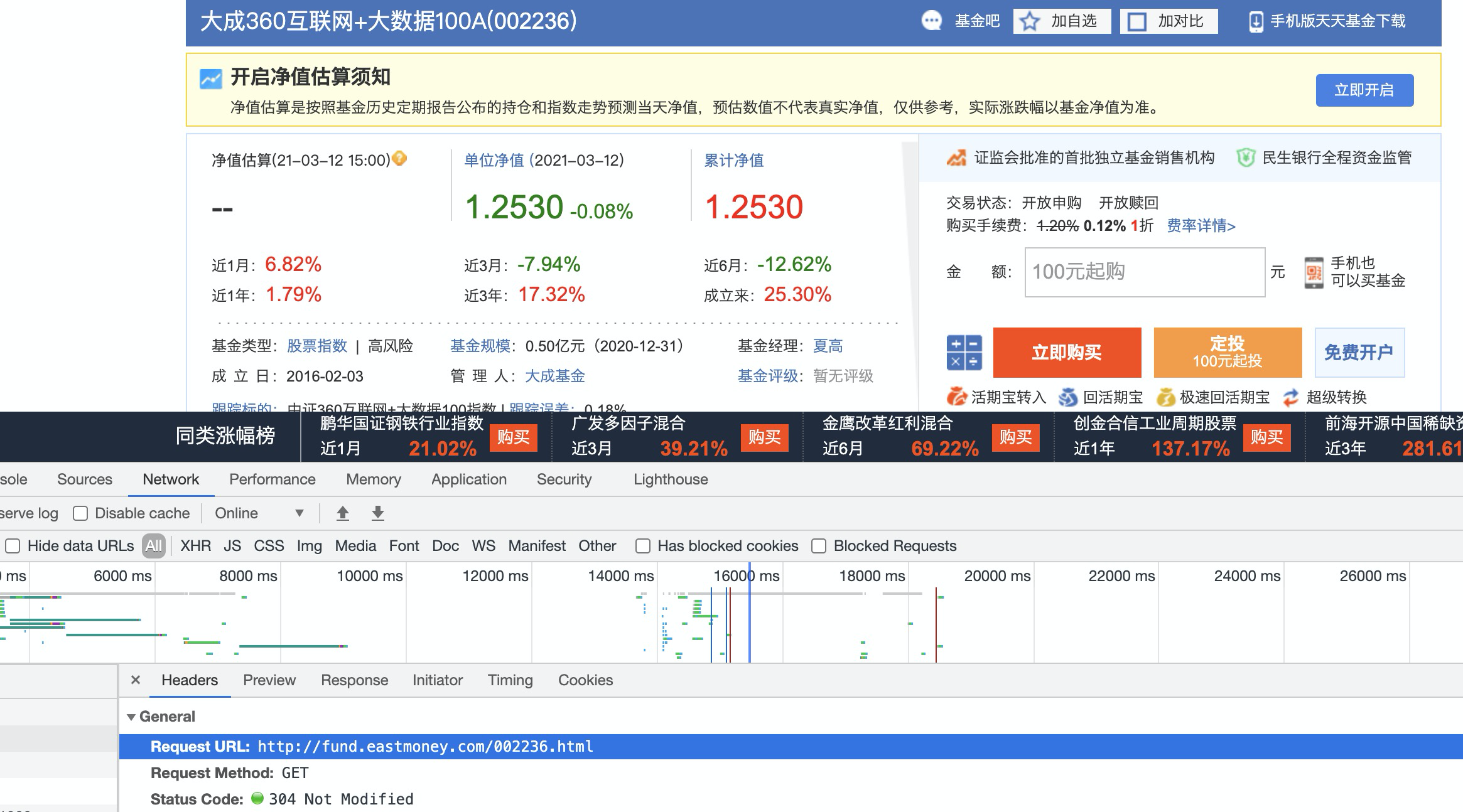
第三层:解析详情页
进入一个基金详情页,你会发现这个页面就是传统的静态页面,使用css或者xpath直接解析即可。通过url你会发现,从列表页是通过Fcode字段来跳转到每个基金的详情页。
程序开发
从上面的分析来看,分类页和列表页是动态加载,返回内容是类似于json的jsonp文本,我们可以去掉多余的部分,直接用json解析。详情页是静态页面,用xpath即可。
代码开发
import requests
import time
import datetime
import json
import pymysql
from lxml.html import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Safari/605.1.15'
, 'Referer': 'http://fund.eastmoney.com'
}
# 初始化数据库连接
connection = pymysql.connect(host='47.102.***.**', user='root', password='root', database='scrapy', port=3306, charset='utf8')
cursor = connection.cursor()
# 程序入口, 解析基金分类
def start_requests():
timestamp = int(time.time() * 1000)
callback = 'jQuery18306789193760800711_' + str(timestamp)
start_url = f'http://fundtest.eastmoney.com/dataapi1015/ztjj//GetBKListByBKType?callback={callback}&_={timestamp}'
response = requests.get(start_url, headers=headers)
# 将分类返回的数据掐头去尾,格式化成json
result = response.text.replace(callback, '')
result = result[1: result.rfind(')')]
data = json.loads(result)
# 遍历行业分类数据,获取名称和代号
for item in data['Data']['hy'] :
time.sleep(3)
code = item['BKCode']
category = item['BKName']
print(code, category)
parseFundList(code, category)
# 遍历概念分类数据
for item in data['Data']['gn']:
time.sleep(3)
code = item['BKCode']
category = item['BKName']
print(code, category)
parseFundList(code, category)
# 解析每个分类下的基金列表
def parseFundList(code, category):
timestamp = int(time.time() * 1000)
callback = 'jQuery1830316287740290561061_' + str(timestamp)
index = 1
url = f'http://fundtest.eastmoney.com/dataapi1015/ztjj/GetBKRelTopicFund?callback={callback}&sort=SON_1N&sorttype=DESC&pageindex={index}&pagesize=10&tp={code}&isbuy=1&_={timestamp}'
response = requests.get(url, headers=headers)
result = response.text.replace(callback, '')
result = result[1: result.rfind(')')]
data = json.loads(result)
totalCount = data['TotalCount']
# 先根据totalCount计算出总页数
pages = int(int(totalCount) / 10) + 1
# 解析出每页基金的FCode
for index in range(1, pages + 1):
timestamp = int(time.time() * 1000)
callback = 'jQuery1830316287740290561061_' + str(timestamp)
url = f'http://fundtest.eastmoney.com/dataapi1015/ztjj/GetBKRelTopicFund?callback={callback}&sort=SON_1N&sorttype=DESC&pageindex={index}&pagesize=10&tp={code}&isbuy=1&_={timestamp}'
response = requests.get(url, headers=headers)
result = response.text.replace(callback, '')
result = result[1: result.rfind(')')]
data = json.loads(result)
for item in data['Data']:
time.sleep(3)
fundCode = item['FCODE']
fundName = item['SHORTNAME']
parse_info(fundCode, fundName, category)
def parse_info(fundCode, fundName, category):
url = f'http://fund.eastmoney.com/{fundCode}.html'
response = requests.get(url, headers=headers)
content = response.text.encode('ISO-8859-1').decode('UTF-8')
html = etree.HTML(content)
worth = html.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dd[1]/span[1]/text()')
if worth:
worth = worth[0]
else:
worth = 0
scope = html.xpath('//div[@class="infoOfFund"]/table/tr[1]/td[2]/text()')[0].replace(':', '')
manager = html.xpath('//div[@class="infoOfFund"]/table/tr[1]/td[3]/a/text()')[0]
create_time = html.xpath('//div[@class="infoOfFund"]/table/tr[2]/td[1]/text()')[0].replace(':', '')
company = html.xpath('//div[@class="infoOfFund"]/table/tr[2]/td[2]/a/text()')[0]
level = html.xpath('//div[@class="infoOfFund"]/table/tr[2]/td[3]/div/text()')
if level:
level = level[0]
else:
level = '暂无评级'
month_1 = html.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[1]/dd[2]/span[2]/text()')
month_3 = html.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dd[2]/span[2]/text()')
month_6 = html.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[3]/dd[2]/span[2]/text()')
if month_1:
month_1 = month_1[0]
else:
month_1 = ''
if month_3:
month_3 = month_3[0]
else:
month_3 = ''
if month_6:
month_6 = month_6[0]
else:
month_6 = ''
print(fundName, fundCode, category, worth, scope, manager, create_time, company, level, month_1, month_3, month_6, sep='|')
# 存储到mysql
today = datetime.date.today()
sql = f"insert into fund_info values('{today}', '{fundName}', '{fundCode}', '{category}', '{worth}', '{scope}', '{manager}', '{create_time}', '{company}', '{level}', '{month_1}', '{month_3}', '{month_6}')"
cursor.execute(sql)
connection.commit()
# 开始爬取
start_requests()
声明: 以上代码仅限于学习使用,不得使用该程序对网站恶意请求造成破坏,否则后果自负。
程序如上,在解析动态加载的数据的时候明显比解析网页显简单,因为数据字段规范,根本不用考虑字段缺失的问题,而解析网页就会有各种各样的情况出现。
其次,程序还有很多可以优化的部分。例如
- 可以将冗余代码重构成一个方法,这里为了直观都是逐行写的。
- 可以针对详情页不同结构多设置几种解析方式。
- 对详情页每个字段进行if为空的判断,然后设置缺省值,我这里只判断了三四个字段。
数据库建表
CREATE TABLE `fund_info` (
`op_time` varchar(20) DEFAULT NULL,
`fundName` varchar(20) DEFAULT NULL,
`fundCode` varchar(20) DEFAULT NULL,
`category` varchar(20) DEFAULT NULL,
`worth` varchar(20) DEFAULT NULL,
`scope` varchar(20) DEFAULT NULL,
`manager` varchar(20) DEFAULT NULL,
`create_time` varchar(20) DEFAULT NULL,
`company` varchar(20) DEFAULT NULL,
`level` varchar(20) DEFAULT NULL,
`month_1` varchar(20) DEFAULT NULL,
`month_3` varchar(20) DEFAULT NULL,
`month_6` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
运行结果
控制台输出:

数据库查询:

结语
3月6日确定题目开始着手写,写完已经是3月14日。也深刻体会到开发容易描述不易。本篇文章从分析网站、到开发爬虫、存储数据,以及穿插了部分动态加载的知识,全方面的讲述了一个爬虫开发的全过程,希望对你有所启示。期待下一次相遇。
写的都是日常工作中的亲身实践,置身自己的角度从0写到1,保证能够真正让大家看懂。
文章会在公众号 [入门到放弃之路] 首发,期待你的关注。
