监督学习主要为回归问题与分类问题
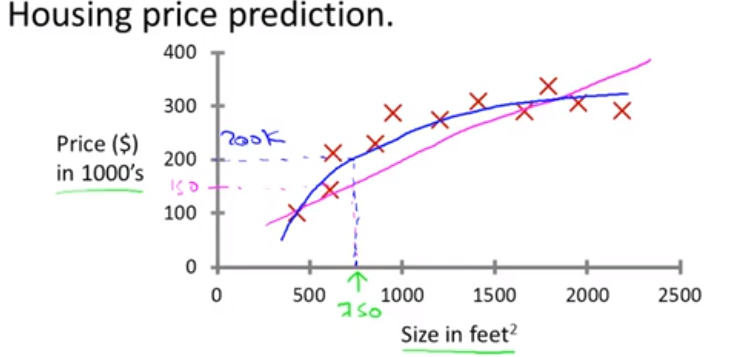
回归问题是针对于连续型变量 简单讲就是拟合出适当的函数模型y=f(x)来表示已存在的数据点,来使得给定一个新x,预测y。 例如:
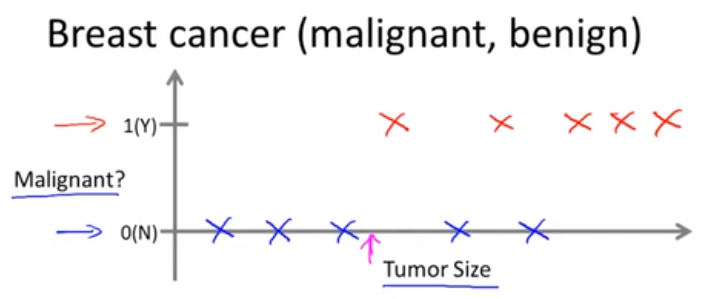
分类是针对离散型数据集 即,是与不是,或者说输出的结果是有限的 例如:
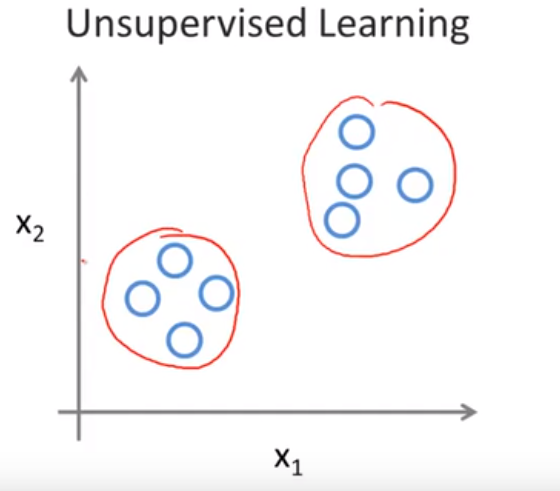
无监督学习更像是让机器自学,我们不知道数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据之间的关系。 简单讲就像是会自动根据特征分类 例如: