在向某一个数据库中插入表的时候,应该在项目下面的models里边写入:
class book(models,Model): #book代指的是表名
id=models.AutoField(primary_key=True) #id这样的代指的一个字段
ORM:
1,类名----------》表名
2,类属性--------》字段类型
3,类对象--------》表记录
表与表的关系:
一对一
多对一
多对多
如果想让输入IP进入某个页面的话,对应的的URL应该这么写:
url(r'^$',views.index)
重定向请求的地址和重定向的地址不能是同一个地址。
1对多的时候:
必须将关联字段放在多的表中
foreign key dep_id(外间名称) reference dep(id(关联的哪个名称))
多对多的时候:
创建第三张表
create table student_teacher(
id int primary key,
student_id int,
teacher_id int,
foreign key student_id(外间名称) reference student(id(关联的哪个名称))
foreign key teacher_id(外间名称) reference teacher(id(关联的哪个名称))
)
一对一的时候:
两张表是平等的,
foreign key,关联字段可以放在两张表中任意一张
关联字段必须唯一约束
在models.py创建外键的时候,一般是这样的写法:
例子:publisher=models.ForeignKey(to="Publish")
这里的Publisher代指的是关联的另外一张表
数据化迁移:python manage.py makemigrations
当做完了数据化迁移以后,我们可以在生成的过渡脚本中看到执行过程。
脚本一般以initial.py结尾。
python manage.py migrate
怎么在pycharm中改成连接数据库:
settings中要更改一个地方:
将原有的DATABASES设置注释掉,然后添加上如下内容:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'books', #你的数据库名称
'USER': 'root', #你的数据库用户名
'PASSWORD': '', #你的数据库密码
'HOST': '', #你的数据库主机,留空默认为localhost
'PORT': '3306', #你的数据库端口
}
}
数据库需要提前创建好的。
直接数据化迁移的话可能会报错,需要安装组件:pymysql
数据库引擎更改MysqlDB-----》pymysql,如何去更改呢:
在应用的 __init__文件中加入:
import pymysql pymysql.install_as_MySQLdb()
然后在执行数据化迁移
数据库的插入方法:
插入方法一:
creat有返回值,插入的对象有记录 models.book(表名).objects.create(title=title) 插入方法二: book_obj=models.book(表名)(title=title) book_obj.sava()
模板语法:
变量{{}}
深度查询:句点符 .
过滤器: {{var | filter_name:参数}}
标签:
{% url %}
for循环: {% for i in obj %} {% endfor %}
if标签: {% if 判断 %}
执行的操作,eg: <p>大于20</p>
{% else %}
执行的操作
{% endif %}
with标签:
{% with 条件 %}
<p>{{ name }}</p>
{% endwith %}
csrf_token标签:用在form表单中,在向服务器请求数据时,可以得到一个对应的键值。当提交时,检验是否这个键值正确,正确的话才允许。
防止有人直接登录到对应页面,修改数据往上传。
for标签带有一个可选的{% empty %}从句,以便在给出的组是空的或者没有被找到时,可以有所操作。
{% for person in persion_list %}
执行语句
{% empty %}
执行语句
{% endfor %}
自定义标签和过滤器:
1,在settings中的INSTALLED-APPS中篇配置当前app,不然django无法找到自己定义的过滤器。 2,在应用中穿件templatetags模块(模块的名字只能是templatetags) 3,创建任意.py 文件
前几行的内容都是一样的
from django import template
form django.utils.safestring import mark_safe
register = template.Library() #register的名字是固定的,不可改变
@register.filter
def mult(x,y): #自定义函数(过滤器)
return x*y
@register.simple_tag
def mult_tag(x,y): #自定义标签
return x*y
在引用的时候,需要在开头加上{% load Mytag %}
总结区别:
1,自定义的filter只能接收两个参数
2,自定义的simple_tag不能与if使用
模板语言之继承:
在网页写的过程中可能遇到大量重复的代码:
这样的话我们可以再templates中写一个模板,当哪块需要引用的时候,我从那调用就可以了
比如说在templates中写了一个base.html,
共用的部分保留,然后在想要改变的地方加入
{% block content %}
{% endblock %}
然后哪个页面想用共用的页面,就在文件的开头写入:
{% extends "base.html" %}
如果想修改其中的一部分,可在想修改的那:
{% block title %}修改的{% endblock %}
{% block content %}修改的{% endblock %}
ORM 的查询API:
说白了这就是数据库查询的相关知识点。
<1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
用法一般是这么用的,比如说查找价钱等于134的
book_list=models.Book.objects.filter(price=134) #这里德尔条件可以选择多个
for book_obj in book_list:
print(book_obj.title) <3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个, 如果符合筛选条件的对象超过一个或者没有都会抛出错误。 <5> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 <4> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 <9> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <6> order_by(*field): 对查询结果排序 <7> reverse(): 对查询结果反向排序 <8> distinct(): 从返回结果中剔除重复纪录 <10> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 <11> first(): 返回第一条记录 <12> last(): 返回最后一条记录 <13> exists(): 如果QuerySet包含数据,就返回True,否则返回False
以后再执行models,对应的sql语句就会执行出来:
将这段文字加到settings里边:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
一对多添加数据方法补充:
1,先在models里边添加两个class
一定要确认好关联字段在哪个里边,eg:
publisher=models.ForeignKey(to="Publish") #(to="Publish")是关联到哪个表中
2,然后在views.py里边写对应的函数
# 一对多 添加数据 方式1
# publish_obj=models.Publish.objects.get(name="renmin")
# book_obj=models.Book.objects.create(title="python",price=122,pubDate="2012-12-12",publisher=publish_obj)
# 一对多 添加数据 方式2
book_obj=models.Book.objects.create(title=titles,price=price,pubDate=pubdate,publisher_id=publish_id) print(book_obj.title)
当数据库内的数据添加以后,怎么动态的取到修改的数据:
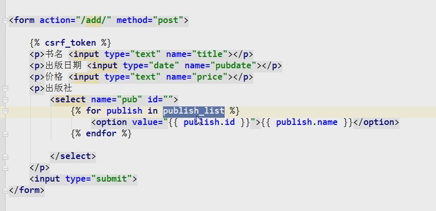
添加表记录:
普通字段:
方式1 publish_obj=Publish(name="人民出版社",city="北京",email="renMin@163.com") publish_obj.save() # 将数据保存到数据库 方式2 返回值publish_obj是添加的记录对象 publish_obj=Publish.objects.create(name="人民出版社",city="北京",email="renMin@163.com")方式3<br>表.objects.create(**request.POST.dict())
外键字段:
方式1: publish_obj=Publish.objects.get(nid=1) Book.objects.create(title="金瓶眉",publishDate="2012-12-12",price=665,pageNum=334,publish=publish_obj) 方式2: Book.objects.create(title="金瓶眉",publishDate="2012-12-12",price=665,pageNum=334,publish_id=1)
多对多字段:
book_obj=Book.objects.create(title="追风筝的人",publishDate="2012-11-12",price=69,pageNum=314,publish_id=1) author_yuan=Author.objects.create(name="yuan",age=23,authorDetail_id=1) author_egon=Author.objects.create(name="egon",age=32,authorDetail_id=2) book_obj.authors.add(author_egon,author_yuan) # 将某个特定的 model 对象添加到被关联对象集合中。 ======= book_obj.authors.add(*[]) book_obj.authors.create() #创建并保存一个新对象,然后将这个对象加被关联对象的集合中,然后返回这个新对象。